
diff options
| author | CoprDistGit <infra@openeuler.org> | 2023-04-11 03:45:15 +0000 |
|---|---|---|
| committer | CoprDistGit <infra@openeuler.org> | 2023-04-11 03:45:15 +0000 |
| commit | a11d285c95130d55f2a95f305e8ba2073b3d3c6f (patch) | |
| tree | 06a1031743a445372e2fc74c0b314dd5819568d9 | |
| parent | f46d37cf7e100a944e85453a7bc5f4ede38c4142 (diff) | |
automatic import of python-keras-self-attention
| -rw-r--r-- | .gitignore | 1 | ||||
| -rw-r--r-- | python-keras-self-attention.spec | 477 | ||||
| -rw-r--r-- | sources | 1 |
3 files changed, 479 insertions, 0 deletions
@@ -0,0 +1 @@ +/keras-self-attention-0.51.0.tar.gz diff --git a/python-keras-self-attention.spec b/python-keras-self-attention.spec new file mode 100644 index 0000000..45836f4 --- /dev/null +++ b/python-keras-self-attention.spec @@ -0,0 +1,477 @@ +%global _empty_manifest_terminate_build 0 +Name: python-keras-self-attention +Version: 0.51.0 +Release: 1 +Summary: Attention mechanism for processing sequential data that considers the context for each timestamp +License: MIT +URL: https://github.com/CyberZHG/keras-self-attention +Source0: https://mirrors.nju.edu.cn/pypi/web/packages/d5/a5/0a1d003e420da49791f64def11d8d2837280e1a680c2eaaab216f9f17ed7/keras-self-attention-0.51.0.tar.gz +BuildArch: noarch + + +%description +# Keras Self-Attention + +[](https://pypi.org/project/keras-self-attention/) + + +\[[中文](https://github.com/CyberZHG/keras-self-attention/blob/master/README.zh-CN.md)|[English](https://github.com/CyberZHG/keras-self-attention/blob/master/README.md)\] + +Attention mechanism for processing sequential data that considers the context for each timestamp. + +*  +* 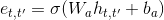 +*  +*  + +## Install + +```bash +pip install keras-self-attention +``` + +## Usage + +### Basic + +By default, the attention layer uses additive attention and considers the whole context while calculating the relevance. The following code creates an attention layer that follows the equations in the first section (`attention_activation` is the activation function of `e_{t, t'}`): + +```python +import keras +from keras_self_attention import SeqSelfAttention + + +model = keras.models.Sequential() +model.add(keras.layers.Embedding(input_dim=10000, + output_dim=300, + mask_zero=True)) +model.add(keras.layers.Bidirectional(keras.layers.LSTM(units=128, + return_sequences=True))) +model.add(SeqSelfAttention(attention_activation='sigmoid')) +model.add(keras.layers.Dense(units=5)) +model.compile( + optimizer='adam', + loss='categorical_crossentropy', + metrics=['categorical_accuracy'], +) +model.summary() +``` + +### Local Attention + +The global context may be too broad for one piece of data. The parameter `attention_width` controls the width of the local context: + +```python +from keras_self_attention import SeqSelfAttention + +SeqSelfAttention( + attention_width=15, + attention_activation='sigmoid', + name='Attention', +) +``` + +### Multiplicative Attention + +You can use multiplicative attention by setting `attention_type`: + + + +```python +from keras_self_attention import SeqSelfAttention + +SeqSelfAttention( + attention_width=15, + attention_type=SeqSelfAttention.ATTENTION_TYPE_MUL, + attention_activation=None, + kernel_regularizer=keras.regularizers.l2(1e-6), + use_attention_bias=False, + name='Attention', +) +``` + +### Regularizer + + + +To use the regularizer, set `attention_regularizer_weight` to a positive number: + +```python +import keras +from keras_self_attention import SeqSelfAttention + +inputs = keras.layers.Input(shape=(None,)) +embd = keras.layers.Embedding(input_dim=32, + output_dim=16, + mask_zero=True)(inputs) +lstm = keras.layers.Bidirectional(keras.layers.LSTM(units=16, + return_sequences=True))(embd) +att = SeqSelfAttention(attention_type=SeqSelfAttention.ATTENTION_TYPE_MUL, + kernel_regularizer=keras.regularizers.l2(1e-4), + bias_regularizer=keras.regularizers.l1(1e-4), + attention_regularizer_weight=1e-4, + name='Attention')(lstm) +dense = keras.layers.Dense(units=5, name='Dense')(att) +model = keras.models.Model(inputs=inputs, outputs=[dense]) +model.compile( + optimizer='adam', + loss={'Dense': 'sparse_categorical_crossentropy'}, + metrics={'Dense': 'categorical_accuracy'}, +) +model.summary(line_length=100) +``` + +### Load the Model + +Make sure to add `SeqSelfAttention` to custom objects: + +```python +import keras + +keras.models.load_model(model_path, custom_objects=SeqSelfAttention.get_custom_objects()) +``` + +### History Only + +Set `history_only` to `True` when only historical data could be used: + +```python +SeqSelfAttention( + attention_width=3, + history_only=True, + name='Attention', +) +``` + +### Multi-Head + +Please refer to [keras-multi-head](https://github.com/CyberZHG/keras-multi-head). + +%package -n python3-keras-self-attention +Summary: Attention mechanism for processing sequential data that considers the context for each timestamp +Provides: python-keras-self-attention +BuildRequires: python3-devel +BuildRequires: python3-setuptools +BuildRequires: python3-pip +%description -n python3-keras-self-attention +# Keras Self-Attention + +[](https://pypi.org/project/keras-self-attention/) + + +\[[中文](https://github.com/CyberZHG/keras-self-attention/blob/master/README.zh-CN.md)|[English](https://github.com/CyberZHG/keras-self-attention/blob/master/README.md)\] + +Attention mechanism for processing sequential data that considers the context for each timestamp. + +*  +* 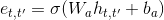 +*  +*  + +## Install + +```bash +pip install keras-self-attention +``` + +## Usage + +### Basic + +By default, the attention layer uses additive attention and considers the whole context while calculating the relevance. The following code creates an attention layer that follows the equations in the first section (`attention_activation` is the activation function of `e_{t, t'}`): + +```python +import keras +from keras_self_attention import SeqSelfAttention + + +model = keras.models.Sequential() +model.add(keras.layers.Embedding(input_dim=10000, + output_dim=300, + mask_zero=True)) +model.add(keras.layers.Bidirectional(keras.layers.LSTM(units=128, + return_sequences=True))) +model.add(SeqSelfAttention(attention_activation='sigmoid')) +model.add(keras.layers.Dense(units=5)) +model.compile( + optimizer='adam', + loss='categorical_crossentropy', + metrics=['categorical_accuracy'], +) +model.summary() +``` + +### Local Attention + +The global context may be too broad for one piece of data. The parameter `attention_width` controls the width of the local context: + +```python +from keras_self_attention import SeqSelfAttention + +SeqSelfAttention( + attention_width=15, + attention_activation='sigmoid', + name='Attention', +) +``` + +### Multiplicative Attention + +You can use multiplicative attention by setting `attention_type`: + + + +```python +from keras_self_attention import SeqSelfAttention + +SeqSelfAttention( + attention_width=15, + attention_type=SeqSelfAttention.ATTENTION_TYPE_MUL, + attention_activation=None, + kernel_regularizer=keras.regularizers.l2(1e-6), + use_attention_bias=False, + name='Attention', +) +``` + +### Regularizer + + + +To use the regularizer, set `attention_regularizer_weight` to a positive number: + +```python +import keras +from keras_self_attention import SeqSelfAttention + +inputs = keras.layers.Input(shape=(None,)) +embd = keras.layers.Embedding(input_dim=32, + output_dim=16, + mask_zero=True)(inputs) +lstm = keras.layers.Bidirectional(keras.layers.LSTM(units=16, + return_sequences=True))(embd) +att = SeqSelfAttention(attention_type=SeqSelfAttention.ATTENTION_TYPE_MUL, + kernel_regularizer=keras.regularizers.l2(1e-4), + bias_regularizer=keras.regularizers.l1(1e-4), + attention_regularizer_weight=1e-4, + name='Attention')(lstm) +dense = keras.layers.Dense(units=5, name='Dense')(att) +model = keras.models.Model(inputs=inputs, outputs=[dense]) +model.compile( + optimizer='adam', + loss={'Dense': 'sparse_categorical_crossentropy'}, + metrics={'Dense': 'categorical_accuracy'}, +) +model.summary(line_length=100) +``` + +### Load the Model + +Make sure to add `SeqSelfAttention` to custom objects: + +```python +import keras + +keras.models.load_model(model_path, custom_objects=SeqSelfAttention.get_custom_objects()) +``` + +### History Only + +Set `history_only` to `True` when only historical data could be used: + +```python +SeqSelfAttention( + attention_width=3, + history_only=True, + name='Attention', +) +``` + +### Multi-Head + +Please refer to [keras-multi-head](https://github.com/CyberZHG/keras-multi-head). + +%package help +Summary: Development documents and examples for keras-self-attention +Provides: python3-keras-self-attention-doc +%description help +# Keras Self-Attention + +[](https://pypi.org/project/keras-self-attention/) + + +\[[中文](https://github.com/CyberZHG/keras-self-attention/blob/master/README.zh-CN.md)|[English](https://github.com/CyberZHG/keras-self-attention/blob/master/README.md)\] + +Attention mechanism for processing sequential data that considers the context for each timestamp. + +*  +* 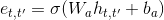 +*  +*  + +## Install + +```bash +pip install keras-self-attention +``` + +## Usage + +### Basic + +By default, the attention layer uses additive attention and considers the whole context while calculating the relevance. The following code creates an attention layer that follows the equations in the first section (`attention_activation` is the activation function of `e_{t, t'}`): + +```python +import keras +from keras_self_attention import SeqSelfAttention + + +model = keras.models.Sequential() +model.add(keras.layers.Embedding(input_dim=10000, + output_dim=300, + mask_zero=True)) +model.add(keras.layers.Bidirectional(keras.layers.LSTM(units=128, + return_sequences=True))) +model.add(SeqSelfAttention(attention_activation='sigmoid')) +model.add(keras.layers.Dense(units=5)) +model.compile( + optimizer='adam', + loss='categorical_crossentropy', + metrics=['categorical_accuracy'], +) +model.summary() +``` + +### Local Attention + +The global context may be too broad for one piece of data. The parameter `attention_width` controls the width of the local context: + +```python +from keras_self_attention import SeqSelfAttention + +SeqSelfAttention( + attention_width=15, + attention_activation='sigmoid', + name='Attention', +) +``` + +### Multiplicative Attention + +You can use multiplicative attention by setting `attention_type`: + + + +```python +from keras_self_attention import SeqSelfAttention + +SeqSelfAttention( + attention_width=15, + attention_type=SeqSelfAttention.ATTENTION_TYPE_MUL, + attention_activation=None, + kernel_regularizer=keras.regularizers.l2(1e-6), + use_attention_bias=False, + name='Attention', +) +``` + +### Regularizer + + + +To use the regularizer, set `attention_regularizer_weight` to a positive number: + +```python +import keras +from keras_self_attention import SeqSelfAttention + +inputs = keras.layers.Input(shape=(None,)) +embd = keras.layers.Embedding(input_dim=32, + output_dim=16, + mask_zero=True)(inputs) +lstm = keras.layers.Bidirectional(keras.layers.LSTM(units=16, + return_sequences=True))(embd) +att = SeqSelfAttention(attention_type=SeqSelfAttention.ATTENTION_TYPE_MUL, + kernel_regularizer=keras.regularizers.l2(1e-4), + bias_regularizer=keras.regularizers.l1(1e-4), + attention_regularizer_weight=1e-4, + name='Attention')(lstm) +dense = keras.layers.Dense(units=5, name='Dense')(att) +model = keras.models.Model(inputs=inputs, outputs=[dense]) +model.compile( + optimizer='adam', + loss={'Dense': 'sparse_categorical_crossentropy'}, + metrics={'Dense': 'categorical_accuracy'}, +) +model.summary(line_length=100) +``` + +### Load the Model + +Make sure to add `SeqSelfAttention` to custom objects: + +```python +import keras + +keras.models.load_model(model_path, custom_objects=SeqSelfAttention.get_custom_objects()) +``` + +### History Only + +Set `history_only` to `True` when only historical data could be used: + +```python +SeqSelfAttention( + attention_width=3, + history_only=True, + name='Attention', +) +``` + +### Multi-Head + +Please refer to [keras-multi-head](https://github.com/CyberZHG/keras-multi-head). + +%prep +%autosetup -n keras-self-attention-0.51.0 + +%build +%py3_build + +%install +%py3_install +install -d -m755 %{buildroot}/%{_pkgdocdir} +if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi +if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi +if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi +if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi +pushd %{buildroot} +if [ -d usr/lib ]; then + find usr/lib -type f -printf "/%h/%f\n" >> filelist.lst +fi +if [ -d usr/lib64 ]; then + find usr/lib64 -type f -printf "/%h/%f\n" >> filelist.lst +fi +if [ -d usr/bin ]; then + find usr/bin -type f -printf "/%h/%f\n" >> filelist.lst +fi +if [ -d usr/sbin ]; then + find usr/sbin -type f -printf "/%h/%f\n" >> filelist.lst +fi +touch doclist.lst +if [ -d usr/share/man ]; then + find usr/share/man -type f -printf "/%h/%f.gz\n" >> doclist.lst +fi +popd +mv %{buildroot}/filelist.lst . +mv %{buildroot}/doclist.lst . + +%files -n python3-keras-self-attention -f filelist.lst +%dir %{python3_sitelib}/* + +%files help -f doclist.lst +%{_docdir}/* + +%changelog +* Tue Apr 11 2023 Python_Bot <Python_Bot@openeuler.org> - 0.51.0-1 +- Package Spec generated @@ -0,0 +1 @@ +7bc0e7a51eb634705a34b7a7361261d5 keras-self-attention-0.51.0.tar.gz |