
diff options
| -rw-r--r-- | .gitignore | 1 | ||||
| -rw-r--r-- | python-timetomodel.spec | 399 | ||||
| -rw-r--r-- | sources | 1 |
3 files changed, 401 insertions, 0 deletions
@@ -0,0 +1 @@ +/timetomodel-0.7.3.tar.gz diff --git a/python-timetomodel.spec b/python-timetomodel.spec new file mode 100644 index 0000000..32703c1 --- /dev/null +++ b/python-timetomodel.spec @@ -0,0 +1,399 @@ +%global _empty_manifest_terminate_build 0 +Name: python-timetomodel +Version: 0.7.3 +Release: 1 +Summary: Sane handling of time series data for forecast modelling - with production usage in mind. +License: MIT License +URL: https://github.com/seitabv/timetomodel +Source0: https://mirrors.aliyun.com/pypi/web/packages/9e/51/948aa9b4e8498924181eb3d17533eff0b43483d46ca9201b6c96d24b410c/timetomodel-0.7.3.tar.gz +BuildArch: noarch + +Requires: python3-SQLAlchemy +Requires: python3-matplotlib +Requires: python3-numpy +Requires: python3-pandas +Requires: python3-dateutil +Requires: python3-pytz +Requires: python3-scikit-learn +Requires: python3-scipy +Requires: python3-statsmodels + +%description +# timetomodel + +Time series forecasting is a modern data science & engineering challenge. + +We noticed that these two worlds, data science and engineering of time series forecasting, are not very compatible. +Often, work from the data scientist has to be re-implemented by engineers to be used in production. + +`timetomodel` was created to change that. It describes the data treatment of a model, and also automates common data treatment tasks like building data for training and testing. + +As a *data scientist*, experiment with a model in your notebook. +Load data from static files (e.g. CSV) and try out lags, regressors and so on. +Compare plots and mean square errors of the models you developed. + +As an *engineer*, take over the model description and use it in your production code. +Often, this would entail not much more than changing the data source (e.g from CSV to a column in the database). + +`timetomodel` is supposed to wrap around any fit/predict type model, e.g. from statsmodels or scikit-learn (some work needed here to ensure support). + + +## Features + +Here are some features for both data scientists and engineers to enjoy: + +* Describe how to load data for outcome and regressor variables. Load from Pandas objects, CSV files, Pandas pickles or databases via SQLAlchemy. +* Create train & test data, including lags. +* Timezone awareness support. +* Custom data transformations, after loading (e.g. to remove duplicate) or only for forecasting (e.g. to apply a BoxCox transformation). +* Evaluate a model by RMSE, and plot the cumulative error. +* Support for creating rolling forecasts. + + +## Installation + +``pip install timetomodel`` + +## Example + +Here is an example where we describe a solar time series problem, and use ``statsmodels.OLS``, a linear regression model, to forecast one hour ahead: + + import pandas as pd + import pytz + from datetime import datetime, timedelta + from statsmodels.api import OLS + from timetomodel import speccing, ModelState, create_fitted_model, evaluate_models + from timetomodel.transforming import BoxCoxTransformation + from timetomodel.forecasting import make_rolling_forecasts + + data_start = datetime(2015, 3, 1, tzinfo=pytz.utc) + data_end = datetime(2015, 10, 31, tzinfo=pytz.utc) + + #### Solar model - 1h ahead #### + + # spec outcome variable + solar_outcome_var_spec = speccing.CSVFileSeriesSpecs( + file_path="data.csv", + time_column="datetime", + value_column="solar_power", + name="solar power", + feature_transformation=BoxCoxTransformation(lambda2=0.1) + ) + # spec regressor variable + regressor_spec_1h = speccing.CSVFileSeriesSpecs( + file_path="data.csv", + time_column="datetime", + value_column="irradiation_forecast1h", + name="irradiation forecast", + feature_transformation=BoxCoxTransformation(lambda2=0.1) + ) + # spec whole model treatment + solar_model1h_specs = speccing.ModelSpecs( + outcome_var=solar_outcome_var_spec, + model=OLS, + frequency=timedelta(minutes=15), + horizon=timedelta(hours=1), + lags=[lag * 96 for lag in range(1, 8)], # 7 days (data has daily seasonality) + regressors=[regressor_spec_1h], + start_of_training=data_start + timedelta(days=30), + end_of_testing=data_end, + ratio_training_testing_data=2/3, + remodel_frequency=timedelta(days=14) # re-train model every two weeks + ) + + solar_model1h = create_fitted_model(solar_model1h_specs, "Linear Regression Solar Horizon 1h") + # solar_model_1h is now an OLS model object which can be pickled and re-used. + # With the solar_model1h_specs in hand, your production code could always re-train a new one, + # if the model has become outdated. + + # For data scientists: evaluate model + evaluate_models(m1=ModelState(solar_model1h, solar_model1h_specs)) + +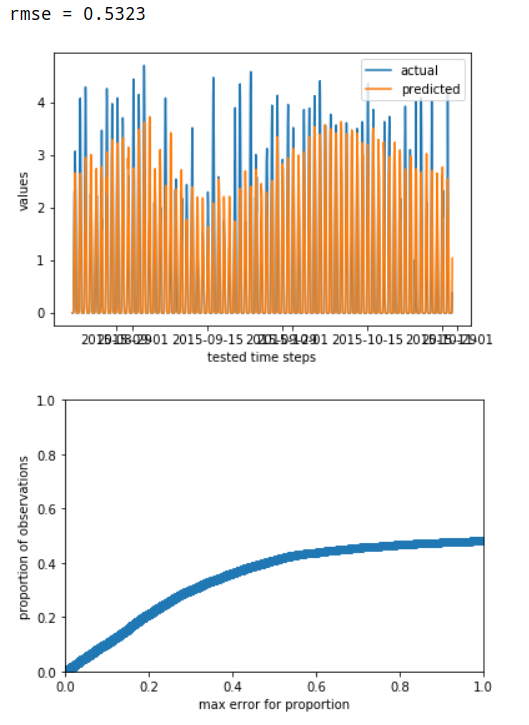 + + # For engineers a): Change data sources to use database (hinted) + solar_model1h_specs.outcome_var = speccing.DBSeriesSpecs(query=...) + solar_model1h_specs.regressors[0] = speccing.DBSeriesSpecs(query=...) + + # For engineers b): Use model to make forecasts for an hour + forecasts, model_state = make_rolling_forecasts( + start=datetime(2015, 11, 1, tzinfo=pytz.utc), + end=datetime(2015, 11, 1, 1, tzinfo=pytz.utc), + model_specs=solar_model1h_specs + ) + # model_state might have re-trained a new model automatically, by honoring the remodel_frequency + + + + + +%package -n python3-timetomodel +Summary: Sane handling of time series data for forecast modelling - with production usage in mind. +Provides: python-timetomodel +BuildRequires: python3-devel +BuildRequires: python3-setuptools +BuildRequires: python3-pip +%description -n python3-timetomodel +# timetomodel + +Time series forecasting is a modern data science & engineering challenge. + +We noticed that these two worlds, data science and engineering of time series forecasting, are not very compatible. +Often, work from the data scientist has to be re-implemented by engineers to be used in production. + +`timetomodel` was created to change that. It describes the data treatment of a model, and also automates common data treatment tasks like building data for training and testing. + +As a *data scientist*, experiment with a model in your notebook. +Load data from static files (e.g. CSV) and try out lags, regressors and so on. +Compare plots and mean square errors of the models you developed. + +As an *engineer*, take over the model description and use it in your production code. +Often, this would entail not much more than changing the data source (e.g from CSV to a column in the database). + +`timetomodel` is supposed to wrap around any fit/predict type model, e.g. from statsmodels or scikit-learn (some work needed here to ensure support). + + +## Features + +Here are some features for both data scientists and engineers to enjoy: + +* Describe how to load data for outcome and regressor variables. Load from Pandas objects, CSV files, Pandas pickles or databases via SQLAlchemy. +* Create train & test data, including lags. +* Timezone awareness support. +* Custom data transformations, after loading (e.g. to remove duplicate) or only for forecasting (e.g. to apply a BoxCox transformation). +* Evaluate a model by RMSE, and plot the cumulative error. +* Support for creating rolling forecasts. + + +## Installation + +``pip install timetomodel`` + +## Example + +Here is an example where we describe a solar time series problem, and use ``statsmodels.OLS``, a linear regression model, to forecast one hour ahead: + + import pandas as pd + import pytz + from datetime import datetime, timedelta + from statsmodels.api import OLS + from timetomodel import speccing, ModelState, create_fitted_model, evaluate_models + from timetomodel.transforming import BoxCoxTransformation + from timetomodel.forecasting import make_rolling_forecasts + + data_start = datetime(2015, 3, 1, tzinfo=pytz.utc) + data_end = datetime(2015, 10, 31, tzinfo=pytz.utc) + + #### Solar model - 1h ahead #### + + # spec outcome variable + solar_outcome_var_spec = speccing.CSVFileSeriesSpecs( + file_path="data.csv", + time_column="datetime", + value_column="solar_power", + name="solar power", + feature_transformation=BoxCoxTransformation(lambda2=0.1) + ) + # spec regressor variable + regressor_spec_1h = speccing.CSVFileSeriesSpecs( + file_path="data.csv", + time_column="datetime", + value_column="irradiation_forecast1h", + name="irradiation forecast", + feature_transformation=BoxCoxTransformation(lambda2=0.1) + ) + # spec whole model treatment + solar_model1h_specs = speccing.ModelSpecs( + outcome_var=solar_outcome_var_spec, + model=OLS, + frequency=timedelta(minutes=15), + horizon=timedelta(hours=1), + lags=[lag * 96 for lag in range(1, 8)], # 7 days (data has daily seasonality) + regressors=[regressor_spec_1h], + start_of_training=data_start + timedelta(days=30), + end_of_testing=data_end, + ratio_training_testing_data=2/3, + remodel_frequency=timedelta(days=14) # re-train model every two weeks + ) + + solar_model1h = create_fitted_model(solar_model1h_specs, "Linear Regression Solar Horizon 1h") + # solar_model_1h is now an OLS model object which can be pickled and re-used. + # With the solar_model1h_specs in hand, your production code could always re-train a new one, + # if the model has become outdated. + + # For data scientists: evaluate model + evaluate_models(m1=ModelState(solar_model1h, solar_model1h_specs)) + + + + # For engineers a): Change data sources to use database (hinted) + solar_model1h_specs.outcome_var = speccing.DBSeriesSpecs(query=...) + solar_model1h_specs.regressors[0] = speccing.DBSeriesSpecs(query=...) + + # For engineers b): Use model to make forecasts for an hour + forecasts, model_state = make_rolling_forecasts( + start=datetime(2015, 11, 1, tzinfo=pytz.utc), + end=datetime(2015, 11, 1, 1, tzinfo=pytz.utc), + model_specs=solar_model1h_specs + ) + # model_state might have re-trained a new model automatically, by honoring the remodel_frequency + + + + + +%package help +Summary: Development documents and examples for timetomodel +Provides: python3-timetomodel-doc +%description help +# timetomodel + +Time series forecasting is a modern data science & engineering challenge. + +We noticed that these two worlds, data science and engineering of time series forecasting, are not very compatible. +Often, work from the data scientist has to be re-implemented by engineers to be used in production. + +`timetomodel` was created to change that. It describes the data treatment of a model, and also automates common data treatment tasks like building data for training and testing. + +As a *data scientist*, experiment with a model in your notebook. +Load data from static files (e.g. CSV) and try out lags, regressors and so on. +Compare plots and mean square errors of the models you developed. + +As an *engineer*, take over the model description and use it in your production code. +Often, this would entail not much more than changing the data source (e.g from CSV to a column in the database). + +`timetomodel` is supposed to wrap around any fit/predict type model, e.g. from statsmodels or scikit-learn (some work needed here to ensure support). + + +## Features + +Here are some features for both data scientists and engineers to enjoy: + +* Describe how to load data for outcome and regressor variables. Load from Pandas objects, CSV files, Pandas pickles or databases via SQLAlchemy. +* Create train & test data, including lags. +* Timezone awareness support. +* Custom data transformations, after loading (e.g. to remove duplicate) or only for forecasting (e.g. to apply a BoxCox transformation). +* Evaluate a model by RMSE, and plot the cumulative error. +* Support for creating rolling forecasts. + + +## Installation + +``pip install timetomodel`` + +## Example + +Here is an example where we describe a solar time series problem, and use ``statsmodels.OLS``, a linear regression model, to forecast one hour ahead: + + import pandas as pd + import pytz + from datetime import datetime, timedelta + from statsmodels.api import OLS + from timetomodel import speccing, ModelState, create_fitted_model, evaluate_models + from timetomodel.transforming import BoxCoxTransformation + from timetomodel.forecasting import make_rolling_forecasts + + data_start = datetime(2015, 3, 1, tzinfo=pytz.utc) + data_end = datetime(2015, 10, 31, tzinfo=pytz.utc) + + #### Solar model - 1h ahead #### + + # spec outcome variable + solar_outcome_var_spec = speccing.CSVFileSeriesSpecs( + file_path="data.csv", + time_column="datetime", + value_column="solar_power", + name="solar power", + feature_transformation=BoxCoxTransformation(lambda2=0.1) + ) + # spec regressor variable + regressor_spec_1h = speccing.CSVFileSeriesSpecs( + file_path="data.csv", + time_column="datetime", + value_column="irradiation_forecast1h", + name="irradiation forecast", + feature_transformation=BoxCoxTransformation(lambda2=0.1) + ) + # spec whole model treatment + solar_model1h_specs = speccing.ModelSpecs( + outcome_var=solar_outcome_var_spec, + model=OLS, + frequency=timedelta(minutes=15), + horizon=timedelta(hours=1), + lags=[lag * 96 for lag in range(1, 8)], # 7 days (data has daily seasonality) + regressors=[regressor_spec_1h], + start_of_training=data_start + timedelta(days=30), + end_of_testing=data_end, + ratio_training_testing_data=2/3, + remodel_frequency=timedelta(days=14) # re-train model every two weeks + ) + + solar_model1h = create_fitted_model(solar_model1h_specs, "Linear Regression Solar Horizon 1h") + # solar_model_1h is now an OLS model object which can be pickled and re-used. + # With the solar_model1h_specs in hand, your production code could always re-train a new one, + # if the model has become outdated. + + # For data scientists: evaluate model + evaluate_models(m1=ModelState(solar_model1h, solar_model1h_specs)) + + + + # For engineers a): Change data sources to use database (hinted) + solar_model1h_specs.outcome_var = speccing.DBSeriesSpecs(query=...) + solar_model1h_specs.regressors[0] = speccing.DBSeriesSpecs(query=...) + + # For engineers b): Use model to make forecasts for an hour + forecasts, model_state = make_rolling_forecasts( + start=datetime(2015, 11, 1, tzinfo=pytz.utc), + end=datetime(2015, 11, 1, 1, tzinfo=pytz.utc), + model_specs=solar_model1h_specs + ) + # model_state might have re-trained a new model automatically, by honoring the remodel_frequency + + + + + +%prep +%autosetup -n timetomodel-0.7.3 + +%build +%py3_build + +%install +%py3_install +install -d -m755 %{buildroot}/%{_pkgdocdir} +if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi +if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi +if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi +if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi +pushd %{buildroot} +if [ -d usr/lib ]; then + find usr/lib -type f -printf "\"/%h/%f\"\n" >> filelist.lst +fi +if [ -d usr/lib64 ]; then + find usr/lib64 -type f -printf "\"/%h/%f\"\n" >> filelist.lst +fi +if [ -d usr/bin ]; then + find usr/bin -type f -printf "\"/%h/%f\"\n" >> filelist.lst +fi +if [ -d usr/sbin ]; then + find usr/sbin -type f -printf "\"/%h/%f\"\n" >> filelist.lst +fi +touch doclist.lst +if [ -d usr/share/man ]; then + find usr/share/man -type f -printf "\"/%h/%f.gz\"\n" >> doclist.lst +fi +popd +mv %{buildroot}/filelist.lst . +mv %{buildroot}/doclist.lst . + +%files -n python3-timetomodel -f filelist.lst +%dir %{python3_sitelib}/* + +%files help -f doclist.lst +%{_docdir}/* + +%changelog +* Tue Jun 20 2023 Python_Bot <Python_Bot@openeuler.org> - 0.7.3-1 +- Package Spec generated @@ -0,0 +1 @@ +94d1af43fb5191f705a27808609aefde timetomodel-0.7.3.tar.gz |