
diff options
| author | CoprDistGit <infra@openeuler.org> | 2023-04-11 12:50:28 +0000 |
|---|---|---|
| committer | CoprDistGit <infra@openeuler.org> | 2023-04-11 12:50:28 +0000 |
| commit | 20308e6b57426e564ffdc451430e3b7147d70399 (patch) | |
| tree | 52262330c8d21a2ae97d8a130f379c709be63c06 | |
| parent | 95b343ddc8a8bca2ec2f732f0115b69828e83d92 (diff) | |
automatic import of python-vaex
| -rw-r--r-- | .gitignore | 1 | ||||
| -rw-r--r-- | python-vaex.spec | 388 | ||||
| -rw-r--r-- | sources | 1 |
3 files changed, 390 insertions, 0 deletions
@@ -0,0 +1 @@ +/vaex-4.16.0.tar.gz diff --git a/python-vaex.spec b/python-vaex.spec new file mode 100644 index 0000000..762c6a7 --- /dev/null +++ b/python-vaex.spec @@ -0,0 +1,388 @@ +%global _empty_manifest_terminate_build 0 +Name: python-vaex +Version: 4.16.0 +Release: 1 +Summary: Out-of-Core DataFrames to visualize and explore big tabular datasets +License: MIT +URL: https://www.github.com/vaexio/vaex +Source0: https://mirrors.nju.edu.cn/pypi/web/packages/62/fd/061dcce6ee7211f32b28aa6b49f8a19ece9619535b43ee3171b25c001711/vaex-4.16.0.tar.gz +BuildArch: noarch + +Requires: python3-vaex-core +Requires: python3-vaex-astro +Requires: python3-vaex-hdf5 +Requires: python3-vaex-viz +Requires: python3-vaex-server +Requires: python3-vaex-jupyter +Requires: python3-vaex-ml + +%description + +[](https://docs.vaex.io) +[](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ) + +# What is Vaex? + +Vaex is a high performance Python library for lazy **Out-of-Core DataFrames** +(similar to Pandas), to visualize and explore big tabular datasets. It +calculates *statistics* such as mean, sum, count, standard deviation etc, on an +*N-dimensional grid* for more than **a billion** (`10^9`) samples/rows **per +second**. Visualization is done using **histograms**, **density plots** and **3d +volume rendering**, allowing interactive exploration of big data. Vaex uses +memory mapping, zero memory copy policy and lazy computations for best +performance (no memory wasted). + +# Installing +With pip: +``` +$ pip install vaex +``` +Or conda: +``` +$ conda install -c conda-forge vaex +``` + +[For more details, see the documentation](https://docs.vaex.io/en/latest/installing.html) + +# Key features +## Instant opening of Huge data files (memory mapping) +[HDF5](https://en.wikipedia.org/wiki/Hierarchical_Data_Format) and [Apache Arrow](https://arrow.apache.org/) supported. + + + + +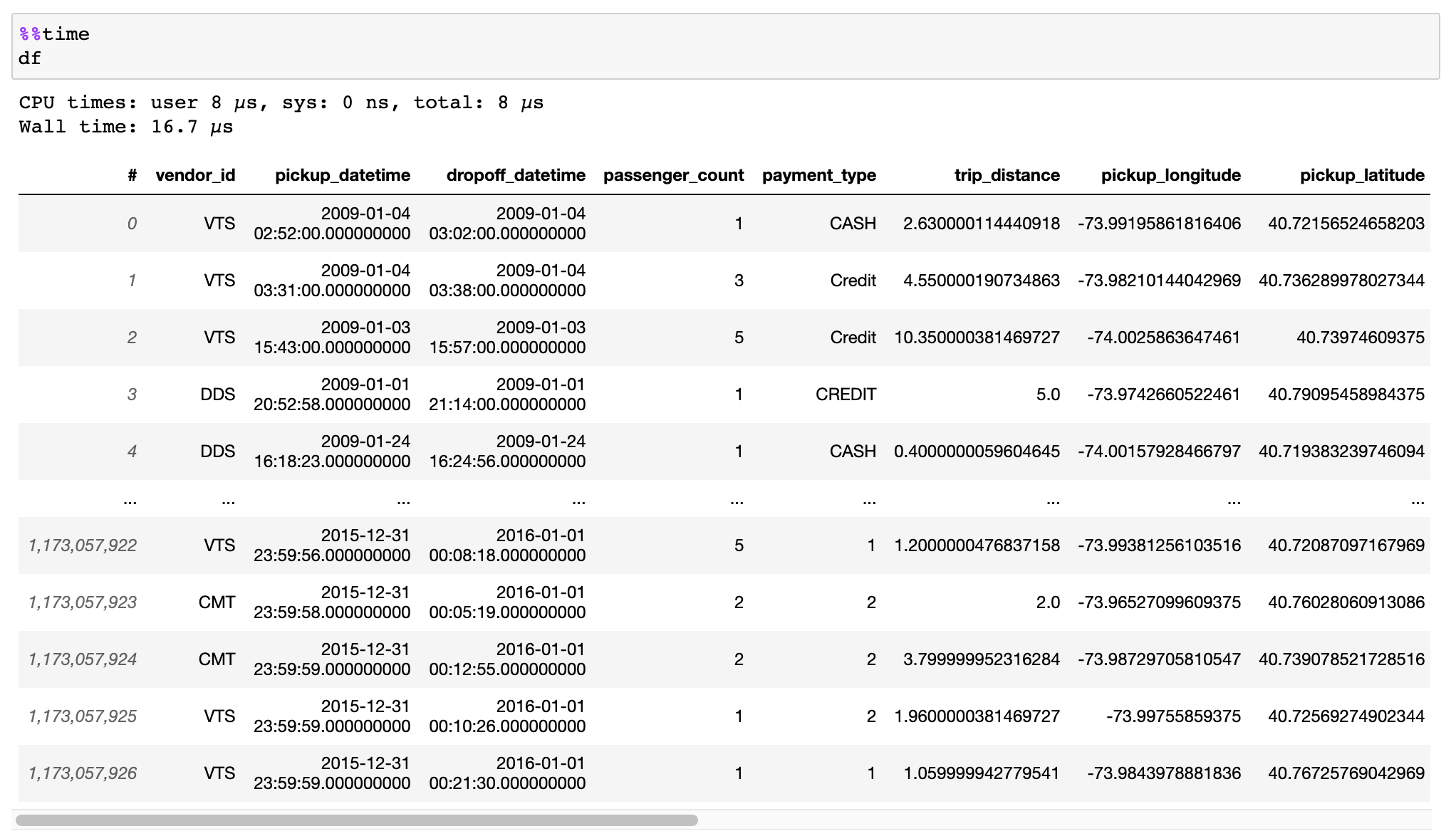 + +[Read the documentation on how to efficiently convert your data](https://docs.vaex.io/en/latest/example_io.html) from CSV files, Pandas DataFrames, or other sources. + + +Lazy streaming from S3 supported in combination with memory mapping. + + + + +## Expression system +Don't waste memory or time with feature engineering, we (lazily) transform your data when needed. + + +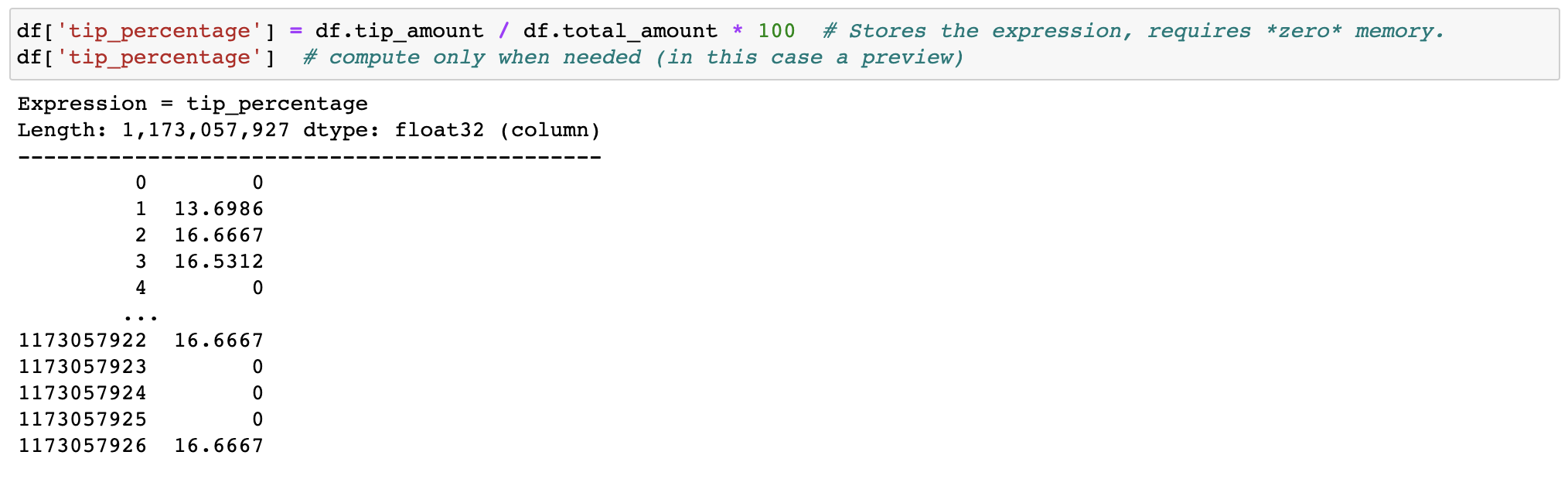 + + + +## Out-of-core DataFrame +Filtering and evaluating expressions will not waste memory by making copies; the data is kept untouched on disk, and will be streamed only when needed. Delay the time before you need a cluster. + + + + +## Fast groupby / aggregations +Vaex implements parallelized, highly performant `groupby` operations, especially when using categories (>1 billion/second). + + +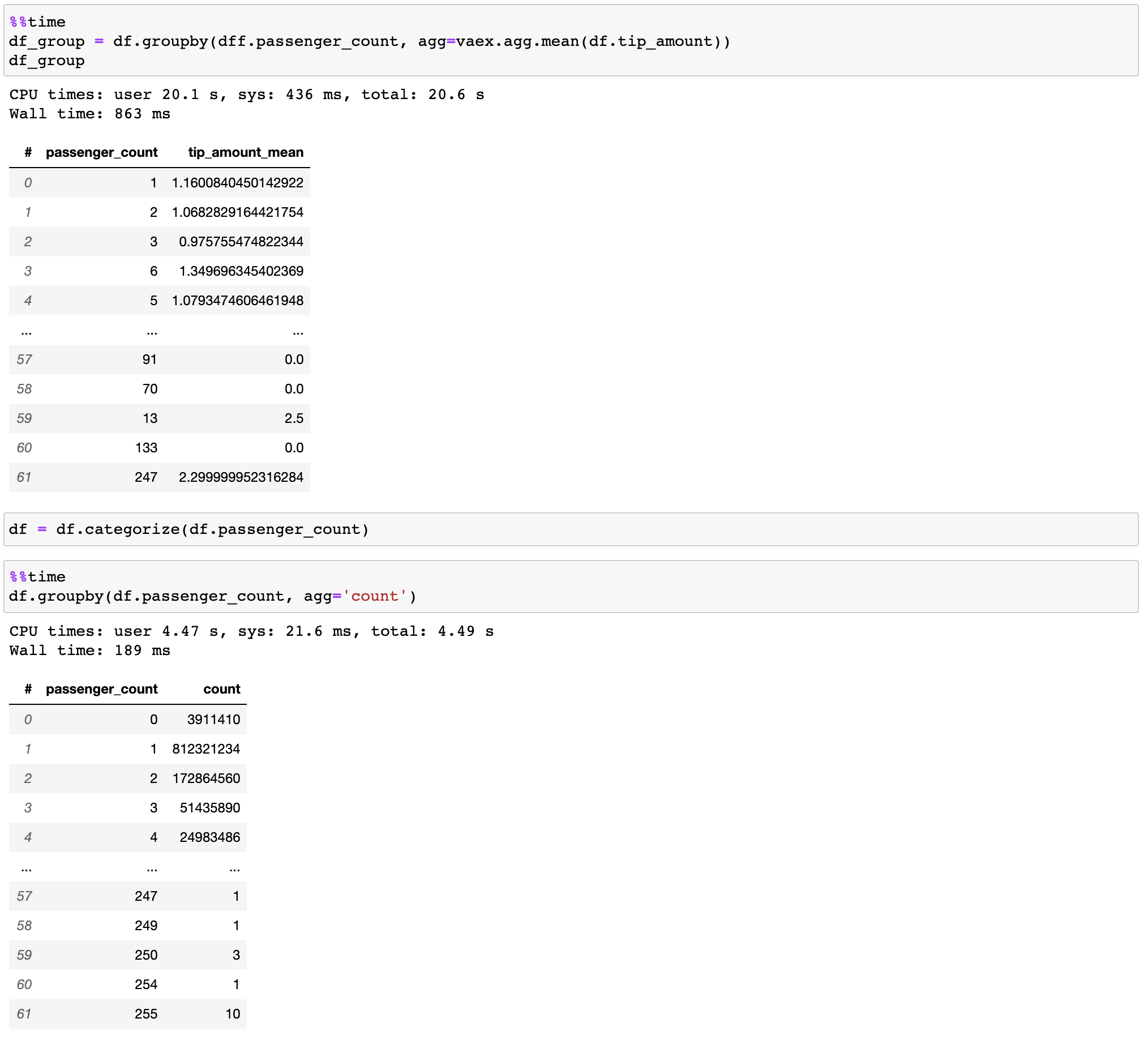 + + +## Fast and efficient join +Vaex doesn't copy/materialize the 'right' table when joining, saving gigabytes of memory. With subsecond joining on a billion rows, it's pretty fast! + +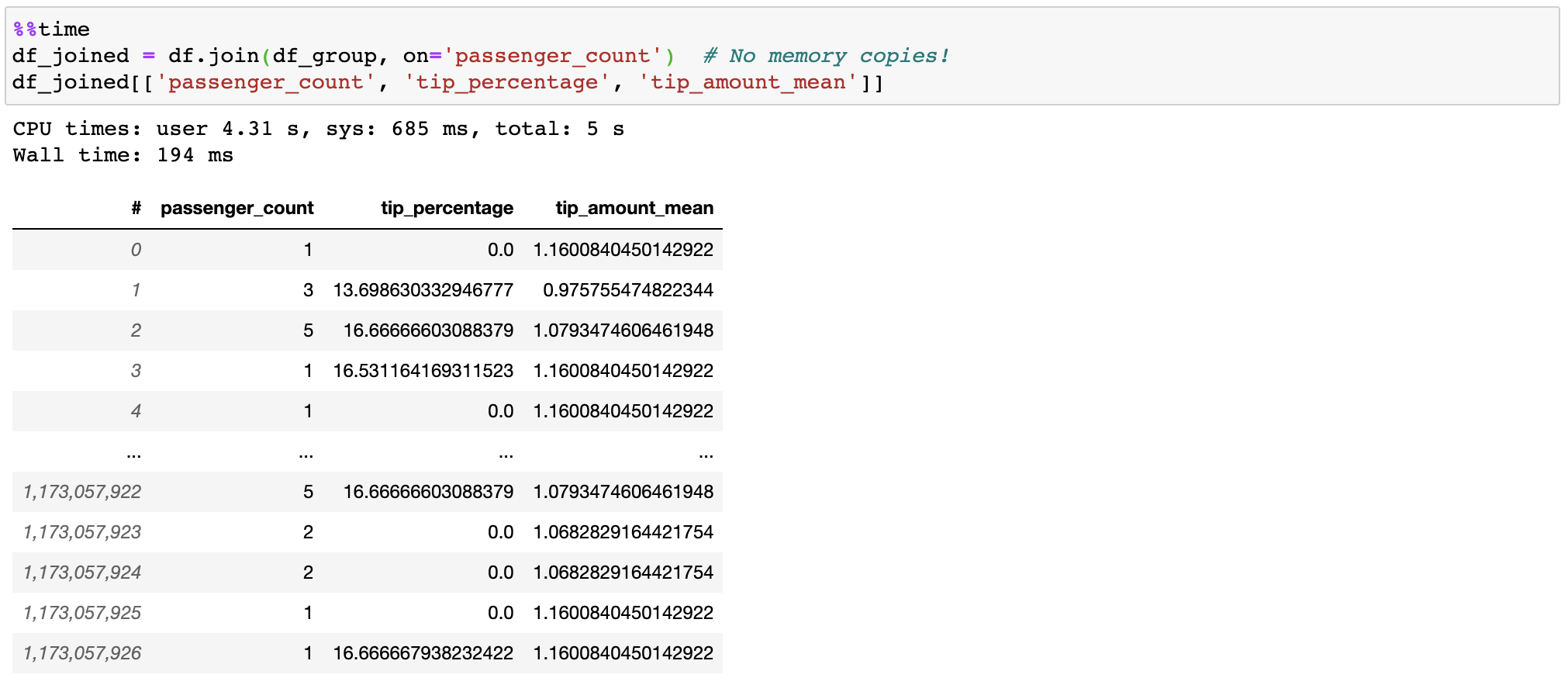 + +## More features + + * Remote DataFrames (documentation coming soon) + * Integration into [Jupyter and Voila for interactive notebooks and dashboards](https://vaex.readthedocs.io/en/latest/tutorial_jupyter.html) + * [Machine Learning without (explicit) pipelines](https://vaex.readthedocs.io/en/latest/tutorial_ml.html) + + +## Contributing + +See [contributing](CONTRIBUTING.md) page. + +## Slack + +Join the discussion in our [Slack](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ) channel! + +# Learn more about Vaex + * Articles + * [Beyond Pandas: Spark, Dask, Vaex and other big data technologies battling head to head](https://towardsdatascience.com/beyond-pandas-spark-dask-vaex-and-other-big-data-technologies-battling-head-to-head-a453a1f8cc13) (includes benchmarks) + * [7 reasons why I love Vaex for data science](https://towardsdatascience.com/7-reasons-why-i-love-vaex-for-data-science-99008bc8044b) (tips and trics) + * [ML impossible: Train 1 billion samples in 5 minutes on your laptop using Vaex and Scikit-Learn](https://towardsdatascience.com/ml-impossible-train-a-1-billion-sample-model-in-20-minutes-with-vaex-and-scikit-learn-on-your-9e2968e6f385) + * [How to analyse 100 GB of data on your laptop with Python](https://towardsdatascience.com/how-to-analyse-100s-of-gbs-of-data-on-your-laptop-with-python-f83363dda94) + * [Flying high with Vaex: analysis of over 30 years of flight data in Python](https://towardsdatascience.com/https-medium-com-jovan-veljanoski-flying-high-with-vaex-analysis-of-over-30-years-of-flight-data-in-python-b224825a6d56) + * [Vaex: A DataFrame with super strings - Speed up your text processing up to a 1000x +](https://towardsdatascience.com/vaex-a-dataframe-with-super-strings-789b92e8d861) + * [Vaex: Out of Core Dataframes for Python and Fast Visualization - 1 billion row datasets on your laptop](https://towardsdatascience.com/vaex-out-of-core-dataframes-for-python-and-fast-visualization-12c102db044a) + + * [Follow our tutorials](https://docs.vaex.io/en/latest/tutorials.html) + * Watch our more recent talks: + * [PyData London 2019](https://www.youtube.com/watch?v=2Tt0i823-ec) + * [SciPy 2019](https://www.youtube.com/watch?v=ELtjRdPT8is) + * Contact us for data science solutions, training, or enterprise support at https://vaex.io/ + + + + +%package -n python3-vaex +Summary: Out-of-Core DataFrames to visualize and explore big tabular datasets +Provides: python-vaex +BuildRequires: python3-devel +BuildRequires: python3-setuptools +BuildRequires: python3-pip +%description -n python3-vaex + +[](https://docs.vaex.io) +[](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ) + +# What is Vaex? + +Vaex is a high performance Python library for lazy **Out-of-Core DataFrames** +(similar to Pandas), to visualize and explore big tabular datasets. It +calculates *statistics* such as mean, sum, count, standard deviation etc, on an +*N-dimensional grid* for more than **a billion** (`10^9`) samples/rows **per +second**. Visualization is done using **histograms**, **density plots** and **3d +volume rendering**, allowing interactive exploration of big data. Vaex uses +memory mapping, zero memory copy policy and lazy computations for best +performance (no memory wasted). + +# Installing +With pip: +``` +$ pip install vaex +``` +Or conda: +``` +$ conda install -c conda-forge vaex +``` + +[For more details, see the documentation](https://docs.vaex.io/en/latest/installing.html) + +# Key features +## Instant opening of Huge data files (memory mapping) +[HDF5](https://en.wikipedia.org/wiki/Hierarchical_Data_Format) and [Apache Arrow](https://arrow.apache.org/) supported. + + + + + + +[Read the documentation on how to efficiently convert your data](https://docs.vaex.io/en/latest/example_io.html) from CSV files, Pandas DataFrames, or other sources. + + +Lazy streaming from S3 supported in combination with memory mapping. + + + + +## Expression system +Don't waste memory or time with feature engineering, we (lazily) transform your data when needed. + + + + + + +## Out-of-core DataFrame +Filtering and evaluating expressions will not waste memory by making copies; the data is kept untouched on disk, and will be streamed only when needed. Delay the time before you need a cluster. + + + + +## Fast groupby / aggregations +Vaex implements parallelized, highly performant `groupby` operations, especially when using categories (>1 billion/second). + + + + + +## Fast and efficient join +Vaex doesn't copy/materialize the 'right' table when joining, saving gigabytes of memory. With subsecond joining on a billion rows, it's pretty fast! + + + +## More features + + * Remote DataFrames (documentation coming soon) + * Integration into [Jupyter and Voila for interactive notebooks and dashboards](https://vaex.readthedocs.io/en/latest/tutorial_jupyter.html) + * [Machine Learning without (explicit) pipelines](https://vaex.readthedocs.io/en/latest/tutorial_ml.html) + + +## Contributing + +See [contributing](CONTRIBUTING.md) page. + +## Slack + +Join the discussion in our [Slack](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ) channel! + +# Learn more about Vaex + * Articles + * [Beyond Pandas: Spark, Dask, Vaex and other big data technologies battling head to head](https://towardsdatascience.com/beyond-pandas-spark-dask-vaex-and-other-big-data-technologies-battling-head-to-head-a453a1f8cc13) (includes benchmarks) + * [7 reasons why I love Vaex for data science](https://towardsdatascience.com/7-reasons-why-i-love-vaex-for-data-science-99008bc8044b) (tips and trics) + * [ML impossible: Train 1 billion samples in 5 minutes on your laptop using Vaex and Scikit-Learn](https://towardsdatascience.com/ml-impossible-train-a-1-billion-sample-model-in-20-minutes-with-vaex-and-scikit-learn-on-your-9e2968e6f385) + * [How to analyse 100 GB of data on your laptop with Python](https://towardsdatascience.com/how-to-analyse-100s-of-gbs-of-data-on-your-laptop-with-python-f83363dda94) + * [Flying high with Vaex: analysis of over 30 years of flight data in Python](https://towardsdatascience.com/https-medium-com-jovan-veljanoski-flying-high-with-vaex-analysis-of-over-30-years-of-flight-data-in-python-b224825a6d56) + * [Vaex: A DataFrame with super strings - Speed up your text processing up to a 1000x +](https://towardsdatascience.com/vaex-a-dataframe-with-super-strings-789b92e8d861) + * [Vaex: Out of Core Dataframes for Python and Fast Visualization - 1 billion row datasets on your laptop](https://towardsdatascience.com/vaex-out-of-core-dataframes-for-python-and-fast-visualization-12c102db044a) + + * [Follow our tutorials](https://docs.vaex.io/en/latest/tutorials.html) + * Watch our more recent talks: + * [PyData London 2019](https://www.youtube.com/watch?v=2Tt0i823-ec) + * [SciPy 2019](https://www.youtube.com/watch?v=ELtjRdPT8is) + * Contact us for data science solutions, training, or enterprise support at https://vaex.io/ + + + + +%package help +Summary: Development documents and examples for vaex +Provides: python3-vaex-doc +%description help + +[](https://docs.vaex.io) +[](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ) + +# What is Vaex? + +Vaex is a high performance Python library for lazy **Out-of-Core DataFrames** +(similar to Pandas), to visualize and explore big tabular datasets. It +calculates *statistics* such as mean, sum, count, standard deviation etc, on an +*N-dimensional grid* for more than **a billion** (`10^9`) samples/rows **per +second**. Visualization is done using **histograms**, **density plots** and **3d +volume rendering**, allowing interactive exploration of big data. Vaex uses +memory mapping, zero memory copy policy and lazy computations for best +performance (no memory wasted). + +# Installing +With pip: +``` +$ pip install vaex +``` +Or conda: +``` +$ conda install -c conda-forge vaex +``` + +[For more details, see the documentation](https://docs.vaex.io/en/latest/installing.html) + +# Key features +## Instant opening of Huge data files (memory mapping) +[HDF5](https://en.wikipedia.org/wiki/Hierarchical_Data_Format) and [Apache Arrow](https://arrow.apache.org/) supported. + + + + + + +[Read the documentation on how to efficiently convert your data](https://docs.vaex.io/en/latest/example_io.html) from CSV files, Pandas DataFrames, or other sources. + + +Lazy streaming from S3 supported in combination with memory mapping. + + + + +## Expression system +Don't waste memory or time with feature engineering, we (lazily) transform your data when needed. + + + + + + +## Out-of-core DataFrame +Filtering and evaluating expressions will not waste memory by making copies; the data is kept untouched on disk, and will be streamed only when needed. Delay the time before you need a cluster. + + + + +## Fast groupby / aggregations +Vaex implements parallelized, highly performant `groupby` operations, especially when using categories (>1 billion/second). + + + + + +## Fast and efficient join +Vaex doesn't copy/materialize the 'right' table when joining, saving gigabytes of memory. With subsecond joining on a billion rows, it's pretty fast! + + + +## More features + + * Remote DataFrames (documentation coming soon) + * Integration into [Jupyter and Voila for interactive notebooks and dashboards](https://vaex.readthedocs.io/en/latest/tutorial_jupyter.html) + * [Machine Learning without (explicit) pipelines](https://vaex.readthedocs.io/en/latest/tutorial_ml.html) + + +## Contributing + +See [contributing](CONTRIBUTING.md) page. + +## Slack + +Join the discussion in our [Slack](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ) channel! + +# Learn more about Vaex + * Articles + * [Beyond Pandas: Spark, Dask, Vaex and other big data technologies battling head to head](https://towardsdatascience.com/beyond-pandas-spark-dask-vaex-and-other-big-data-technologies-battling-head-to-head-a453a1f8cc13) (includes benchmarks) + * [7 reasons why I love Vaex for data science](https://towardsdatascience.com/7-reasons-why-i-love-vaex-for-data-science-99008bc8044b) (tips and trics) + * [ML impossible: Train 1 billion samples in 5 minutes on your laptop using Vaex and Scikit-Learn](https://towardsdatascience.com/ml-impossible-train-a-1-billion-sample-model-in-20-minutes-with-vaex-and-scikit-learn-on-your-9e2968e6f385) + * [How to analyse 100 GB of data on your laptop with Python](https://towardsdatascience.com/how-to-analyse-100s-of-gbs-of-data-on-your-laptop-with-python-f83363dda94) + * [Flying high with Vaex: analysis of over 30 years of flight data in Python](https://towardsdatascience.com/https-medium-com-jovan-veljanoski-flying-high-with-vaex-analysis-of-over-30-years-of-flight-data-in-python-b224825a6d56) + * [Vaex: A DataFrame with super strings - Speed up your text processing up to a 1000x +](https://towardsdatascience.com/vaex-a-dataframe-with-super-strings-789b92e8d861) + * [Vaex: Out of Core Dataframes for Python and Fast Visualization - 1 billion row datasets on your laptop](https://towardsdatascience.com/vaex-out-of-core-dataframes-for-python-and-fast-visualization-12c102db044a) + + * [Follow our tutorials](https://docs.vaex.io/en/latest/tutorials.html) + * Watch our more recent talks: + * [PyData London 2019](https://www.youtube.com/watch?v=2Tt0i823-ec) + * [SciPy 2019](https://www.youtube.com/watch?v=ELtjRdPT8is) + * Contact us for data science solutions, training, or enterprise support at https://vaex.io/ + + + + +%prep +%autosetup -n vaex-4.16.0 + +%build +%py3_build + +%install +%py3_install +install -d -m755 %{buildroot}/%{_pkgdocdir} +if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi +if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi +if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi +if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi +pushd %{buildroot} +if [ -d usr/lib ]; then + find usr/lib -type f -printf "/%h/%f\n" >> filelist.lst +fi +if [ -d usr/lib64 ]; then + find usr/lib64 -type f -printf "/%h/%f\n" >> filelist.lst +fi +if [ -d usr/bin ]; then + find usr/bin -type f -printf "/%h/%f\n" >> filelist.lst +fi +if [ -d usr/sbin ]; then + find usr/sbin -type f -printf "/%h/%f\n" >> filelist.lst +fi +touch doclist.lst +if [ -d usr/share/man ]; then + find usr/share/man -type f -printf "/%h/%f.gz\n" >> doclist.lst +fi +popd +mv %{buildroot}/filelist.lst . +mv %{buildroot}/doclist.lst . + +%files -n python3-vaex -f filelist.lst +%dir %{python3_sitelib}/* + +%files help -f doclist.lst +%{_docdir}/* + +%changelog +* Tue Apr 11 2023 Python_Bot <Python_Bot@openeuler.org> - 4.16.0-1 +- Package Spec generated @@ -0,0 +1 @@ +d5dc4ce040babf90ab5a516a3d24094a vaex-4.16.0.tar.gz |