%global _empty_manifest_terminate_build 0
Name: python-klib
Version: 1.0.7
Release: 1
Summary: Customized data preprocessing functions for frequent tasks.
License: MIT
URL: https://pypi.org/project/klib/
Source0: https://mirrors.nju.edu.cn/pypi/web/packages/fb/a5/fb9d8c6629bb46881e81c7bb2db4b3af526a414bf887abe33bd5c3170c5d/klib-1.0.7.tar.gz
BuildArch: noarch
Requires: python3-Jinja2
Requires: python3-matplotlib
Requires: python3-numpy
Requires: python3-pandas
Requires: python3-scipy
Requires: python3-seaborn
%description
[](https://github.com/akanz1/klib)
[](https://pypi.org/project/klib/)
[](https://github.com/akanz1/klib/commits/main)
[](https://sonarcloud.io/dashboard?id=akanz1_klib)
[](https://scrutinizer-ci.com/g/akanz1/klib/)
[](https://codecov.io/gh/akanz1/klib)
**klib** is a Python library for importing, cleaning, analyzing and preprocessing data. Explanations on key functionalities can be found on [Medium / TowardsDataScience](https://medium.com/@akanz) and in the [examples](examples) section. Additionally, there are great introductions and overviews of the functionality on [PythonBytes](https://pythonbytes.fm/episodes/show/240/this-is-github-your-pilot-speaking) or on [YouTube (Data Professor)](https://www.youtube.com/watch?v=URjJVEeZxxU).
## Installation
Use the package manager [pip](https://pip.pypa.io/en/stable/) to install klib.
[](https://pypi.org/project/klib/)
[](https://pypi.org/project/klib/)
```bash
pip install -U klib
```
Alternatively, to install this package with conda run:
[](https://anaconda.org/conda-forge/klib)
[](https://anaconda.org/conda-forge/klib)
```bash
conda install -c conda-forge klib
```
## Usage
```python
import klib
import pandas as pd
df = pd.DataFrame(data)
# klib.describe - functions for visualizing datasets
- klib.cat_plot(df) # returns a visualization of the number and frequency of categorical features
- klib.corr_mat(df) # returns a color-encoded correlation matrix
- klib.corr_plot(df) # returns a color-encoded heatmap, ideal for correlations
- klib.dist_plot(df) # returns a distribution plot for every numeric feature
- klib.missingval_plot(df) # returns a figure containing information about missing values
# klib.clean - functions for cleaning datasets
- klib.data_cleaning(df) # performs datacleaning (drop duplicates & empty rows/cols, adjust dtypes,...)
- klib.clean_column_names(df) # cleans and standardizes column names, also called inside data_cleaning()
- klib.convert_datatypes(df) # converts existing to more efficient dtypes, also called inside data_cleaning()
- klib.drop_missing(df) # drops missing values, also called in data_cleaning()
- klib.mv_col_handling(df) # drops features with high ratio of missing vals based on informational content
- klib.pool_duplicate_subsets(df) # pools subset of cols based on duplicates with min. loss of information
```
## Examples
Find all available examples as well as applications of the functions in **klib.clean()** with detailed descriptions here.
```python
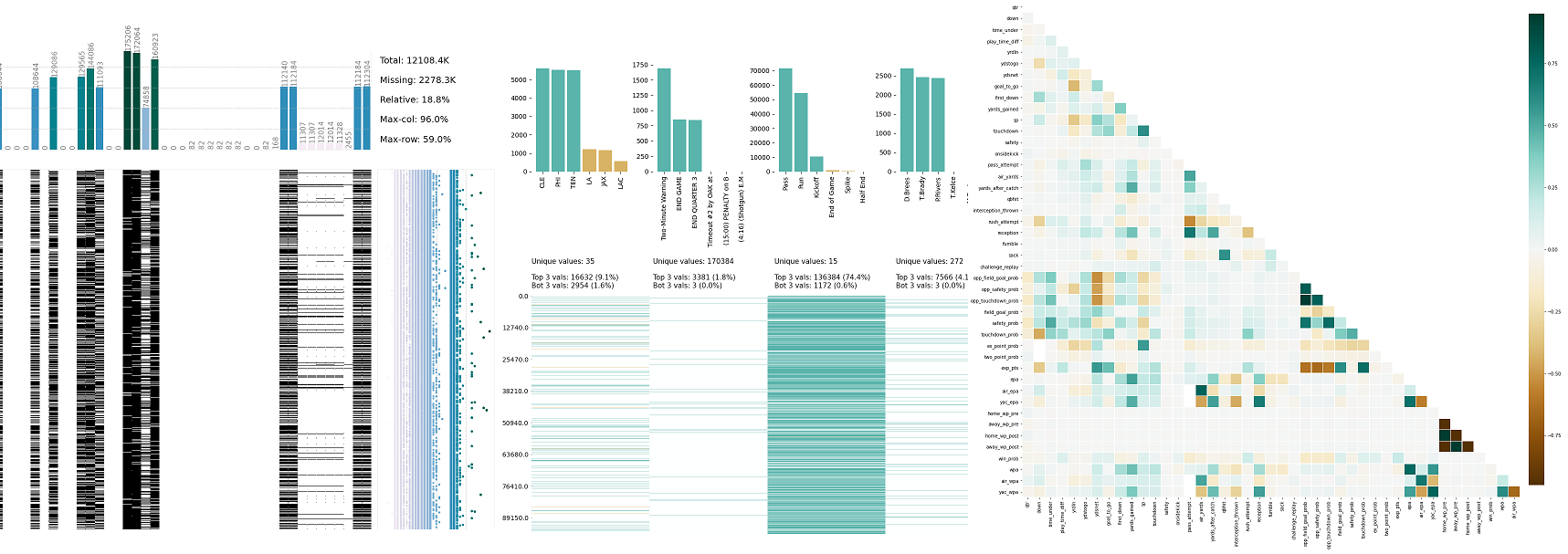
klib.missingval_plot(df) # default representation of missing values in a DataFrame, plenty of settings are available
```
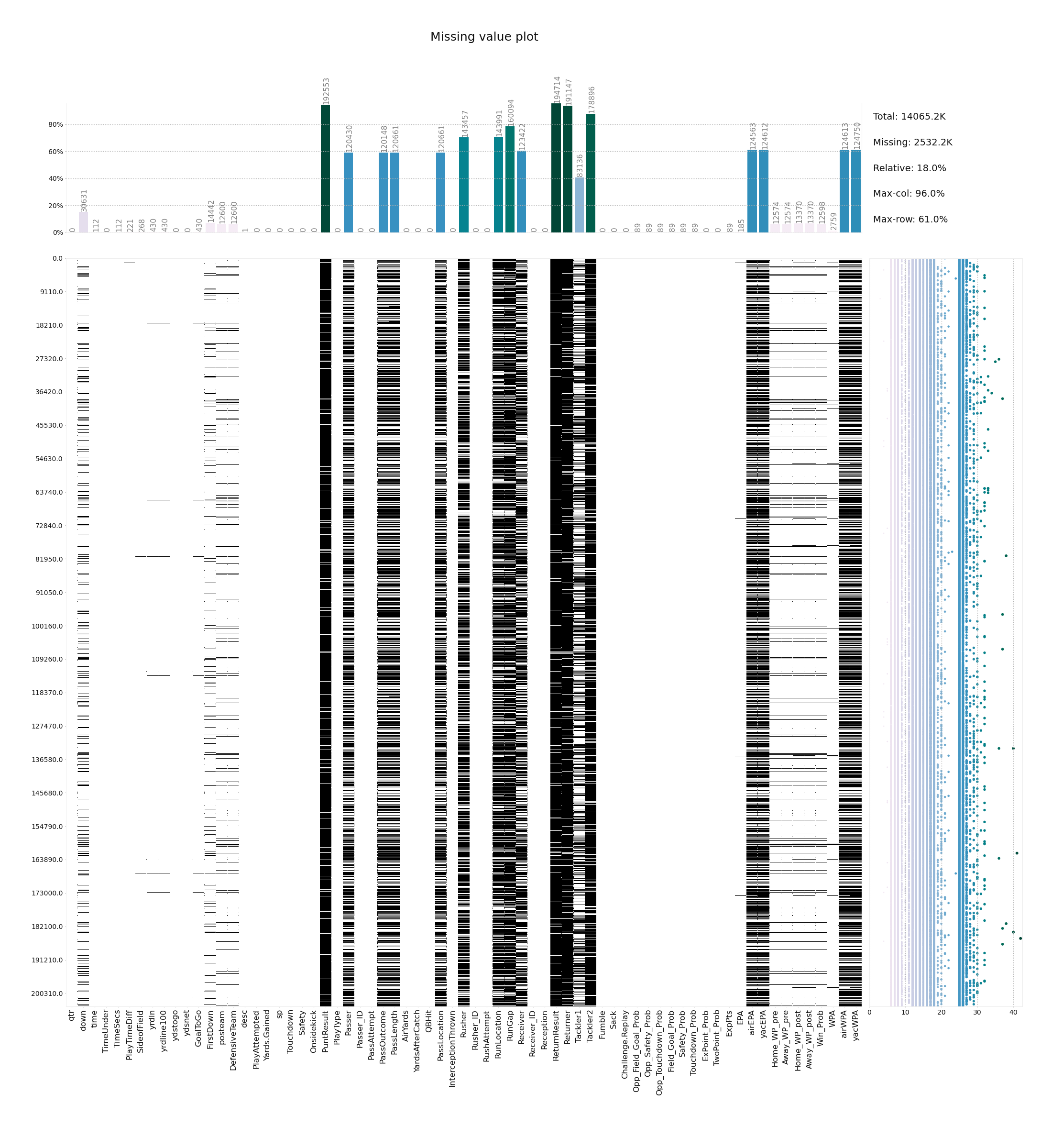
```python
klib.corr_plot(df, split='pos') # displaying only positive correlations, other settings include threshold, cmap...
klib.corr_plot(df, split='neg') # displaying only negative correlations
```
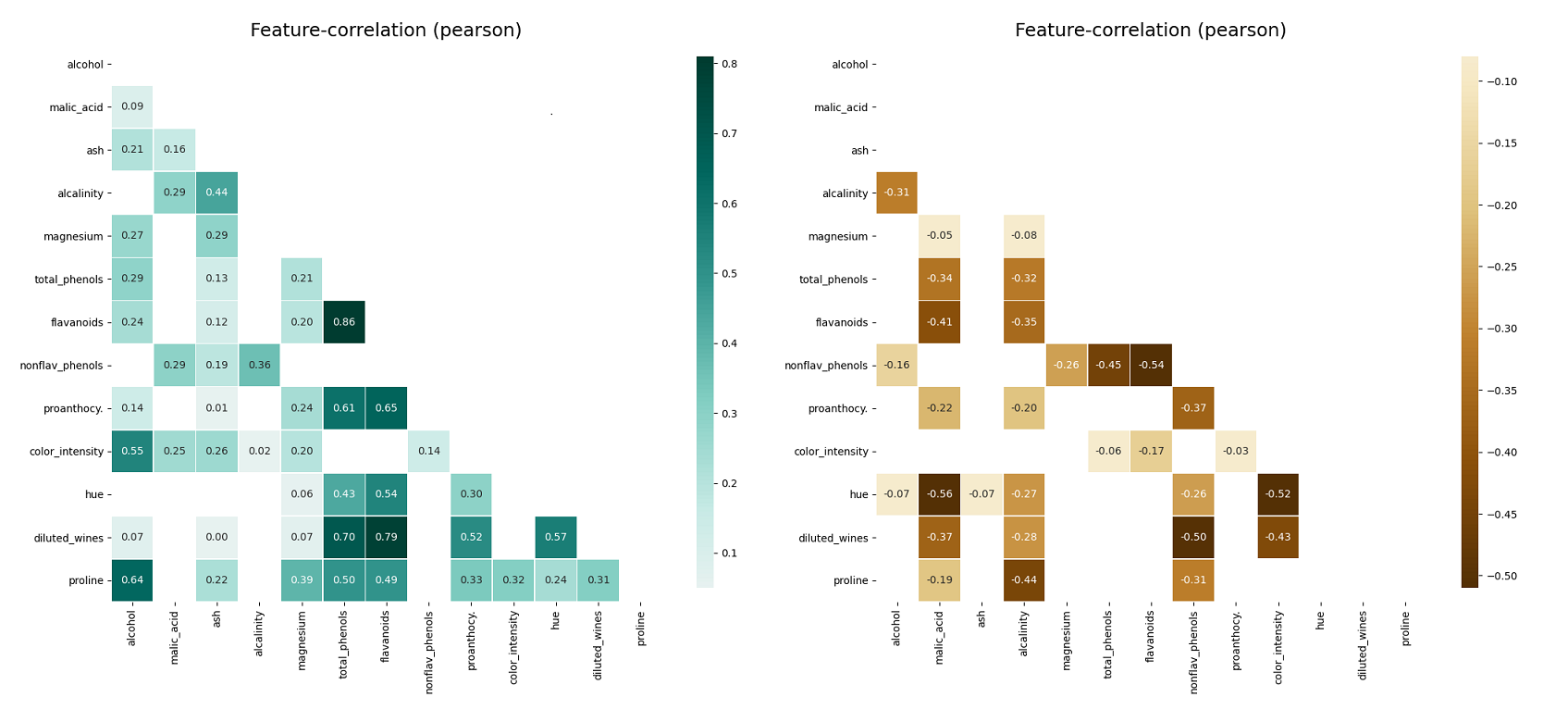
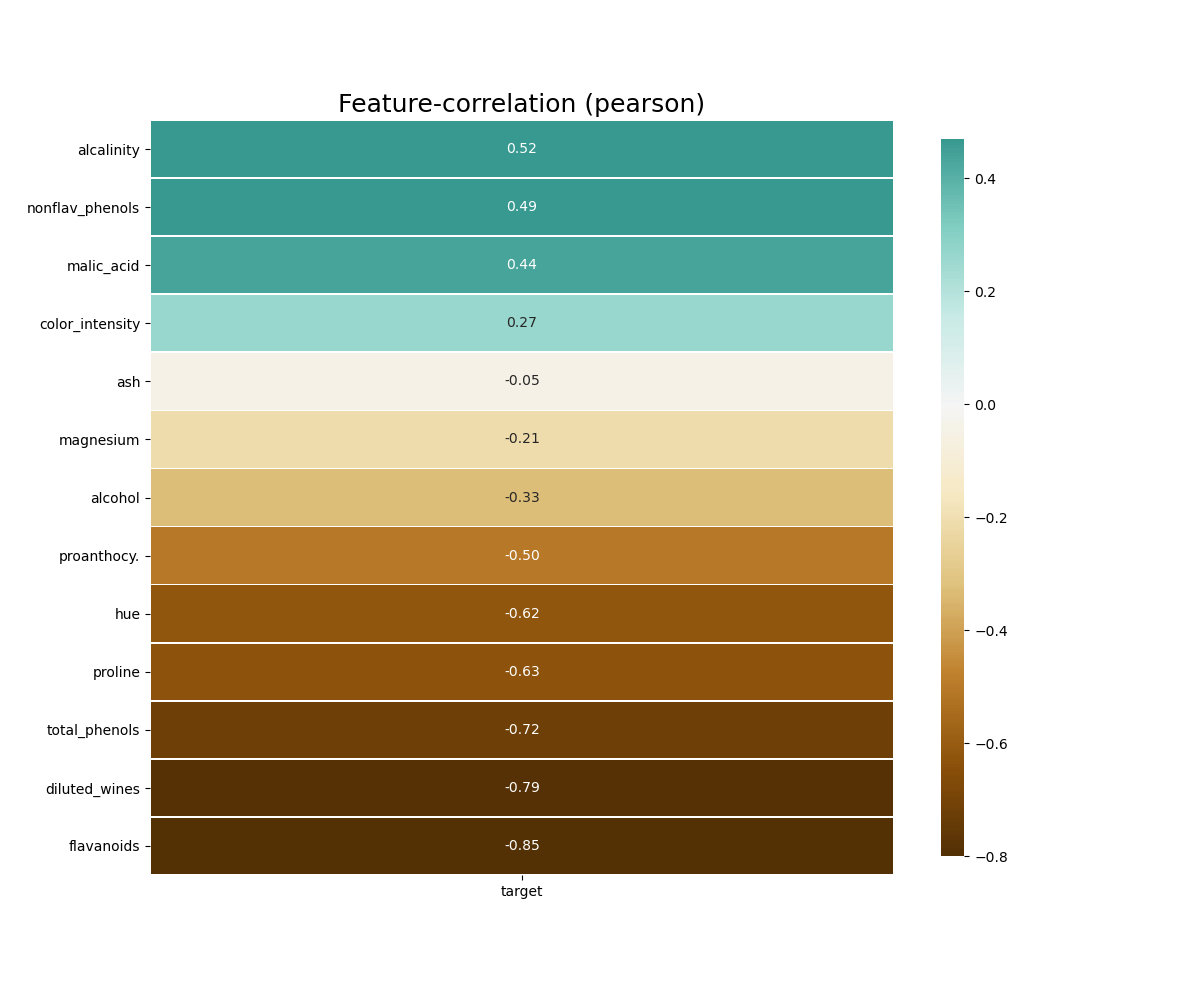
```python
klib.corr_plot(df, target='wine') # default representation of correlations with the feature column
```
```python
klib.dist_plot(df) # default representation of a distribution plot, other settings include fill_range, histogram, ...
```

```python
klib.cat_plot(data, top=4, bottom=4) # representation of the 4 most & least common values in each categorical column
```
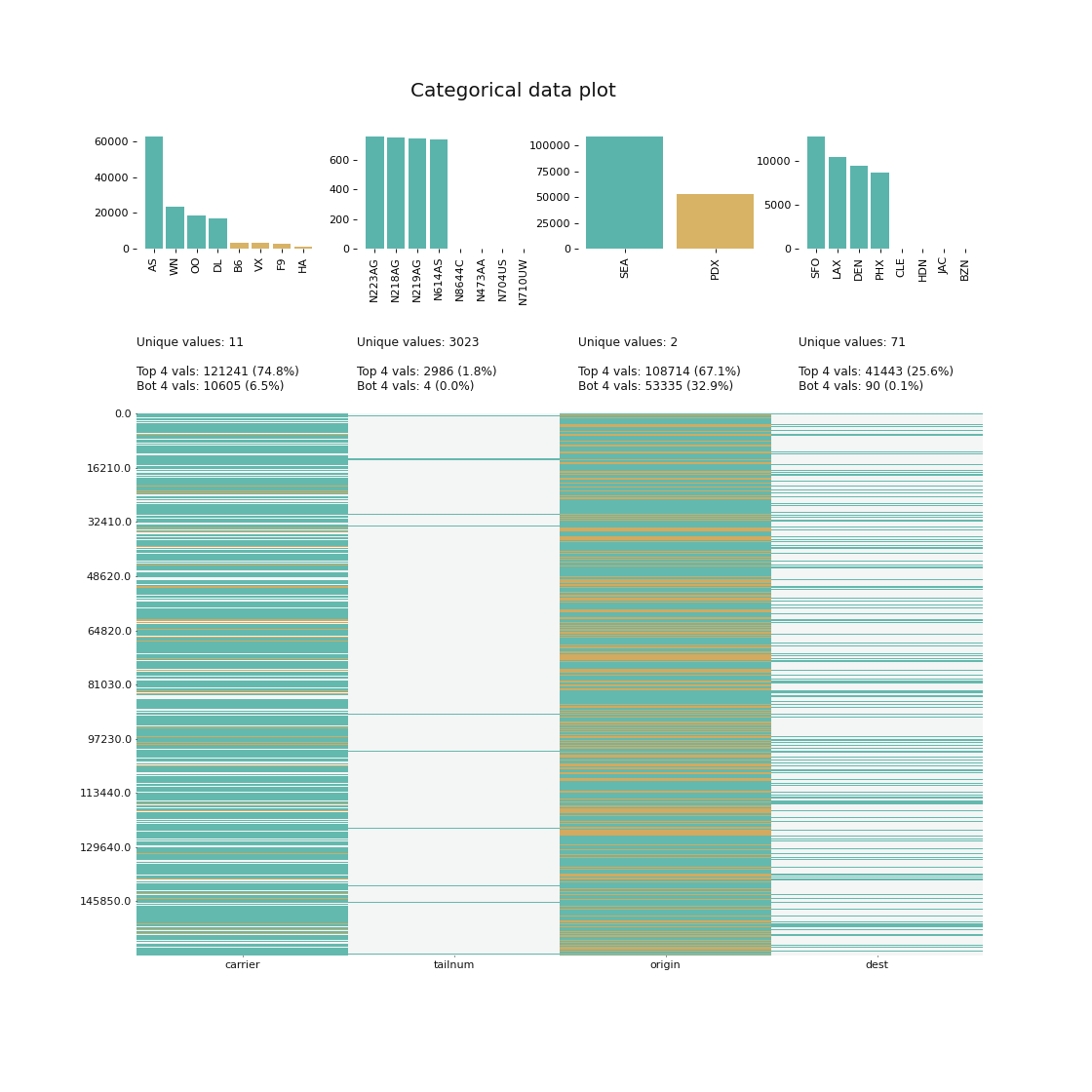
Further examples, as well as applications of the functions in **klib.clean()** can be found here.
## Contributing
[](https://open.vscode.dev/akanz1/klib)
Pull requests and ideas, especially for further functions are welcome. For major changes or feedback, please open an issue first to discuss what you would like to change.
## License
[MIT](https://choosealicense.com/licenses/mit/)
%package -n python3-klib
Summary: Customized data preprocessing functions for frequent tasks.
Provides: python-klib
BuildRequires: python3-devel
BuildRequires: python3-setuptools
BuildRequires: python3-pip
%description -n python3-klib
[](https://github.com/akanz1/klib)
[](https://pypi.org/project/klib/)
[](https://github.com/akanz1/klib/commits/main)
[](https://sonarcloud.io/dashboard?id=akanz1_klib)
[](https://scrutinizer-ci.com/g/akanz1/klib/)
[](https://codecov.io/gh/akanz1/klib)
**klib** is a Python library for importing, cleaning, analyzing and preprocessing data. Explanations on key functionalities can be found on [Medium / TowardsDataScience](https://medium.com/@akanz) and in the [examples](examples) section. Additionally, there are great introductions and overviews of the functionality on [PythonBytes](https://pythonbytes.fm/episodes/show/240/this-is-github-your-pilot-speaking) or on [YouTube (Data Professor)](https://www.youtube.com/watch?v=URjJVEeZxxU).
## Installation
Use the package manager [pip](https://pip.pypa.io/en/stable/) to install klib.
[](https://pypi.org/project/klib/)
[](https://pypi.org/project/klib/)
```bash
pip install -U klib
```
Alternatively, to install this package with conda run:
[](https://anaconda.org/conda-forge/klib)
[](https://anaconda.org/conda-forge/klib)
```bash
conda install -c conda-forge klib
```
## Usage
```python
import klib
import pandas as pd
df = pd.DataFrame(data)
# klib.describe - functions for visualizing datasets
- klib.cat_plot(df) # returns a visualization of the number and frequency of categorical features
- klib.corr_mat(df) # returns a color-encoded correlation matrix
- klib.corr_plot(df) # returns a color-encoded heatmap, ideal for correlations
- klib.dist_plot(df) # returns a distribution plot for every numeric feature
- klib.missingval_plot(df) # returns a figure containing information about missing values
# klib.clean - functions for cleaning datasets
- klib.data_cleaning(df) # performs datacleaning (drop duplicates & empty rows/cols, adjust dtypes,...)
- klib.clean_column_names(df) # cleans and standardizes column names, also called inside data_cleaning()
- klib.convert_datatypes(df) # converts existing to more efficient dtypes, also called inside data_cleaning()
- klib.drop_missing(df) # drops missing values, also called in data_cleaning()
- klib.mv_col_handling(df) # drops features with high ratio of missing vals based on informational content
- klib.pool_duplicate_subsets(df) # pools subset of cols based on duplicates with min. loss of information
```
## Examples
Find all available examples as well as applications of the functions in **klib.clean()** with detailed descriptions here.
```python
klib.missingval_plot(df) # default representation of missing values in a DataFrame, plenty of settings are available
```
```python
klib.corr_plot(df, split='pos') # displaying only positive correlations, other settings include threshold, cmap...
klib.corr_plot(df, split='neg') # displaying only negative correlations
```
```python
klib.corr_plot(df, target='wine') # default representation of correlations with the feature column
```
```python
klib.dist_plot(df) # default representation of a distribution plot, other settings include fill_range, histogram, ...
```
```python
klib.cat_plot(data, top=4, bottom=4) # representation of the 4 most & least common values in each categorical column
```
Further examples, as well as applications of the functions in **klib.clean()** can be found here.
## Contributing
[](https://open.vscode.dev/akanz1/klib)
Pull requests and ideas, especially for further functions are welcome. For major changes or feedback, please open an issue first to discuss what you would like to change.
## License
[MIT](https://choosealicense.com/licenses/mit/)
%package help
Summary: Development documents and examples for klib
Provides: python3-klib-doc
%description help
[](https://github.com/akanz1/klib)
[](https://pypi.org/project/klib/)
[](https://github.com/akanz1/klib/commits/main)
[](https://sonarcloud.io/dashboard?id=akanz1_klib)
[](https://scrutinizer-ci.com/g/akanz1/klib/)
[](https://codecov.io/gh/akanz1/klib)
**klib** is a Python library for importing, cleaning, analyzing and preprocessing data. Explanations on key functionalities can be found on [Medium / TowardsDataScience](https://medium.com/@akanz) and in the [examples](examples) section. Additionally, there are great introductions and overviews of the functionality on [PythonBytes](https://pythonbytes.fm/episodes/show/240/this-is-github-your-pilot-speaking) or on [YouTube (Data Professor)](https://www.youtube.com/watch?v=URjJVEeZxxU).
## Installation
Use the package manager [pip](https://pip.pypa.io/en/stable/) to install klib.
[](https://pypi.org/project/klib/)
[](https://pypi.org/project/klib/)
```bash
pip install -U klib
```
Alternatively, to install this package with conda run:
[](https://anaconda.org/conda-forge/klib)
[](https://anaconda.org/conda-forge/klib)
```bash
conda install -c conda-forge klib
```
## Usage
```python
import klib
import pandas as pd
df = pd.DataFrame(data)
# klib.describe - functions for visualizing datasets
- klib.cat_plot(df) # returns a visualization of the number and frequency of categorical features
- klib.corr_mat(df) # returns a color-encoded correlation matrix
- klib.corr_plot(df) # returns a color-encoded heatmap, ideal for correlations
- klib.dist_plot(df) # returns a distribution plot for every numeric feature
- klib.missingval_plot(df) # returns a figure containing information about missing values
# klib.clean - functions for cleaning datasets
- klib.data_cleaning(df) # performs datacleaning (drop duplicates & empty rows/cols, adjust dtypes,...)
- klib.clean_column_names(df) # cleans and standardizes column names, also called inside data_cleaning()
- klib.convert_datatypes(df) # converts existing to more efficient dtypes, also called inside data_cleaning()
- klib.drop_missing(df) # drops missing values, also called in data_cleaning()
- klib.mv_col_handling(df) # drops features with high ratio of missing vals based on informational content
- klib.pool_duplicate_subsets(df) # pools subset of cols based on duplicates with min. loss of information
```
## Examples
Find all available examples as well as applications of the functions in **klib.clean()** with detailed descriptions here.
```python
klib.missingval_plot(df) # default representation of missing values in a DataFrame, plenty of settings are available
```
```python
klib.corr_plot(df, split='pos') # displaying only positive correlations, other settings include threshold, cmap...
klib.corr_plot(df, split='neg') # displaying only negative correlations
```
```python
klib.corr_plot(df, target='wine') # default representation of correlations with the feature column
```
```python
klib.dist_plot(df) # default representation of a distribution plot, other settings include fill_range, histogram, ...
```
```python
klib.cat_plot(data, top=4, bottom=4) # representation of the 4 most & least common values in each categorical column
```
Further examples, as well as applications of the functions in **klib.clean()** can be found here.
## Contributing
[](https://open.vscode.dev/akanz1/klib)
Pull requests and ideas, especially for further functions are welcome. For major changes or feedback, please open an issue first to discuss what you would like to change.
## License
[MIT](https://choosealicense.com/licenses/mit/)
%prep
%autosetup -n klib-1.0.7
%build
%py3_build
%install
%py3_install
install -d -m755 %{buildroot}/%{_pkgdocdir}
if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi
if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi
if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi
if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi
pushd %{buildroot}
if [ -d usr/lib ]; then
find usr/lib -type f -printf "/%h/%f\n" >> filelist.lst
fi
if [ -d usr/lib64 ]; then
find usr/lib64 -type f -printf "/%h/%f\n" >> filelist.lst
fi
if [ -d usr/bin ]; then
find usr/bin -type f -printf "/%h/%f\n" >> filelist.lst
fi
if [ -d usr/sbin ]; then
find usr/sbin -type f -printf "/%h/%f\n" >> filelist.lst
fi
touch doclist.lst
if [ -d usr/share/man ]; then
find usr/share/man -type f -printf "/%h/%f.gz\n" >> doclist.lst
fi
popd
mv %{buildroot}/filelist.lst .
mv %{buildroot}/doclist.lst .
%files -n python3-klib -f filelist.lst
%dir %{python3_sitelib}/*
%files help -f doclist.lst
%{_docdir}/*
%changelog
* Tue May 30 2023 Python_Bot - 1.0.7-1
- Package Spec generated