%global _empty_manifest_terminate_build 0
Name: python-vietocr
Version: 0.3.11
Release: 1
Summary: Transformer base text detection
License: MIT License
URL: https://github.com/pbcquoc/vietocr
Source0: https://mirrors.aliyun.com/pypi/web/packages/c9/2a/3bc80074423f482390eba2d01b92d6f622ffc02fedbe5ccaaf6d99bb7c8e/vietocr-0.3.11.tar.gz
BuildArch: noarch
Requires: python3-einops
Requires: python3-gdown
Requires: python3-prefetch-generator
Requires: python3-imgaug
Requires: python3-lmdb
%description
# VietOCR
**Các bạn vui lòng cập nhật lên version vietocr>=0.3.8 để không xảy ra lỗi.**

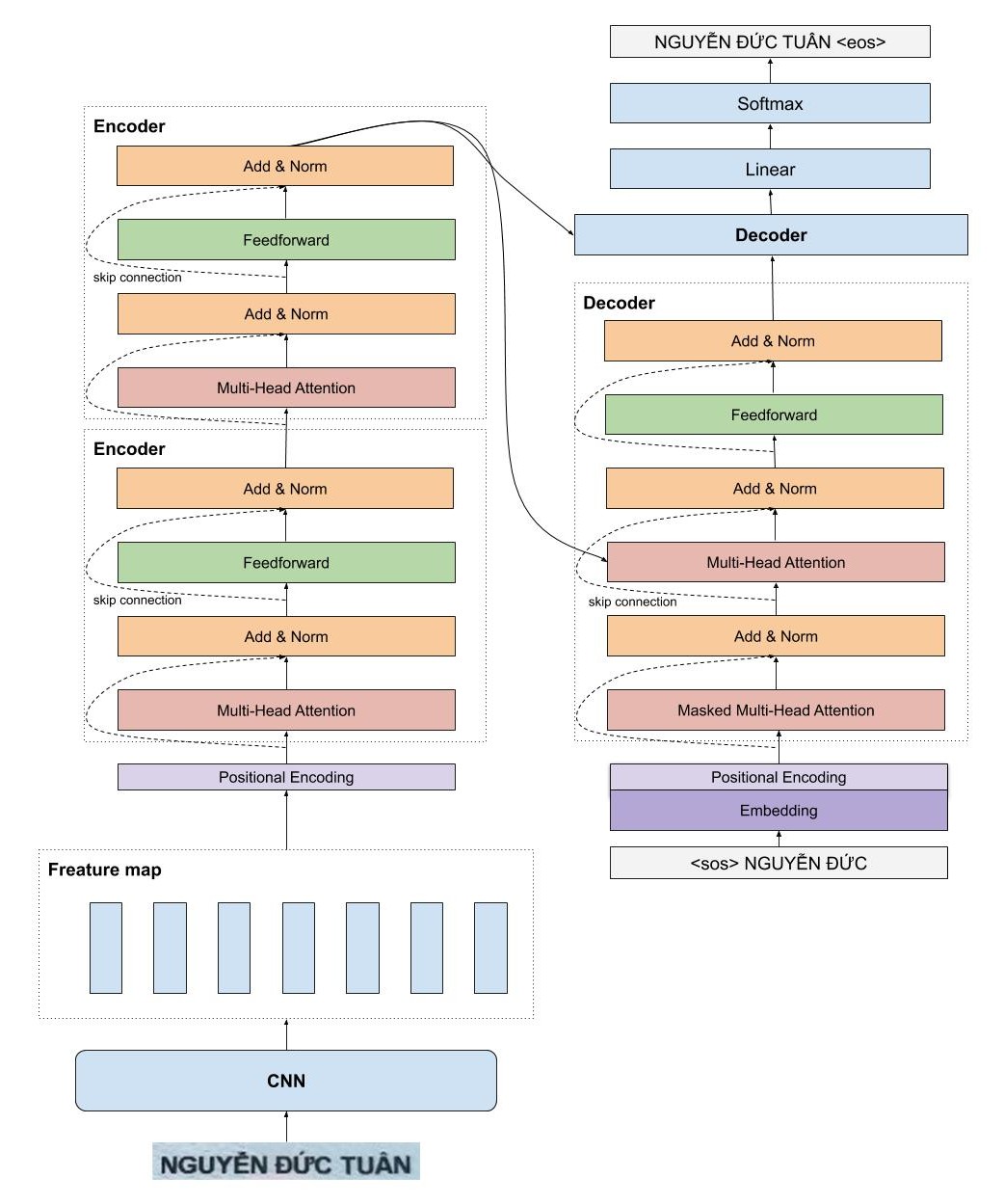
Trong project này, mình cài đặt mô hình Transformer OCR nhận dạng chữ viết tay, chữ đánh máy cho Tiếng Việt. Kiến trúc mô hình là sự kết hợp tuyệt vời giữ mô hình CNN và Transformer (là mô hình nền tảng của BERT khá nổi tiếng). Mô hình TransformerOCR có rất nhiều ưu điểm so với kiến trúc của mô hình CRNN đã được mình cài đặt. Các bạn có thể đọc [tại](https://pbcquoc.github.io/vietocr) đây về kiến trúc và cách huấn luyện mô hình với các tập dữ liệu khác nhau.
Mô hình VietOCR có tính tổng quát cực tốt, thậm chí có độ chính xác khá cao trên một bộ dataset mới mặc dù mô hình chưa được huấn luyện bao giờ.
# Cài Đặt
Để cài đặt các bạn gõ lệnh sau
```
pip install vietocr
```
# Quick Start
Các bạn tham khảo notebook [này](https://github.com/pbcquoc/vietocr/blob/master/vietocr_gettingstart.ipynb) để biết cách sử dụng nhé.
# Model Zoo
Thư viện này cài đặt cả 2 kiểu seq model đó là attention seq2seq và transfomer. Seq2seq có tốc độ dự đoán rất nhanh và được dùng trong industry khá nhiều, tuy nhiên transformer lại chính xác hơn nhưng lúc dự đoán lại khá chậm. Do đó mình cung cấp cả 2 loại cho các bạn lựa chọn.
Mô hình này được huấn luyện trên tập dữ liệu gồm 10m ảnh, bao gồm nhiều loại ảnh khác nhau như ảnh tự phát sinh, chữ viết tay, các văn bản scan thực tế.
Pretrain model được cung cấp sẵn.
# Kết quả thử nghiệm trên tập 10m
| Backbone | Config | Precision full sequence | time |
| ------------- |:-------------:| ---:|---:|
| VGG19-bn - Transformer | vgg_transformer | 0.8800 | 86ms @ 1080ti |
| VGG19-bn - Seq2Seq | vgg_seq2seq | 0.8701 | 12ms @ 1080ti |
Thời gian dự đoán của mô hình vgg-transformer quá lâu so với mô hình seq2seq, trong khi đó không có sự khác biệt rõ ràng giữ độ chính xác của 2 loại kiến trúc này.
# Dataset
Mình chỉ cung cấp tập dữ liệu mẫu khoảng 1m ảnh tự phát sinh. Các bạn có thể tải về tại [đây](https://drive.google.com/file/d/1T0cmkhTgu3ahyMIwGZeby612RpVdDxOR/view).
# License
Mình phát hành thư viện này dưới các điều khoản của [Apache 2.0 license]().
# Liên hệ
Nếu bạn có bất kì vấn đề gì, vui lòng tạo issue hoặc liên hệ mình tại pbcquoc@gmail.com
%package -n python3-vietocr
Summary: Transformer base text detection
Provides: python-vietocr
BuildRequires: python3-devel
BuildRequires: python3-setuptools
BuildRequires: python3-pip
%description -n python3-vietocr
# VietOCR
**Các bạn vui lòng cập nhật lên version vietocr>=0.3.8 để không xảy ra lỗi.**
Trong project này, mình cài đặt mô hình Transformer OCR nhận dạng chữ viết tay, chữ đánh máy cho Tiếng Việt. Kiến trúc mô hình là sự kết hợp tuyệt vời giữ mô hình CNN và Transformer (là mô hình nền tảng của BERT khá nổi tiếng). Mô hình TransformerOCR có rất nhiều ưu điểm so với kiến trúc của mô hình CRNN đã được mình cài đặt. Các bạn có thể đọc [tại](https://pbcquoc.github.io/vietocr) đây về kiến trúc và cách huấn luyện mô hình với các tập dữ liệu khác nhau.
Mô hình VietOCR có tính tổng quát cực tốt, thậm chí có độ chính xác khá cao trên một bộ dataset mới mặc dù mô hình chưa được huấn luyện bao giờ.
# Cài Đặt
Để cài đặt các bạn gõ lệnh sau
```
pip install vietocr
```
# Quick Start
Các bạn tham khảo notebook [này](https://github.com/pbcquoc/vietocr/blob/master/vietocr_gettingstart.ipynb) để biết cách sử dụng nhé.
# Model Zoo
Thư viện này cài đặt cả 2 kiểu seq model đó là attention seq2seq và transfomer. Seq2seq có tốc độ dự đoán rất nhanh và được dùng trong industry khá nhiều, tuy nhiên transformer lại chính xác hơn nhưng lúc dự đoán lại khá chậm. Do đó mình cung cấp cả 2 loại cho các bạn lựa chọn.
Mô hình này được huấn luyện trên tập dữ liệu gồm 10m ảnh, bao gồm nhiều loại ảnh khác nhau như ảnh tự phát sinh, chữ viết tay, các văn bản scan thực tế.
Pretrain model được cung cấp sẵn.
# Kết quả thử nghiệm trên tập 10m
| Backbone | Config | Precision full sequence | time |
| ------------- |:-------------:| ---:|---:|
| VGG19-bn - Transformer | vgg_transformer | 0.8800 | 86ms @ 1080ti |
| VGG19-bn - Seq2Seq | vgg_seq2seq | 0.8701 | 12ms @ 1080ti |
Thời gian dự đoán của mô hình vgg-transformer quá lâu so với mô hình seq2seq, trong khi đó không có sự khác biệt rõ ràng giữ độ chính xác của 2 loại kiến trúc này.
# Dataset
Mình chỉ cung cấp tập dữ liệu mẫu khoảng 1m ảnh tự phát sinh. Các bạn có thể tải về tại [đây](https://drive.google.com/file/d/1T0cmkhTgu3ahyMIwGZeby612RpVdDxOR/view).
# License
Mình phát hành thư viện này dưới các điều khoản của [Apache 2.0 license]().
# Liên hệ
Nếu bạn có bất kì vấn đề gì, vui lòng tạo issue hoặc liên hệ mình tại pbcquoc@gmail.com
%package help
Summary: Development documents and examples for vietocr
Provides: python3-vietocr-doc
%description help
# VietOCR
**Các bạn vui lòng cập nhật lên version vietocr>=0.3.8 để không xảy ra lỗi.**
Trong project này, mình cài đặt mô hình Transformer OCR nhận dạng chữ viết tay, chữ đánh máy cho Tiếng Việt. Kiến trúc mô hình là sự kết hợp tuyệt vời giữ mô hình CNN và Transformer (là mô hình nền tảng của BERT khá nổi tiếng). Mô hình TransformerOCR có rất nhiều ưu điểm so với kiến trúc của mô hình CRNN đã được mình cài đặt. Các bạn có thể đọc [tại](https://pbcquoc.github.io/vietocr) đây về kiến trúc và cách huấn luyện mô hình với các tập dữ liệu khác nhau.
Mô hình VietOCR có tính tổng quát cực tốt, thậm chí có độ chính xác khá cao trên một bộ dataset mới mặc dù mô hình chưa được huấn luyện bao giờ.
# Cài Đặt
Để cài đặt các bạn gõ lệnh sau
```
pip install vietocr
```
# Quick Start
Các bạn tham khảo notebook [này](https://github.com/pbcquoc/vietocr/blob/master/vietocr_gettingstart.ipynb) để biết cách sử dụng nhé.
# Model Zoo
Thư viện này cài đặt cả 2 kiểu seq model đó là attention seq2seq và transfomer. Seq2seq có tốc độ dự đoán rất nhanh và được dùng trong industry khá nhiều, tuy nhiên transformer lại chính xác hơn nhưng lúc dự đoán lại khá chậm. Do đó mình cung cấp cả 2 loại cho các bạn lựa chọn.
Mô hình này được huấn luyện trên tập dữ liệu gồm 10m ảnh, bao gồm nhiều loại ảnh khác nhau như ảnh tự phát sinh, chữ viết tay, các văn bản scan thực tế.
Pretrain model được cung cấp sẵn.
# Kết quả thử nghiệm trên tập 10m
| Backbone | Config | Precision full sequence | time |
| ------------- |:-------------:| ---:|---:|
| VGG19-bn - Transformer | vgg_transformer | 0.8800 | 86ms @ 1080ti |
| VGG19-bn - Seq2Seq | vgg_seq2seq | 0.8701 | 12ms @ 1080ti |
Thời gian dự đoán của mô hình vgg-transformer quá lâu so với mô hình seq2seq, trong khi đó không có sự khác biệt rõ ràng giữ độ chính xác của 2 loại kiến trúc này.
# Dataset
Mình chỉ cung cấp tập dữ liệu mẫu khoảng 1m ảnh tự phát sinh. Các bạn có thể tải về tại [đây](https://drive.google.com/file/d/1T0cmkhTgu3ahyMIwGZeby612RpVdDxOR/view).
# License
Mình phát hành thư viện này dưới các điều khoản của [Apache 2.0 license]().
# Liên hệ
Nếu bạn có bất kì vấn đề gì, vui lòng tạo issue hoặc liên hệ mình tại pbcquoc@gmail.com
%prep
%autosetup -n vietocr-0.3.11
%build
%py3_build
%install
%py3_install
install -d -m755 %{buildroot}/%{_pkgdocdir}
if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi
if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi
if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi
if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi
pushd %{buildroot}
if [ -d usr/lib ]; then
find usr/lib -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
if [ -d usr/lib64 ]; then
find usr/lib64 -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
if [ -d usr/bin ]; then
find usr/bin -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
if [ -d usr/sbin ]; then
find usr/sbin -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
touch doclist.lst
if [ -d usr/share/man ]; then
find usr/share/man -type f -printf "\"/%h/%f.gz\"\n" >> doclist.lst
fi
popd
mv %{buildroot}/filelist.lst .
mv %{buildroot}/doclist.lst .
%files -n python3-vietocr -f filelist.lst
%dir %{python3_sitelib}/*
%files help -f doclist.lst
%{_docdir}/*
%changelog
* Thu Jun 08 2023 Python_Bot - 0.3.11-1
- Package Spec generated