%global _empty_manifest_terminate_build 0
Name: python-konoha
Version: 5.4.0
Release: 1
Summary: A tiny sentence/word tokenizer for Japanese text written in Python
License: MIT
URL: https://pypi.org/project/konoha/
Source0: https://mirrors.nju.edu.cn/pypi/web/packages/f3/f1/a83f55d8e7e824d483bccce3902335d130b572b5a17bde8b282acd13d504/konoha-5.4.0.tar.gz
BuildArch: noarch
Requires: python3-importlib-metadata
Requires: python3-overrides
Requires: python3-janome
Requires: python3-natto-py
Requires: python3-kytea
Requires: python3-sentencepiece
Requires: python3-sudachipy
Requires: python3-boto3
Requires: python3-fastapi
Requires: python3-uvicorn
Requires: python3-sudachidict-core
Requires: python3-sphinx
Requires: python3-pydata-sphinx-theme
Requires: python3-nagisa
Requires: python3-rich
Requires: python3-requests
%description
# 🌿 Konoha: Simple wrapper of Japanese Tokenizers
[](https://colab.research.google.com/github/himkt/konoha/blob/main/example/Konoha_Example.ipynb)
[](https://github.com/himkt/konoha/stargazers)
[](https://pepy.tech/project/konoha)
[](https://pepy.tech/project/konoha/month)
[](https://pepy.tech/project/konoha/week)
[](https://github.com/himkt/konoha/actions)
[](https://konoha.readthedocs.io/en/latest/?badge=latest)

[](https://pypi.python.org/pypi/konoha)
[](https://github.com/himkt/konoha/issues)
[](https://github.com/himkt/konoha/issues)
`Konoha` is a Python library for providing easy-to-use integrated interface of various Japanese tokenizers,
which enables you to switch a tokenizer and boost your pre-processing.
## Supported tokenizers





 Also, `konoha` provides rule-based tokenizers (whitespace, character) and a rule-based sentence splitter.
## Quick Start with Docker
Simply run followings on your computer:
```bash
docker run --rm -p 8000:8000 -t himkt/konoha # from DockerHub
```
Or you can build image on your machine:
```bash
git clone https://github.com/himkt/konoha # download konoha
cd konoha && docker-compose up --build # build and launch container
```
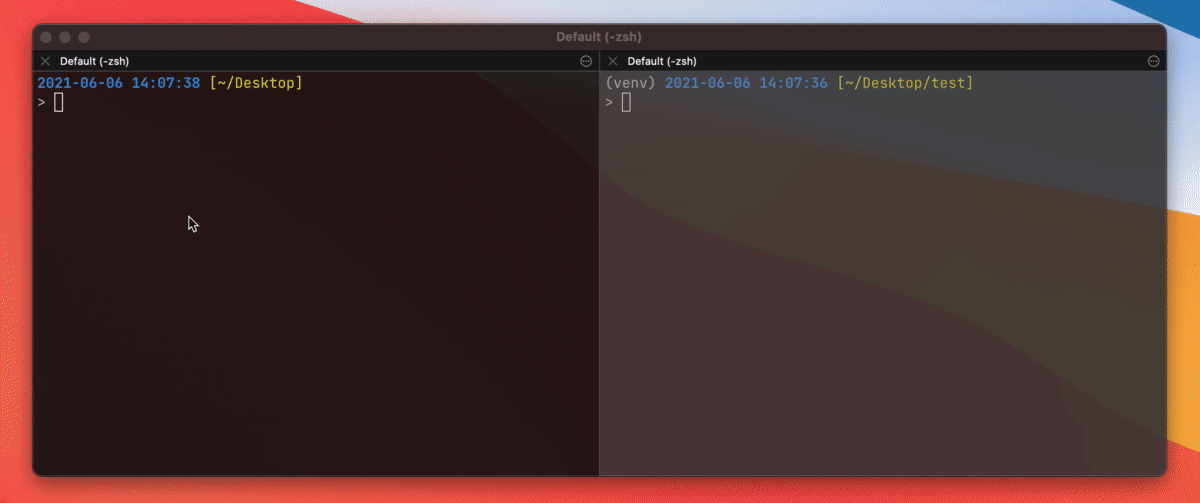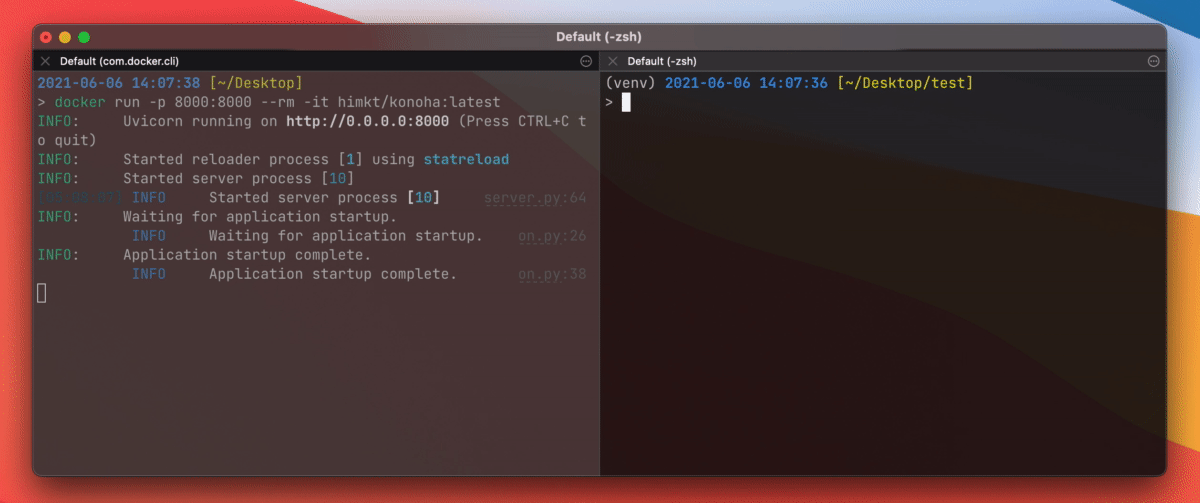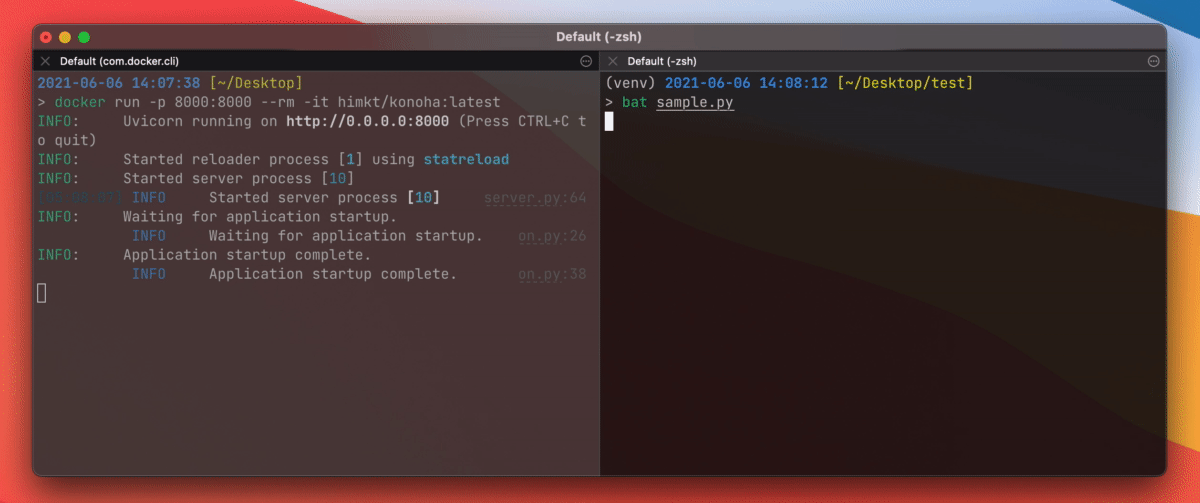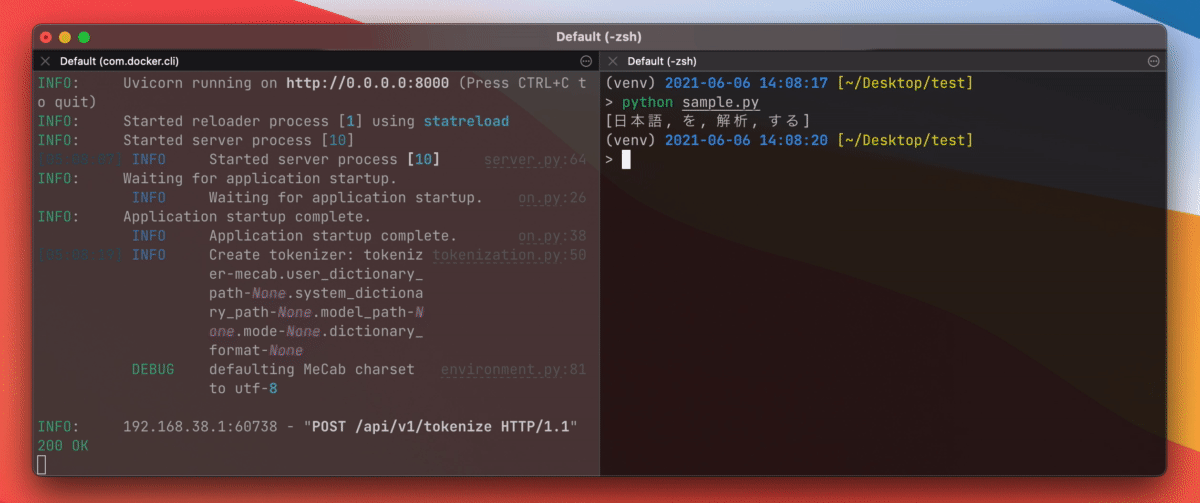
Tokenization is done by posting a json object to `localhost:8000/api/v1/tokenize`.
You can also batch tokenize by passing `texts: ["1つ目の入力", "2つ目の入力"]` to `localhost:8000/api/v1/batch_tokenize`.
(API documentation is available on `localhost:8000/redoc`, you can check it using your web browser)
Send a request using `curl` on your terminal.
Note that a path to an endpoint is changed in v4.6.4.
Please check our release note (https://github.com/himkt/konoha/releases/tag/v4.6.4).
```json
$ curl localhost:8000/api/v1/tokenize -X POST -H "Content-Type: application/json" \
-d '{"tokenizer": "mecab", "text": "これはペンです"}'
{
"tokens": [
[
{
"surface": "これ",
"part_of_speech": "名詞"
},
{
"surface": "は",
"part_of_speech": "助詞"
},
{
"surface": "ペン",
"part_of_speech": "名詞"
},
{
"surface": "です",
"part_of_speech": "助動詞"
}
]
]
}
```
## Installation
I recommend you to install konoha by `pip install 'konoha[all]'`.
- Install konoha with a specific tokenizer: `pip install 'konoha[(tokenizer_name)]`.
- Install konoha with a specific tokenizer and remote file support: `pip install 'konoha[(tokenizer_name),remote]'`
If you want to install konoha with a tokenizer, please install konoha with a specific tokenizer
(e.g. `konoha[mecab]`, `konoha[sudachi]`, ...etc) or install tokenizers individually.
## Example
### Word level tokenization
```python
from konoha import WordTokenizer
sentence = '自然言語処理を勉強しています'
tokenizer = WordTokenizer('MeCab')
print(tokenizer.tokenize(sentence))
# => [自然, 言語, 処理, を, 勉強, し, て, い, ます]
tokenizer = WordTokenizer('Sentencepiece', model_path="data/model.spm")
print(tokenizer.tokenize(sentence))
# => [▁, 自然, 言語, 処理, を, 勉強, し, ています]
```
For more detail, please see the `example/` directory.
### Remote files
Konoha supports dictionary and model on cloud storage (currently supports Amazon S3).
It requires installing konoha with the `remote` option, see [Installation](#installation).
```python
# download user dictionary from S3
word_tokenizer = WordTokenizer("mecab", user_dictionary_path="s3://abc/xxx.dic")
print(word_tokenizer.tokenize(sentence))
# download system dictionary from S3
word_tokenizer = WordTokenizer("mecab", system_dictionary_path="s3://abc/yyy")
print(word_tokenizer.tokenize(sentence))
# download model file from S3
word_tokenizer = WordTokenizer("sentencepiece", model_path="s3://abc/zzz.model")
print(word_tokenizer.tokenize(sentence))
```
### Sentence level tokenization
```python
from konoha import SentenceTokenizer
sentence = "私は猫だ。名前なんてものはない。だが,「かわいい。それで十分だろう」。"
tokenizer = SentenceTokenizer()
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。', '名前なんてものはない。', 'だが,「かわいい。それで十分だろう」。']
```
You can change symbols for a sentence splitter and bracket expression.
1. sentence splitter
```python
sentence = "私は猫だ。名前なんてものはない.だが,「かわいい。それで十分だろう」。"
tokenizer = SentenceTokenizer(period=".")
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。名前なんてものはない.', 'だが,「かわいい。それで十分だろう」。']
```
2. bracket expression
```python
sentence = "私は猫だ。名前なんてものはない。だが,『かわいい。それで十分だろう』。"
tokenizer = SentenceTokenizer(
patterns=SentenceTokenizer.PATTERNS + [re.compile(r"『.*?』")],
)
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。', '名前なんてものはない。', 'だが,『かわいい。それで十分だろう』。']
```
## Test
```
python -m pytest
```
## Article
- [トークナイザをいい感じに切り替えるライブラリ konoha を作った](https://qiita.com/klis/items/bb9ffa4d9c886af0f531)
- [日本語解析ツール Konoha に AllenNLP 連携機能を実装した](https://qiita.com/klis/items/f1d29cb431d1bf879898)
## Acknowledgement
Sentencepiece model used in test is provided by @yoheikikuta. Thanks!
%package -n python3-konoha
Summary: A tiny sentence/word tokenizer for Japanese text written in Python
Provides: python-konoha
BuildRequires: python3-devel
BuildRequires: python3-setuptools
BuildRequires: python3-pip
%description -n python3-konoha
# 🌿 Konoha: Simple wrapper of Japanese Tokenizers
[](https://colab.research.google.com/github/himkt/konoha/blob/main/example/Konoha_Example.ipynb)
Also, `konoha` provides rule-based tokenizers (whitespace, character) and a rule-based sentence splitter.
## Quick Start with Docker
Simply run followings on your computer:
```bash
docker run --rm -p 8000:8000 -t himkt/konoha # from DockerHub
```
Or you can build image on your machine:
```bash
git clone https://github.com/himkt/konoha # download konoha
cd konoha && docker-compose up --build # build and launch container
```
Tokenization is done by posting a json object to `localhost:8000/api/v1/tokenize`.
You can also batch tokenize by passing `texts: ["1つ目の入力", "2つ目の入力"]` to `localhost:8000/api/v1/batch_tokenize`.
(API documentation is available on `localhost:8000/redoc`, you can check it using your web browser)
Send a request using `curl` on your terminal.
Note that a path to an endpoint is changed in v4.6.4.
Please check our release note (https://github.com/himkt/konoha/releases/tag/v4.6.4).
```json
$ curl localhost:8000/api/v1/tokenize -X POST -H "Content-Type: application/json" \
-d '{"tokenizer": "mecab", "text": "これはペンです"}'
{
"tokens": [
[
{
"surface": "これ",
"part_of_speech": "名詞"
},
{
"surface": "は",
"part_of_speech": "助詞"
},
{
"surface": "ペン",
"part_of_speech": "名詞"
},
{
"surface": "です",
"part_of_speech": "助動詞"
}
]
]
}
```
## Installation
I recommend you to install konoha by `pip install 'konoha[all]'`.
- Install konoha with a specific tokenizer: `pip install 'konoha[(tokenizer_name)]`.
- Install konoha with a specific tokenizer and remote file support: `pip install 'konoha[(tokenizer_name),remote]'`
If you want to install konoha with a tokenizer, please install konoha with a specific tokenizer
(e.g. `konoha[mecab]`, `konoha[sudachi]`, ...etc) or install tokenizers individually.
## Example
### Word level tokenization
```python
from konoha import WordTokenizer
sentence = '自然言語処理を勉強しています'
tokenizer = WordTokenizer('MeCab')
print(tokenizer.tokenize(sentence))
# => [自然, 言語, 処理, を, 勉強, し, て, い, ます]
tokenizer = WordTokenizer('Sentencepiece', model_path="data/model.spm")
print(tokenizer.tokenize(sentence))
# => [▁, 自然, 言語, 処理, を, 勉強, し, ています]
```
For more detail, please see the `example/` directory.
### Remote files
Konoha supports dictionary and model on cloud storage (currently supports Amazon S3).
It requires installing konoha with the `remote` option, see [Installation](#installation).
```python
# download user dictionary from S3
word_tokenizer = WordTokenizer("mecab", user_dictionary_path="s3://abc/xxx.dic")
print(word_tokenizer.tokenize(sentence))
# download system dictionary from S3
word_tokenizer = WordTokenizer("mecab", system_dictionary_path="s3://abc/yyy")
print(word_tokenizer.tokenize(sentence))
# download model file from S3
word_tokenizer = WordTokenizer("sentencepiece", model_path="s3://abc/zzz.model")
print(word_tokenizer.tokenize(sentence))
```
### Sentence level tokenization
```python
from konoha import SentenceTokenizer
sentence = "私は猫だ。名前なんてものはない。だが,「かわいい。それで十分だろう」。"
tokenizer = SentenceTokenizer()
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。', '名前なんてものはない。', 'だが,「かわいい。それで十分だろう」。']
```
You can change symbols for a sentence splitter and bracket expression.
1. sentence splitter
```python
sentence = "私は猫だ。名前なんてものはない.だが,「かわいい。それで十分だろう」。"
tokenizer = SentenceTokenizer(period=".")
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。名前なんてものはない.', 'だが,「かわいい。それで十分だろう」。']
```
2. bracket expression
```python
sentence = "私は猫だ。名前なんてものはない。だが,『かわいい。それで十分だろう』。"
tokenizer = SentenceTokenizer(
patterns=SentenceTokenizer.PATTERNS + [re.compile(r"『.*?』")],
)
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。', '名前なんてものはない。', 'だが,『かわいい。それで十分だろう』。']
```
## Test
```
python -m pytest
```
## Article
- [トークナイザをいい感じに切り替えるライブラリ konoha を作った](https://qiita.com/klis/items/bb9ffa4d9c886af0f531)
- [日本語解析ツール Konoha に AllenNLP 連携機能を実装した](https://qiita.com/klis/items/f1d29cb431d1bf879898)
## Acknowledgement
Sentencepiece model used in test is provided by @yoheikikuta. Thanks!
%package -n python3-konoha
Summary: A tiny sentence/word tokenizer for Japanese text written in Python
Provides: python-konoha
BuildRequires: python3-devel
BuildRequires: python3-setuptools
BuildRequires: python3-pip
%description -n python3-konoha
# 🌿 Konoha: Simple wrapper of Japanese Tokenizers
[](https://colab.research.google.com/github/himkt/konoha/blob/main/example/Konoha_Example.ipynb)
[](https://github.com/himkt/konoha/stargazers)
[](https://pepy.tech/project/konoha)
[](https://pepy.tech/project/konoha/month)
[](https://pepy.tech/project/konoha/week)
[](https://github.com/himkt/konoha/actions)
[](https://konoha.readthedocs.io/en/latest/?badge=latest)

[](https://pypi.python.org/pypi/konoha)
[](https://github.com/himkt/konoha/issues)
[](https://github.com/himkt/konoha/issues)
`Konoha` is a Python library for providing easy-to-use integrated interface of various Japanese tokenizers,
which enables you to switch a tokenizer and boost your pre-processing.
## Supported tokenizers
Also, `konoha` provides rule-based tokenizers (whitespace, character) and a rule-based sentence splitter.
## Quick Start with Docker
Simply run followings on your computer:
```bash
docker run --rm -p 8000:8000 -t himkt/konoha # from DockerHub
```
Or you can build image on your machine:
```bash
git clone https://github.com/himkt/konoha # download konoha
cd konoha && docker-compose up --build # build and launch container
```
Tokenization is done by posting a json object to `localhost:8000/api/v1/tokenize`.
You can also batch tokenize by passing `texts: ["1つ目の入力", "2つ目の入力"]` to `localhost:8000/api/v1/batch_tokenize`.
(API documentation is available on `localhost:8000/redoc`, you can check it using your web browser)
Send a request using `curl` on your terminal.
Note that a path to an endpoint is changed in v4.6.4.
Please check our release note (https://github.com/himkt/konoha/releases/tag/v4.6.4).
```json
$ curl localhost:8000/api/v1/tokenize -X POST -H "Content-Type: application/json" \
-d '{"tokenizer": "mecab", "text": "これはペンです"}'
{
"tokens": [
[
{
"surface": "これ",
"part_of_speech": "名詞"
},
{
"surface": "は",
"part_of_speech": "助詞"
},
{
"surface": "ペン",
"part_of_speech": "名詞"
},
{
"surface": "です",
"part_of_speech": "助動詞"
}
]
]
}
```
## Installation
I recommend you to install konoha by `pip install 'konoha[all]'`.
- Install konoha with a specific tokenizer: `pip install 'konoha[(tokenizer_name)]`.
- Install konoha with a specific tokenizer and remote file support: `pip install 'konoha[(tokenizer_name),remote]'`
If you want to install konoha with a tokenizer, please install konoha with a specific tokenizer
(e.g. `konoha[mecab]`, `konoha[sudachi]`, ...etc) or install tokenizers individually.
## Example
### Word level tokenization
```python
from konoha import WordTokenizer
sentence = '自然言語処理を勉強しています'
tokenizer = WordTokenizer('MeCab')
print(tokenizer.tokenize(sentence))
# => [自然, 言語, 処理, を, 勉強, し, て, い, ます]
tokenizer = WordTokenizer('Sentencepiece', model_path="data/model.spm")
print(tokenizer.tokenize(sentence))
# => [▁, 自然, 言語, 処理, を, 勉強, し, ています]
```
For more detail, please see the `example/` directory.
### Remote files
Konoha supports dictionary and model on cloud storage (currently supports Amazon S3).
It requires installing konoha with the `remote` option, see [Installation](#installation).
```python
# download user dictionary from S3
word_tokenizer = WordTokenizer("mecab", user_dictionary_path="s3://abc/xxx.dic")
print(word_tokenizer.tokenize(sentence))
# download system dictionary from S3
word_tokenizer = WordTokenizer("mecab", system_dictionary_path="s3://abc/yyy")
print(word_tokenizer.tokenize(sentence))
# download model file from S3
word_tokenizer = WordTokenizer("sentencepiece", model_path="s3://abc/zzz.model")
print(word_tokenizer.tokenize(sentence))
```
### Sentence level tokenization
```python
from konoha import SentenceTokenizer
sentence = "私は猫だ。名前なんてものはない。だが,「かわいい。それで十分だろう」。"
tokenizer = SentenceTokenizer()
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。', '名前なんてものはない。', 'だが,「かわいい。それで十分だろう」。']
```
You can change symbols for a sentence splitter and bracket expression.
1. sentence splitter
```python
sentence = "私は猫だ。名前なんてものはない.だが,「かわいい。それで十分だろう」。"
tokenizer = SentenceTokenizer(period=".")
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。名前なんてものはない.', 'だが,「かわいい。それで十分だろう」。']
```
2. bracket expression
```python
sentence = "私は猫だ。名前なんてものはない。だが,『かわいい。それで十分だろう』。"
tokenizer = SentenceTokenizer(
patterns=SentenceTokenizer.PATTERNS + [re.compile(r"『.*?』")],
)
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。', '名前なんてものはない。', 'だが,『かわいい。それで十分だろう』。']
```
## Test
```
python -m pytest
```
## Article
- [トークナイザをいい感じに切り替えるライブラリ konoha を作った](https://qiita.com/klis/items/bb9ffa4d9c886af0f531)
- [日本語解析ツール Konoha に AllenNLP 連携機能を実装した](https://qiita.com/klis/items/f1d29cb431d1bf879898)
## Acknowledgement
Sentencepiece model used in test is provided by @yoheikikuta. Thanks!
%package help
Summary: Development documents and examples for konoha
Provides: python3-konoha-doc
%description help
# 🌿 Konoha: Simple wrapper of Japanese Tokenizers
[](https://colab.research.google.com/github/himkt/konoha/blob/main/example/Konoha_Example.ipynb)
[](https://github.com/himkt/konoha/stargazers)
[](https://pepy.tech/project/konoha)
[](https://pepy.tech/project/konoha/month)
[](https://pepy.tech/project/konoha/week)
[](https://github.com/himkt/konoha/actions)
[](https://konoha.readthedocs.io/en/latest/?badge=latest)

[](https://pypi.python.org/pypi/konoha)
[](https://github.com/himkt/konoha/issues)
[](https://github.com/himkt/konoha/issues)
`Konoha` is a Python library for providing easy-to-use integrated interface of various Japanese tokenizers,
which enables you to switch a tokenizer and boost your pre-processing.
## Supported tokenizers
Also, `konoha` provides rule-based tokenizers (whitespace, character) and a rule-based sentence splitter.
## Quick Start with Docker
Simply run followings on your computer:
```bash
docker run --rm -p 8000:8000 -t himkt/konoha # from DockerHub
```
Or you can build image on your machine:
```bash
git clone https://github.com/himkt/konoha # download konoha
cd konoha && docker-compose up --build # build and launch container
```
Tokenization is done by posting a json object to `localhost:8000/api/v1/tokenize`.
You can also batch tokenize by passing `texts: ["1つ目の入力", "2つ目の入力"]` to `localhost:8000/api/v1/batch_tokenize`.
(API documentation is available on `localhost:8000/redoc`, you can check it using your web browser)
Send a request using `curl` on your terminal.
Note that a path to an endpoint is changed in v4.6.4.
Please check our release note (https://github.com/himkt/konoha/releases/tag/v4.6.4).
```json
$ curl localhost:8000/api/v1/tokenize -X POST -H "Content-Type: application/json" \
-d '{"tokenizer": "mecab", "text": "これはペンです"}'
{
"tokens": [
[
{
"surface": "これ",
"part_of_speech": "名詞"
},
{
"surface": "は",
"part_of_speech": "助詞"
},
{
"surface": "ペン",
"part_of_speech": "名詞"
},
{
"surface": "です",
"part_of_speech": "助動詞"
}
]
]
}
```
## Installation
I recommend you to install konoha by `pip install 'konoha[all]'`.
- Install konoha with a specific tokenizer: `pip install 'konoha[(tokenizer_name)]`.
- Install konoha with a specific tokenizer and remote file support: `pip install 'konoha[(tokenizer_name),remote]'`
If you want to install konoha with a tokenizer, please install konoha with a specific tokenizer
(e.g. `konoha[mecab]`, `konoha[sudachi]`, ...etc) or install tokenizers individually.
## Example
### Word level tokenization
```python
from konoha import WordTokenizer
sentence = '自然言語処理を勉強しています'
tokenizer = WordTokenizer('MeCab')
print(tokenizer.tokenize(sentence))
# => [自然, 言語, 処理, を, 勉強, し, て, い, ます]
tokenizer = WordTokenizer('Sentencepiece', model_path="data/model.spm")
print(tokenizer.tokenize(sentence))
# => [▁, 自然, 言語, 処理, を, 勉強, し, ています]
```
For more detail, please see the `example/` directory.
### Remote files
Konoha supports dictionary and model on cloud storage (currently supports Amazon S3).
It requires installing konoha with the `remote` option, see [Installation](#installation).
```python
# download user dictionary from S3
word_tokenizer = WordTokenizer("mecab", user_dictionary_path="s3://abc/xxx.dic")
print(word_tokenizer.tokenize(sentence))
# download system dictionary from S3
word_tokenizer = WordTokenizer("mecab", system_dictionary_path="s3://abc/yyy")
print(word_tokenizer.tokenize(sentence))
# download model file from S3
word_tokenizer = WordTokenizer("sentencepiece", model_path="s3://abc/zzz.model")
print(word_tokenizer.tokenize(sentence))
```
### Sentence level tokenization
```python
from konoha import SentenceTokenizer
sentence = "私は猫だ。名前なんてものはない。だが,「かわいい。それで十分だろう」。"
tokenizer = SentenceTokenizer()
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。', '名前なんてものはない。', 'だが,「かわいい。それで十分だろう」。']
```
You can change symbols for a sentence splitter and bracket expression.
1. sentence splitter
```python
sentence = "私は猫だ。名前なんてものはない.だが,「かわいい。それで十分だろう」。"
tokenizer = SentenceTokenizer(period=".")
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。名前なんてものはない.', 'だが,「かわいい。それで十分だろう」。']
```
2. bracket expression
```python
sentence = "私は猫だ。名前なんてものはない。だが,『かわいい。それで十分だろう』。"
tokenizer = SentenceTokenizer(
patterns=SentenceTokenizer.PATTERNS + [re.compile(r"『.*?』")],
)
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。', '名前なんてものはない。', 'だが,『かわいい。それで十分だろう』。']
```
## Test
```
python -m pytest
```
## Article
- [トークナイザをいい感じに切り替えるライブラリ konoha を作った](https://qiita.com/klis/items/bb9ffa4d9c886af0f531)
- [日本語解析ツール Konoha に AllenNLP 連携機能を実装した](https://qiita.com/klis/items/f1d29cb431d1bf879898)
## Acknowledgement
Sentencepiece model used in test is provided by @yoheikikuta. Thanks!
%prep
%autosetup -n konoha-5.4.0
%build
%py3_build
%install
%py3_install
install -d -m755 %{buildroot}/%{_pkgdocdir}
if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi
if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi
if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi
if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi
pushd %{buildroot}
if [ -d usr/lib ]; then
find usr/lib -type f -printf "/%h/%f\n" >> filelist.lst
fi
if [ -d usr/lib64 ]; then
find usr/lib64 -type f -printf "/%h/%f\n" >> filelist.lst
fi
if [ -d usr/bin ]; then
find usr/bin -type f -printf "/%h/%f\n" >> filelist.lst
fi
if [ -d usr/sbin ]; then
find usr/sbin -type f -printf "/%h/%f\n" >> filelist.lst
fi
touch doclist.lst
if [ -d usr/share/man ]; then
find usr/share/man -type f -printf "/%h/%f.gz\n" >> doclist.lst
fi
popd
mv %{buildroot}/filelist.lst .
mv %{buildroot}/doclist.lst .
%files -n python3-konoha -f filelist.lst
%dir %{python3_sitelib}/*
%files help -f doclist.lst
%{_docdir}/*
%changelog
* Mon Apr 10 2023 Python_Bot - 5.4.0-1
- Package Spec generated