%global _empty_manifest_terminate_build 0
Name: python-dbt-exposures-crawler
Version: 0.1.4
Release: 1
Summary: Extracts information from different systems and convert them to dbt exposures
License: Apache License, Version 2.0
URL: https://github.com/voi-oss/dbt-exposures-crawler
Source0: https://mirrors.aliyun.com/pypi/web/packages/24/5b/9149959bf6426f3bd0a838660e62f28a285d809699047cdefeb61599a0dd/dbt-exposures-crawler-0.1.4.tar.gz
BuildArch: noarch
Requires: python3-click
Requires: python3-slugify
Requires: python3-tableauserverclient
%description
# dbt exposures crawler
[](https://badge.fury.io/py/dbt-exposures-crawler)
[](https://github.com/voi-oss/dbt-exposures-crawler/actions/workflows/run-tests.yaml)
[](https://github.com/voi-oss/dbt-exposures-crawler/actions/workflows/run-code-checks.yaml)
[](https://codecov.io/gh/voi-oss/dbt-exposures-crawler)
[](https://github.com/voi-oss/dbt-exposures-crawler/)
Automates the creation of dbt exposures from different sources. Currently, only Tableau workbooks using Snowflake SQL
are supported as a source.
> This project is in an ALPHA stage. Internal and external APIs might change between minor versions.
> Please reach out if you try this at your own organization. Feedback is very appreciated, and we
> would love to hear if you had any issues setting this up at your own.
## Installation
This project requires Python 3.8+. We have tested it internally with dbt 1.x, Tableau Server 2022.1 and Snowflake SQL
dialect.
You can install the latest version of this package from PyPI by running the command below. Usage instructions can be
found further below in this document.
```shell
$ pip install dbt-exposures-crawler
```
## Motivation
[dbt](https://www.getdbt.com/) is an open-source tool to manage data transformations in SQL. It automatically generates
a documentation portal from your project which includes a dependency lineage graph. It is possible to add external
downstream dependencies to this graph (such as a dashboard on a Business Intelligence tool) through a dbt feature called
[exposures](https://docs.getdbt.com/docs/building-a-dbt-project/exposures), which are normally defined through `yaml`
files.
This project automates the creation of exposures by implementing crawlers to parse the metadata of downstream tools.
Currently, only Tableau dashboards are supported, but we have plans to include Metabase as well.
A few use cases on how having exposures can help:
* analysts working on a model can use the exposures to perform impact analysis and see which reports might be impacted
by their changes;
* report consumers can find their report on dbt and see which models are used and read their documentation;
* report consumers can find which other reports are using the same models as their favorite reports.
## How it works
Summary:
1. Retrieve dbt models and sources from `manifest.json`;
2. Extract metadata (custom SQL and table references) from Tableau workbooks using their GraphQL API);
3. Try to find occurrences from the dbt models and sources in the Tableau SQL;
4. Use the Tableau REST API to retrieve additional information about the workbooks (author, project, etc);
5. Create the dbt exposures (in-memory) and write it back to the `manifest.json`.
More in-depth explanation:
First, you must provide the path to a dbt project [manifest](https://docs.getdbt.com/reference/artifacts/manifest-json).
The metadata and fully qualified names (database, schema and object name) are extracted from all dbt models and sources
represented in the manifest. The combination of dbt models and dbt sources will from now on be referred as dbt nodes.
Next, workbook metadata is extracted from Tableau using
their [Metadata API](https://help.tableau.com/current/api/metadata_api/en-us/index.html), including workbooks that use
custom SQL queries and workbooks that don't (which are referred in this project as "native SQL" workbooks). Note that
this API is included in all Tableau licenses (i.e. it does not require the Data Management Add-on), but must
be [manually enabled](https://help.tableau.com/current/api/metadata_api/en-us/docs/meta_api_start.html#enable)
if you host your own Tableau Server.
The SQL from the custom SQL workbooks and the table names from the native SQL workbooks are normalized through simple
heuristics, such as removing quotes and converting the custom SQL to lowercase. Now that both normalized SQL and
normalized table names from Tableau, and the fully qualified names for the dbt nodes are available, the project tries to
find the occurrences of the latter in the former.
The result of the above is a mapping of workbooks and which dbt nodes they depend on. For every workbook (with mapped
dependencies available), extra metadata that was not available in the Metadata API is then retrieved from Tableau by
using their [REST API](https://help.tableau.com/current/api/rest_api/en-us/REST/rest_api.htm), including when the
workbook was created, when it was last updated, to which folder it belongs on Tableau and information about the author
of the workbook.
As a final step, the information above is written back in the provided `manifest.json` in the form of exposures. Note
that instead of generating `.yaml` files for each exposure, they are written directly on the `manifest.json`.
## Example
To better understand how the project works, let's take as an example
the [jaffle_shop](https://github.com/fishtown-analytics/jaffle_shop) dbt sample project. It has, among other models,
a `customers` and an `orders` model.
Now suppose that you company has 4 workbooks on Tableau:
* Customers workbook: accesses the `customers` dbt model through custom SQL;
* Company KPIs workbook: accesses both models through custom SQL;
* Orders workbook: accesses the `orders` model without custom SQL;
* Unrelated workbook: a workbook that does not use the dbt project but instead has a static data source.
When running this project, you would get the following console output:
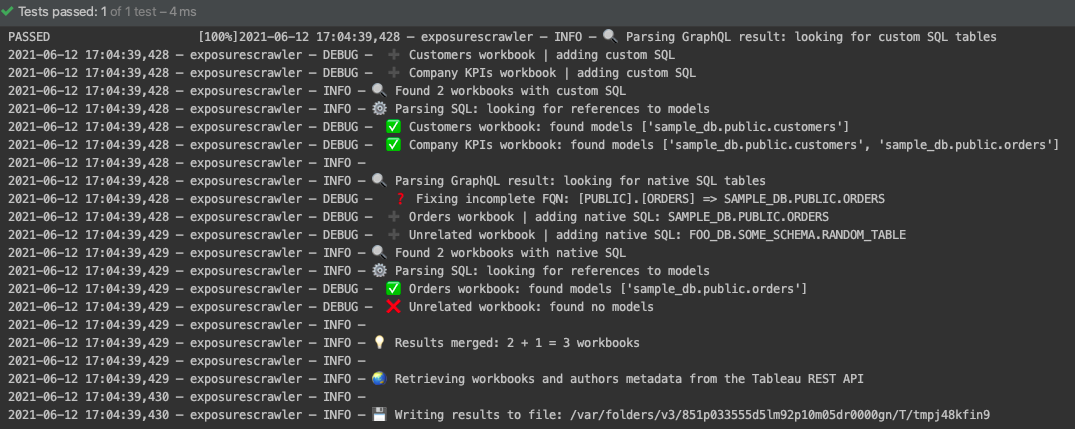
The `manifest.json` that you provided would have 3 new exposures added to it, such as:
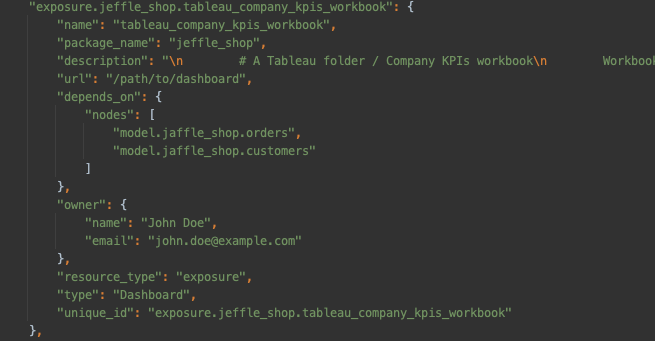
Those exposures can then be visualized through your dbt documentation portal, either by finding which exposures are
downstream dependencies of a certain model:
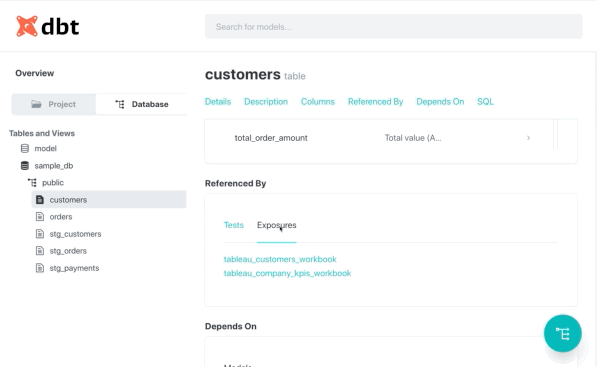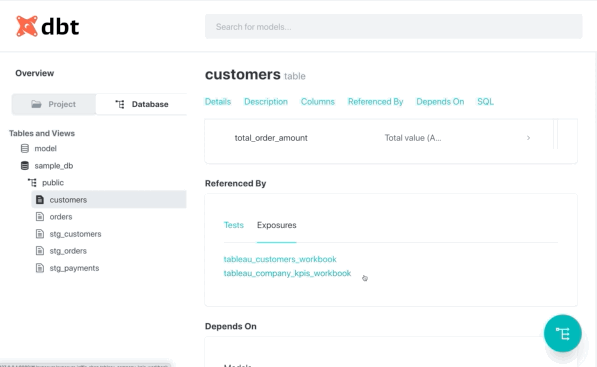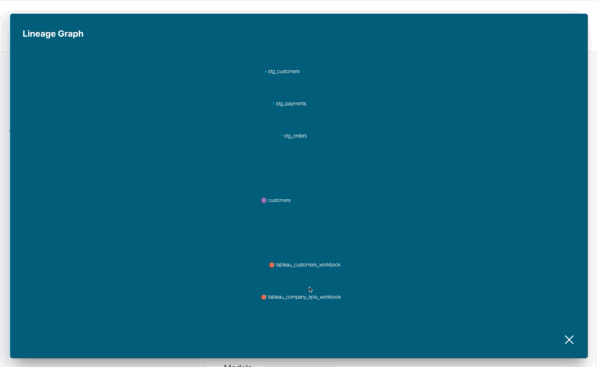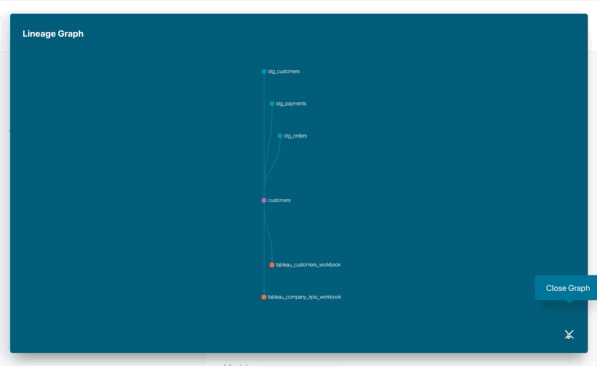
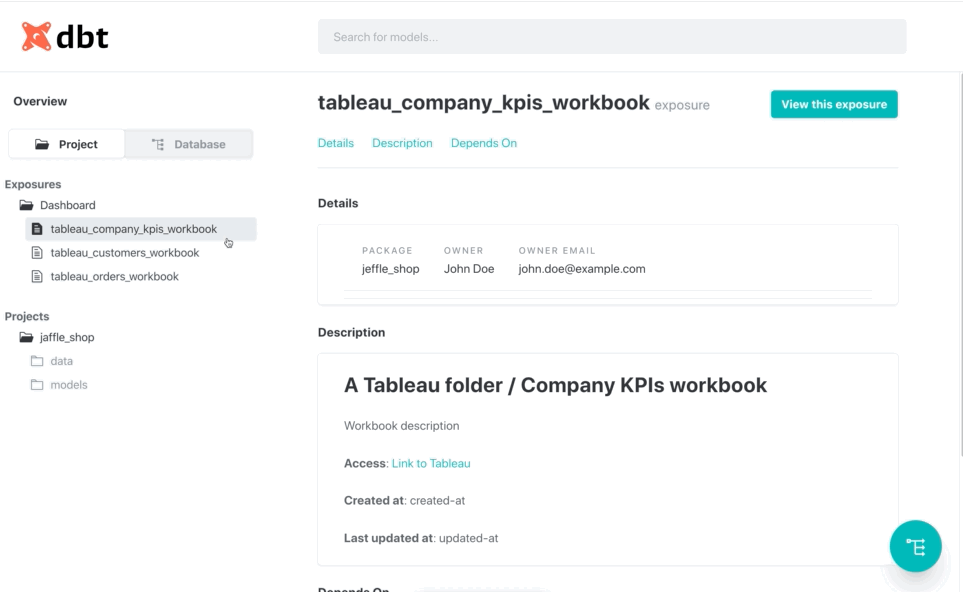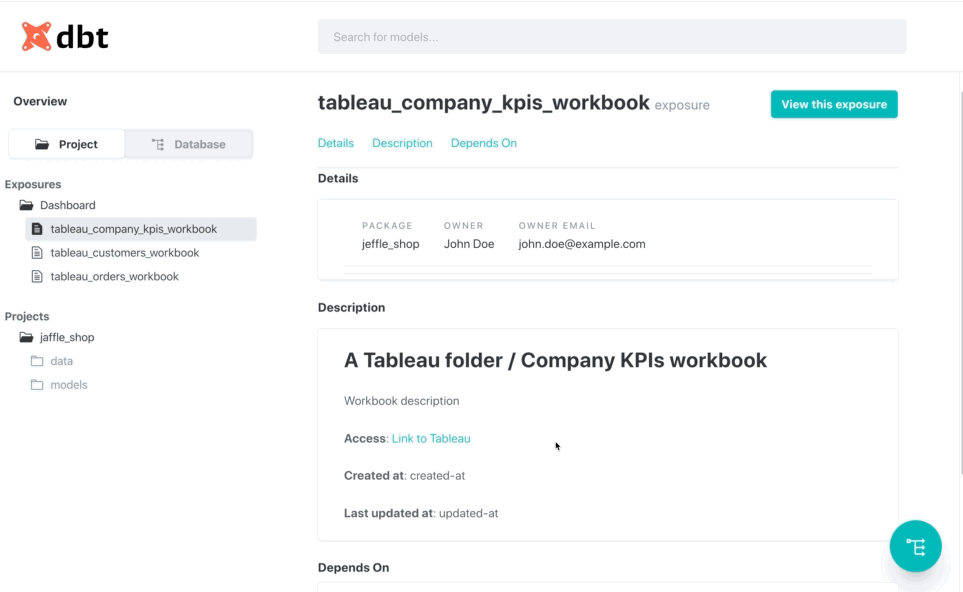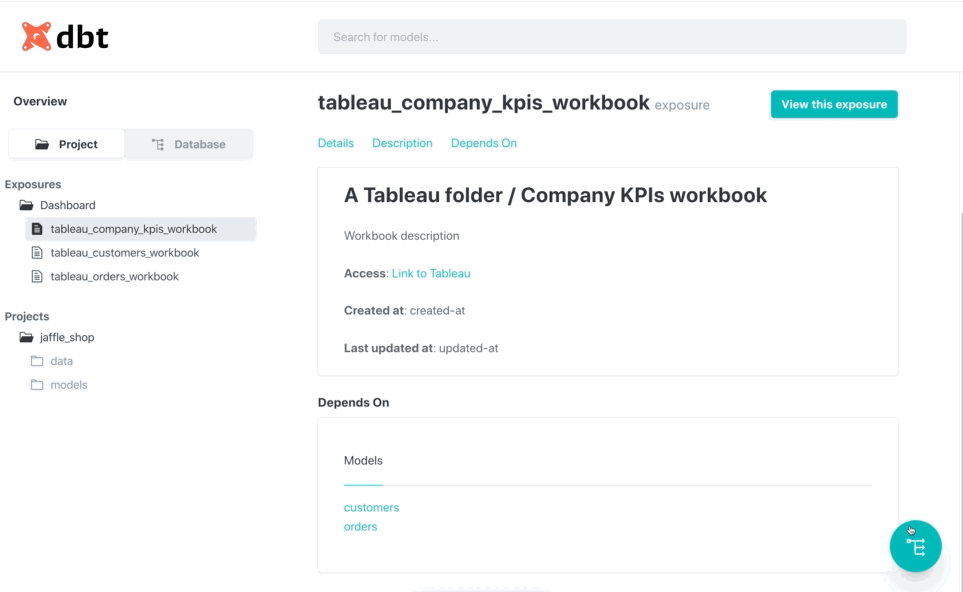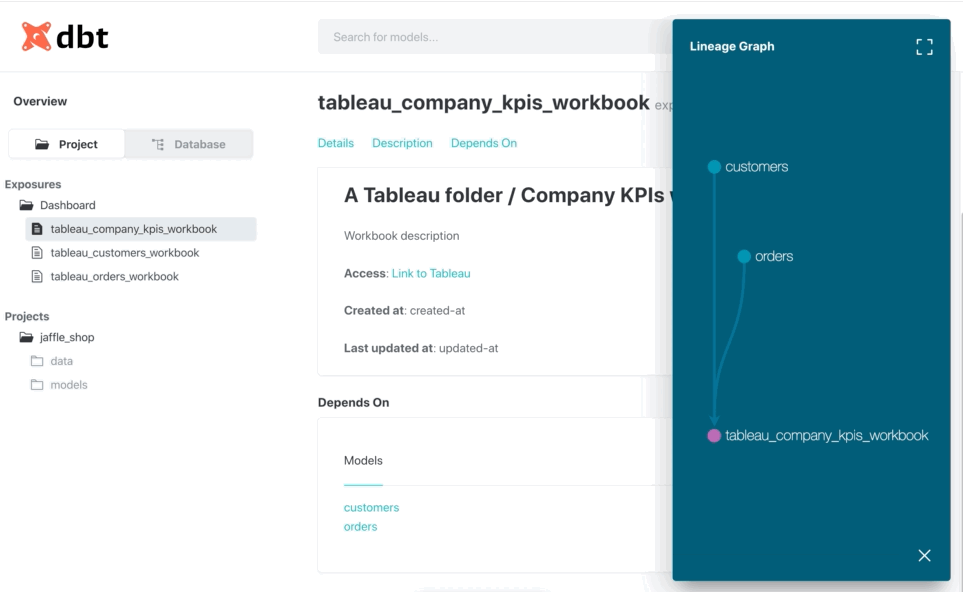
Or by doing the inverse. Starting from an exposure, find which models are used on it:
This example has been taken from the integration tests available in this project. You can read more in the `Testing`
section below.
## Features, assumptions and limitations
* Only custom SQL written on Tableau workbooks using fully qualified names (`DATABASE.SCHEMA.OBJECT`) will be detected;
* For now, only Tableau workbooks (and not published data sources) are supported. Also, only Snowflake SQL is currently
supported;
* Workbooks that are created under Tableau's [Personal spaces](https://help.tableau.com/current/pro/desktop/en-us/personal_space.htm)
are ignored (since they usually not governed nor production-ready).
## Usage
Internally, we use this automation as part of our dbt docs release pipeline. We have a GitHub Action that does the
following:
1. Clone our dbt repository;
2. Install dbt and our dependencies;
3. Run `dbt docs generate` (remember to run it against your production environment);
4. Run this project (using the `manifest.json` generated from the previous command as input);
5. Publish the generated documentation portal;
To run this project, we use:
```shell
$ python3 -m exposurescrawler.crawlers.tableau \
--manifest-path=~path/to/dbt/target/manifest.json \
--dbt-package-name="your_dbt_pakage_name" \
--tableau-ignore-projects Archive \
--verbose
```
Make sure you check the `.env.example` file to see which environment variables must be defined.
## Development
Clone the repository and install it in editable mode:
```shell
$ pip install -e .
```
Before opening a pull request, make sure you run:
* `make lint`: runs `mypy`, `black` and `flake8`;
* `make test`: runs all tests
## Architecture
The entry point for the crawlers should be on the `crawlers` module. For now, only Tableau is supported.
The `tableau` module contains all API clients (REST and GraphQL) and models.
The `dbt` module contains a model for representing a dbt exposure and utilities for parsing, interacting and saving dbt
manifests.
Finally, the `utils` module has functions for logging and string parsing.
## Testing
For the integration tests, we use a sample `manifest.json` as a fixture. It was manually generated from
the [jaffle_shop](https://github.com/fishtown-analytics/jaffle_shop), an official dbt sample project.
```shell
$ git clone https://github.com/fishtown-analytics/jaffle_shop
$ cd jaffle_shop
$ pipenv shell
$ pip install dbt==0.19.1
```
After adding an entry on my dbt profile and then setting the default database on the project to `sample_dbt` on
the `dbt_project.yaml`:
```shell
$ dbt compile --target prod
```
The generated `manifest.json` is then prettified and copied to the `tests/_fixtures` folder. I've also manually removed
the `macros` entries from the file just to make it easier to navigate through it in case of troubleshooting.
```shell
$ cat target/manifest.json | jq > $PROJECT_ROOT/tests/_fixtures/manifest.json
```
## Future ideas
* Allow filters to be passed. E.g. only include Tableau workbooks with certain tags;
* Add support to Tableau published data sources;
* Include other BI tools to be crawled, such as Metabase.
## Contributing
We are open and would love to have contributions, both in Pull Requests but also in ideas and feedback. Don't hesitate
to create an Issue on this repository if you are trying this project in your organization or have anything to share.
## Release
There is a GitHub Action that will trigger a release of this package on PyPI based on releases created on GitHub.
Steps:
* Loosely follow [semantic versioning](https://semver.org/)
* Remember to pretend the tag name with `v`
* Use the tag name as the release title on GitHub
* Use the auto-generated release notes from GitHub
* Append a link at the end of the release notes to the released version on PyPI
## License
This project is licensed under the Apache License, Version 2.0: http://www.apache.org/licenses/LICENSE-2.0.
%package -n python3-dbt-exposures-crawler
Summary: Extracts information from different systems and convert them to dbt exposures
Provides: python-dbt-exposures-crawler
BuildRequires: python3-devel
BuildRequires: python3-setuptools
BuildRequires: python3-pip
%description -n python3-dbt-exposures-crawler
# dbt exposures crawler
[](https://badge.fury.io/py/dbt-exposures-crawler)
[](https://github.com/voi-oss/dbt-exposures-crawler/actions/workflows/run-tests.yaml)
[](https://github.com/voi-oss/dbt-exposures-crawler/actions/workflows/run-code-checks.yaml)
[](https://codecov.io/gh/voi-oss/dbt-exposures-crawler)
[](https://github.com/voi-oss/dbt-exposures-crawler/)
Automates the creation of dbt exposures from different sources. Currently, only Tableau workbooks using Snowflake SQL
are supported as a source.
> This project is in an ALPHA stage. Internal and external APIs might change between minor versions.
> Please reach out if you try this at your own organization. Feedback is very appreciated, and we
> would love to hear if you had any issues setting this up at your own.
## Installation
This project requires Python 3.8+. We have tested it internally with dbt 1.x, Tableau Server 2022.1 and Snowflake SQL
dialect.
You can install the latest version of this package from PyPI by running the command below. Usage instructions can be
found further below in this document.
```shell
$ pip install dbt-exposures-crawler
```
## Motivation
[dbt](https://www.getdbt.com/) is an open-source tool to manage data transformations in SQL. It automatically generates
a documentation portal from your project which includes a dependency lineage graph. It is possible to add external
downstream dependencies to this graph (such as a dashboard on a Business Intelligence tool) through a dbt feature called
[exposures](https://docs.getdbt.com/docs/building-a-dbt-project/exposures), which are normally defined through `yaml`
files.
This project automates the creation of exposures by implementing crawlers to parse the metadata of downstream tools.
Currently, only Tableau dashboards are supported, but we have plans to include Metabase as well.
A few use cases on how having exposures can help:
* analysts working on a model can use the exposures to perform impact analysis and see which reports might be impacted
by their changes;
* report consumers can find their report on dbt and see which models are used and read their documentation;
* report consumers can find which other reports are using the same models as their favorite reports.
## How it works
Summary:
1. Retrieve dbt models and sources from `manifest.json`;
2. Extract metadata (custom SQL and table references) from Tableau workbooks using their GraphQL API);
3. Try to find occurrences from the dbt models and sources in the Tableau SQL;
4. Use the Tableau REST API to retrieve additional information about the workbooks (author, project, etc);
5. Create the dbt exposures (in-memory) and write it back to the `manifest.json`.
More in-depth explanation:
First, you must provide the path to a dbt project [manifest](https://docs.getdbt.com/reference/artifacts/manifest-json).
The metadata and fully qualified names (database, schema and object name) are extracted from all dbt models and sources
represented in the manifest. The combination of dbt models and dbt sources will from now on be referred as dbt nodes.
Next, workbook metadata is extracted from Tableau using
their [Metadata API](https://help.tableau.com/current/api/metadata_api/en-us/index.html), including workbooks that use
custom SQL queries and workbooks that don't (which are referred in this project as "native SQL" workbooks). Note that
this API is included in all Tableau licenses (i.e. it does not require the Data Management Add-on), but must
be [manually enabled](https://help.tableau.com/current/api/metadata_api/en-us/docs/meta_api_start.html#enable)
if you host your own Tableau Server.
The SQL from the custom SQL workbooks and the table names from the native SQL workbooks are normalized through simple
heuristics, such as removing quotes and converting the custom SQL to lowercase. Now that both normalized SQL and
normalized table names from Tableau, and the fully qualified names for the dbt nodes are available, the project tries to
find the occurrences of the latter in the former.
The result of the above is a mapping of workbooks and which dbt nodes they depend on. For every workbook (with mapped
dependencies available), extra metadata that was not available in the Metadata API is then retrieved from Tableau by
using their [REST API](https://help.tableau.com/current/api/rest_api/en-us/REST/rest_api.htm), including when the
workbook was created, when it was last updated, to which folder it belongs on Tableau and information about the author
of the workbook.
As a final step, the information above is written back in the provided `manifest.json` in the form of exposures. Note
that instead of generating `.yaml` files for each exposure, they are written directly on the `manifest.json`.
## Example
To better understand how the project works, let's take as an example
the [jaffle_shop](https://github.com/fishtown-analytics/jaffle_shop) dbt sample project. It has, among other models,
a `customers` and an `orders` model.
Now suppose that you company has 4 workbooks on Tableau:
* Customers workbook: accesses the `customers` dbt model through custom SQL;
* Company KPIs workbook: accesses both models through custom SQL;
* Orders workbook: accesses the `orders` model without custom SQL;
* Unrelated workbook: a workbook that does not use the dbt project but instead has a static data source.
When running this project, you would get the following console output:
The `manifest.json` that you provided would have 3 new exposures added to it, such as:
Those exposures can then be visualized through your dbt documentation portal, either by finding which exposures are
downstream dependencies of a certain model:
Or by doing the inverse. Starting from an exposure, find which models are used on it:
This example has been taken from the integration tests available in this project. You can read more in the `Testing`
section below.
## Features, assumptions and limitations
* Only custom SQL written on Tableau workbooks using fully qualified names (`DATABASE.SCHEMA.OBJECT`) will be detected;
* For now, only Tableau workbooks (and not published data sources) are supported. Also, only Snowflake SQL is currently
supported;
* Workbooks that are created under Tableau's [Personal spaces](https://help.tableau.com/current/pro/desktop/en-us/personal_space.htm)
are ignored (since they usually not governed nor production-ready).
## Usage
Internally, we use this automation as part of our dbt docs release pipeline. We have a GitHub Action that does the
following:
1. Clone our dbt repository;
2. Install dbt and our dependencies;
3. Run `dbt docs generate` (remember to run it against your production environment);
4. Run this project (using the `manifest.json` generated from the previous command as input);
5. Publish the generated documentation portal;
To run this project, we use:
```shell
$ python3 -m exposurescrawler.crawlers.tableau \
--manifest-path=~path/to/dbt/target/manifest.json \
--dbt-package-name="your_dbt_pakage_name" \
--tableau-ignore-projects Archive \
--verbose
```
Make sure you check the `.env.example` file to see which environment variables must be defined.
## Development
Clone the repository and install it in editable mode:
```shell
$ pip install -e .
```
Before opening a pull request, make sure you run:
* `make lint`: runs `mypy`, `black` and `flake8`;
* `make test`: runs all tests
## Architecture
The entry point for the crawlers should be on the `crawlers` module. For now, only Tableau is supported.
The `tableau` module contains all API clients (REST and GraphQL) and models.
The `dbt` module contains a model for representing a dbt exposure and utilities for parsing, interacting and saving dbt
manifests.
Finally, the `utils` module has functions for logging and string parsing.
## Testing
For the integration tests, we use a sample `manifest.json` as a fixture. It was manually generated from
the [jaffle_shop](https://github.com/fishtown-analytics/jaffle_shop), an official dbt sample project.
```shell
$ git clone https://github.com/fishtown-analytics/jaffle_shop
$ cd jaffle_shop
$ pipenv shell
$ pip install dbt==0.19.1
```
After adding an entry on my dbt profile and then setting the default database on the project to `sample_dbt` on
the `dbt_project.yaml`:
```shell
$ dbt compile --target prod
```
The generated `manifest.json` is then prettified and copied to the `tests/_fixtures` folder. I've also manually removed
the `macros` entries from the file just to make it easier to navigate through it in case of troubleshooting.
```shell
$ cat target/manifest.json | jq > $PROJECT_ROOT/tests/_fixtures/manifest.json
```
## Future ideas
* Allow filters to be passed. E.g. only include Tableau workbooks with certain tags;
* Add support to Tableau published data sources;
* Include other BI tools to be crawled, such as Metabase.
## Contributing
We are open and would love to have contributions, both in Pull Requests but also in ideas and feedback. Don't hesitate
to create an Issue on this repository if you are trying this project in your organization or have anything to share.
## Release
There is a GitHub Action that will trigger a release of this package on PyPI based on releases created on GitHub.
Steps:
* Loosely follow [semantic versioning](https://semver.org/)
* Remember to pretend the tag name with `v`
* Use the tag name as the release title on GitHub
* Use the auto-generated release notes from GitHub
* Append a link at the end of the release notes to the released version on PyPI
## License
This project is licensed under the Apache License, Version 2.0: http://www.apache.org/licenses/LICENSE-2.0.
%package help
Summary: Development documents and examples for dbt-exposures-crawler
Provides: python3-dbt-exposures-crawler-doc
%description help
# dbt exposures crawler
[](https://badge.fury.io/py/dbt-exposures-crawler)
[](https://github.com/voi-oss/dbt-exposures-crawler/actions/workflows/run-tests.yaml)
[](https://github.com/voi-oss/dbt-exposures-crawler/actions/workflows/run-code-checks.yaml)
[](https://codecov.io/gh/voi-oss/dbt-exposures-crawler)
[](https://github.com/voi-oss/dbt-exposures-crawler/)
Automates the creation of dbt exposures from different sources. Currently, only Tableau workbooks using Snowflake SQL
are supported as a source.
> This project is in an ALPHA stage. Internal and external APIs might change between minor versions.
> Please reach out if you try this at your own organization. Feedback is very appreciated, and we
> would love to hear if you had any issues setting this up at your own.
## Installation
This project requires Python 3.8+. We have tested it internally with dbt 1.x, Tableau Server 2022.1 and Snowflake SQL
dialect.
You can install the latest version of this package from PyPI by running the command below. Usage instructions can be
found further below in this document.
```shell
$ pip install dbt-exposures-crawler
```
## Motivation
[dbt](https://www.getdbt.com/) is an open-source tool to manage data transformations in SQL. It automatically generates
a documentation portal from your project which includes a dependency lineage graph. It is possible to add external
downstream dependencies to this graph (such as a dashboard on a Business Intelligence tool) through a dbt feature called
[exposures](https://docs.getdbt.com/docs/building-a-dbt-project/exposures), which are normally defined through `yaml`
files.
This project automates the creation of exposures by implementing crawlers to parse the metadata of downstream tools.
Currently, only Tableau dashboards are supported, but we have plans to include Metabase as well.
A few use cases on how having exposures can help:
* analysts working on a model can use the exposures to perform impact analysis and see which reports might be impacted
by their changes;
* report consumers can find their report on dbt and see which models are used and read their documentation;
* report consumers can find which other reports are using the same models as their favorite reports.
## How it works
Summary:
1. Retrieve dbt models and sources from `manifest.json`;
2. Extract metadata (custom SQL and table references) from Tableau workbooks using their GraphQL API);
3. Try to find occurrences from the dbt models and sources in the Tableau SQL;
4. Use the Tableau REST API to retrieve additional information about the workbooks (author, project, etc);
5. Create the dbt exposures (in-memory) and write it back to the `manifest.json`.
More in-depth explanation:
First, you must provide the path to a dbt project [manifest](https://docs.getdbt.com/reference/artifacts/manifest-json).
The metadata and fully qualified names (database, schema and object name) are extracted from all dbt models and sources
represented in the manifest. The combination of dbt models and dbt sources will from now on be referred as dbt nodes.
Next, workbook metadata is extracted from Tableau using
their [Metadata API](https://help.tableau.com/current/api/metadata_api/en-us/index.html), including workbooks that use
custom SQL queries and workbooks that don't (which are referred in this project as "native SQL" workbooks). Note that
this API is included in all Tableau licenses (i.e. it does not require the Data Management Add-on), but must
be [manually enabled](https://help.tableau.com/current/api/metadata_api/en-us/docs/meta_api_start.html#enable)
if you host your own Tableau Server.
The SQL from the custom SQL workbooks and the table names from the native SQL workbooks are normalized through simple
heuristics, such as removing quotes and converting the custom SQL to lowercase. Now that both normalized SQL and
normalized table names from Tableau, and the fully qualified names for the dbt nodes are available, the project tries to
find the occurrences of the latter in the former.
The result of the above is a mapping of workbooks and which dbt nodes they depend on. For every workbook (with mapped
dependencies available), extra metadata that was not available in the Metadata API is then retrieved from Tableau by
using their [REST API](https://help.tableau.com/current/api/rest_api/en-us/REST/rest_api.htm), including when the
workbook was created, when it was last updated, to which folder it belongs on Tableau and information about the author
of the workbook.
As a final step, the information above is written back in the provided `manifest.json` in the form of exposures. Note
that instead of generating `.yaml` files for each exposure, they are written directly on the `manifest.json`.
## Example
To better understand how the project works, let's take as an example
the [jaffle_shop](https://github.com/fishtown-analytics/jaffle_shop) dbt sample project. It has, among other models,
a `customers` and an `orders` model.
Now suppose that you company has 4 workbooks on Tableau:
* Customers workbook: accesses the `customers` dbt model through custom SQL;
* Company KPIs workbook: accesses both models through custom SQL;
* Orders workbook: accesses the `orders` model without custom SQL;
* Unrelated workbook: a workbook that does not use the dbt project but instead has a static data source.
When running this project, you would get the following console output:
The `manifest.json` that you provided would have 3 new exposures added to it, such as:
Those exposures can then be visualized through your dbt documentation portal, either by finding which exposures are
downstream dependencies of a certain model:
Or by doing the inverse. Starting from an exposure, find which models are used on it:
This example has been taken from the integration tests available in this project. You can read more in the `Testing`
section below.
## Features, assumptions and limitations
* Only custom SQL written on Tableau workbooks using fully qualified names (`DATABASE.SCHEMA.OBJECT`) will be detected;
* For now, only Tableau workbooks (and not published data sources) are supported. Also, only Snowflake SQL is currently
supported;
* Workbooks that are created under Tableau's [Personal spaces](https://help.tableau.com/current/pro/desktop/en-us/personal_space.htm)
are ignored (since they usually not governed nor production-ready).
## Usage
Internally, we use this automation as part of our dbt docs release pipeline. We have a GitHub Action that does the
following:
1. Clone our dbt repository;
2. Install dbt and our dependencies;
3. Run `dbt docs generate` (remember to run it against your production environment);
4. Run this project (using the `manifest.json` generated from the previous command as input);
5. Publish the generated documentation portal;
To run this project, we use:
```shell
$ python3 -m exposurescrawler.crawlers.tableau \
--manifest-path=~path/to/dbt/target/manifest.json \
--dbt-package-name="your_dbt_pakage_name" \
--tableau-ignore-projects Archive \
--verbose
```
Make sure you check the `.env.example` file to see which environment variables must be defined.
## Development
Clone the repository and install it in editable mode:
```shell
$ pip install -e .
```
Before opening a pull request, make sure you run:
* `make lint`: runs `mypy`, `black` and `flake8`;
* `make test`: runs all tests
## Architecture
The entry point for the crawlers should be on the `crawlers` module. For now, only Tableau is supported.
The `tableau` module contains all API clients (REST and GraphQL) and models.
The `dbt` module contains a model for representing a dbt exposure and utilities for parsing, interacting and saving dbt
manifests.
Finally, the `utils` module has functions for logging and string parsing.
## Testing
For the integration tests, we use a sample `manifest.json` as a fixture. It was manually generated from
the [jaffle_shop](https://github.com/fishtown-analytics/jaffle_shop), an official dbt sample project.
```shell
$ git clone https://github.com/fishtown-analytics/jaffle_shop
$ cd jaffle_shop
$ pipenv shell
$ pip install dbt==0.19.1
```
After adding an entry on my dbt profile and then setting the default database on the project to `sample_dbt` on
the `dbt_project.yaml`:
```shell
$ dbt compile --target prod
```
The generated `manifest.json` is then prettified and copied to the `tests/_fixtures` folder. I've also manually removed
the `macros` entries from the file just to make it easier to navigate through it in case of troubleshooting.
```shell
$ cat target/manifest.json | jq > $PROJECT_ROOT/tests/_fixtures/manifest.json
```
## Future ideas
* Allow filters to be passed. E.g. only include Tableau workbooks with certain tags;
* Add support to Tableau published data sources;
* Include other BI tools to be crawled, such as Metabase.
## Contributing
We are open and would love to have contributions, both in Pull Requests but also in ideas and feedback. Don't hesitate
to create an Issue on this repository if you are trying this project in your organization or have anything to share.
## Release
There is a GitHub Action that will trigger a release of this package on PyPI based on releases created on GitHub.
Steps:
* Loosely follow [semantic versioning](https://semver.org/)
* Remember to pretend the tag name with `v`
* Use the tag name as the release title on GitHub
* Use the auto-generated release notes from GitHub
* Append a link at the end of the release notes to the released version on PyPI
## License
This project is licensed under the Apache License, Version 2.0: http://www.apache.org/licenses/LICENSE-2.0.
%prep
%autosetup -n dbt-exposures-crawler-0.1.4
%build
%py3_build
%install
%py3_install
install -d -m755 %{buildroot}/%{_pkgdocdir}
if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi
if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi
if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi
if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi
pushd %{buildroot}
if [ -d usr/lib ]; then
find usr/lib -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
if [ -d usr/lib64 ]; then
find usr/lib64 -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
if [ -d usr/bin ]; then
find usr/bin -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
if [ -d usr/sbin ]; then
find usr/sbin -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
touch doclist.lst
if [ -d usr/share/man ]; then
find usr/share/man -type f -printf "\"/%h/%f.gz\"\n" >> doclist.lst
fi
popd
mv %{buildroot}/filelist.lst .
mv %{buildroot}/doclist.lst .
%files -n python3-dbt-exposures-crawler -f filelist.lst
%dir %{python3_sitelib}/*
%files help -f doclist.lst
%{_docdir}/*
%changelog
* Tue Jun 20 2023 Python_Bot - 0.1.4-1
- Package Spec generated



