%global _empty_manifest_terminate_build 0
Name: python-sparsify-nightly
Version: 1.6.0.20230616
Release: 1
Summary: Easy-to-use UI for automatically sparsifying neural networks and creating sparsification recipes for better inference performance and a smaller footprint
License: Apache
URL: https://github.com/neuralmagic/sparsify
Source0: https://mirrors.aliyun.com/pypi/web/packages/58/04/8f7dfacf40e7fff11ff3f79d0184eda5b48354e913a243a268c7b7906360/sparsify-nightly-1.6.0.20230616.tar.gz
BuildArch: noarch
Requires: python3-sparsezoo-nightly
Requires: python3-sparseml-nightly
Requires: python3-apispec
Requires: python3-flasgger
Requires: python3-Flask
Requires: python3-Flask-Cors
Requires: python3-marshmallow
Requires: python3-peewee
Requires: python3-pysqlite3-binary
Requires: python3-beautifulsoup4
Requires: python3-black
Requires: python3-flake8
Requires: python3-isort
Requires: python3-m2r2
Requires: python3-mistune
Requires: python3-myst-parser
Requires: python3-rinohtype
Requires: python3-sphinx
Requires: python3-sphinx-copybutton
Requires: python3-sphinx-markdown-tables
Requires: python3-sphinx-multiversion
Requires: python3-sphinx-rtd-theme
Requires: python3-pytest
Requires: python3-wheel
%description
 Sparsify
Sparsify
Easy-to-use UI for automatically sparsifying neural networks and creating sparsification recipes for better inference performance and a smaller footprint










## 🚨 FEBRUARY 2023 MAJOR ANNOUNCEMENT 🚨
We are excited to mention the next generation of Sparsify is underway. You can expect more features and simplicity to build sparse models to target optimal general performance at scale.
We will share more in the coming months. In the meantime, sign up for our [Early Access Waitlist](https://neuralmagic.com/request-early-access-to-sparsify/) and be the first to try the Sparsify Alpha.
## Overview
Sparsify is an easy-to-use UI tool that simplifies the deep learning model [sparsification](https://docs.neuralmagic.com/user-guides/sparsification) process to rapidly achieve the best combination of size, speed, and accuracy.
It sparsifies and benchmarks models informed by industry research insights for ML practitioners, including ML engineers and operators, who need to deploy performant deep learning models fast and at scale.
Sparsify shows visual performance potential for your model, including a sliding scale between performance and recovery, ultimately speeding up the model sparsification process from weeks to minutes.
The [GitHub repository](https://github.com/neuralmagic/sparsify) contains the package to locally launch Sparsify where you can create projects to load and sparsify your deep learning models.
At the end, you can export sparsification recipes to integrate with your training workflow.
 ## Highlights
- [User Guide](https://docs.neuralmagic.com/sparsify/source/userguide/01-intro.html)
## Tutorials
Coming soon!
## Installation
This repository is tested on Python 3.7-3.10, Linux/Debian systems, and Chrome 87+.
It is recommended to install in a [virtual environment](https://docs.python.org/3/library/venv.html) to keep your system in order.
Install with pip using:
```bash
pip install sparsify
```
Depending on your flow, PyTorch, Keras, or TensorFlow must be installed in the local environment along with Sparsify to export recipes through the UI.
## Quick Tour
A console script entry point is installed with the package: `sparsify`.
This enables easy interaction through your console/terminal.
Note, for some environments the console scripts cannot install properly.
If this happens for your system and the `sparsify` command is not available,
`scripts/main.py` may be used in its place. Documentation is provided in the
script file.
To launch Sparsify locally, open up a console or terminal window and enter the following:
```bash
sparsify
```
The Sparsify server will begin running locally on the machine and can be accessed through a web browser.
The default host:port Sparsify starts on is `0.0.0.0:5543`.
Therefore, after starting Sparsify with the default commands, you may enter the following into a web browser to begin using Sparsify: `http://0.0.0.0:5543`.
If you are running Sparsify on a separate server from where the web browser is located,
then you will need to substitute in the proper IP address for that server in place of `0.0.0.0`.
Additionally, confirm that the networking rules on your server allow for access to port 5543.
After visiting `http://0.0.0.0:5543` in a web browser, the home page for Sparsify will load if configured correctly:
## Highlights
- [User Guide](https://docs.neuralmagic.com/sparsify/source/userguide/01-intro.html)
## Tutorials
Coming soon!
## Installation
This repository is tested on Python 3.7-3.10, Linux/Debian systems, and Chrome 87+.
It is recommended to install in a [virtual environment](https://docs.python.org/3/library/venv.html) to keep your system in order.
Install with pip using:
```bash
pip install sparsify
```
Depending on your flow, PyTorch, Keras, or TensorFlow must be installed in the local environment along with Sparsify to export recipes through the UI.
## Quick Tour
A console script entry point is installed with the package: `sparsify`.
This enables easy interaction through your console/terminal.
Note, for some environments the console scripts cannot install properly.
If this happens for your system and the `sparsify` command is not available,
`scripts/main.py` may be used in its place. Documentation is provided in the
script file.
To launch Sparsify locally, open up a console or terminal window and enter the following:
```bash
sparsify
```
The Sparsify server will begin running locally on the machine and can be accessed through a web browser.
The default host:port Sparsify starts on is `0.0.0.0:5543`.
Therefore, after starting Sparsify with the default commands, you may enter the following into a web browser to begin using Sparsify: `http://0.0.0.0:5543`.
If you are running Sparsify on a separate server from where the web browser is located,
then you will need to substitute in the proper IP address for that server in place of `0.0.0.0`.
Additionally, confirm that the networking rules on your server allow for access to port 5543.
After visiting `http://0.0.0.0:5543` in a web browser, the home page for Sparsify will load if configured correctly:
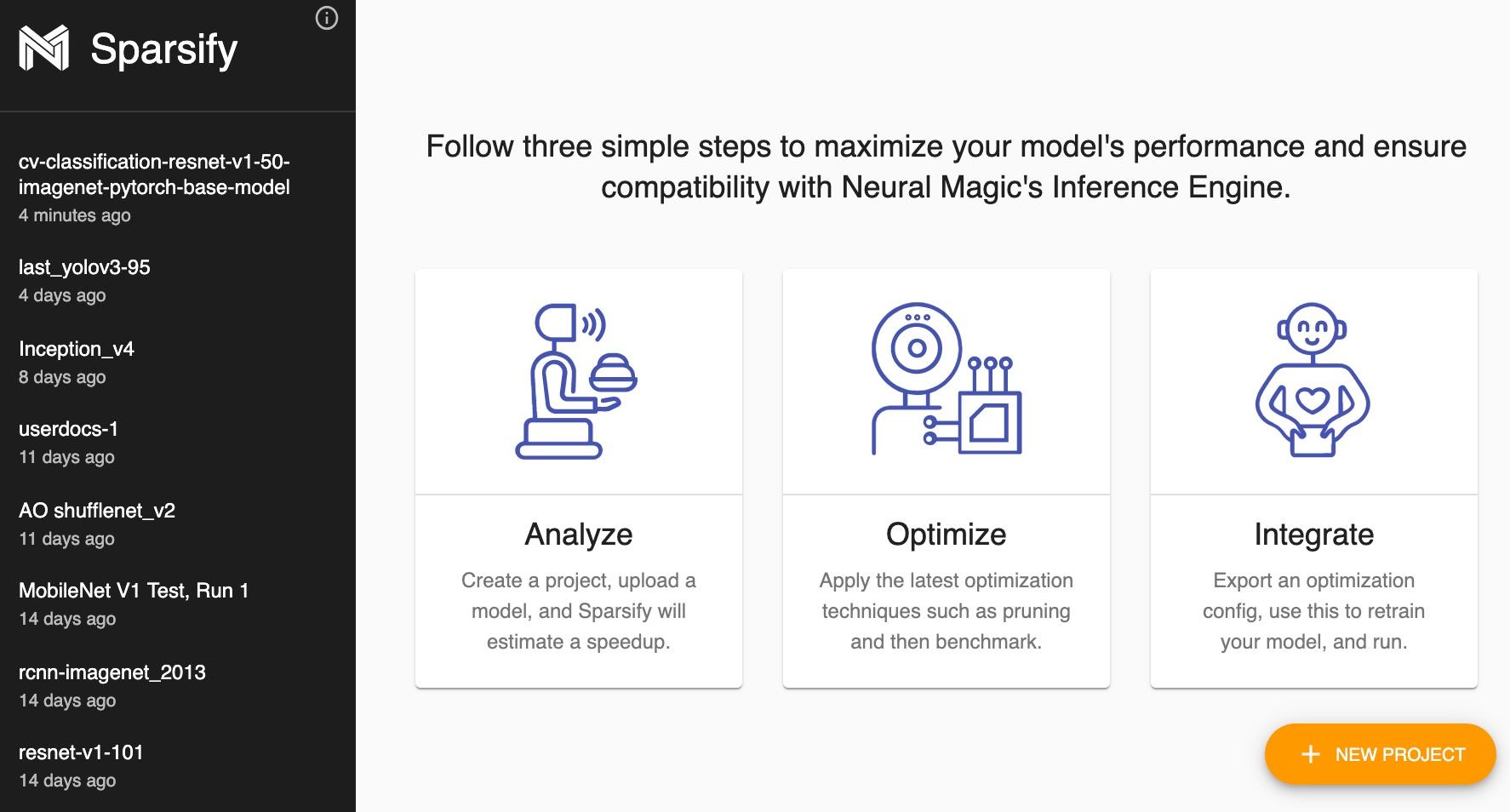
A quick start flow is given below. For a more in-depth read, check out [Sparsify documentation](https://docs.neuralmagic.com/sparsify/).
### New Project
To begin sparsifying a model, a new project must be created.
The New Project button is located in the lower right of Sparsify's home screen.
After clicking, the create project popup will be displayed:
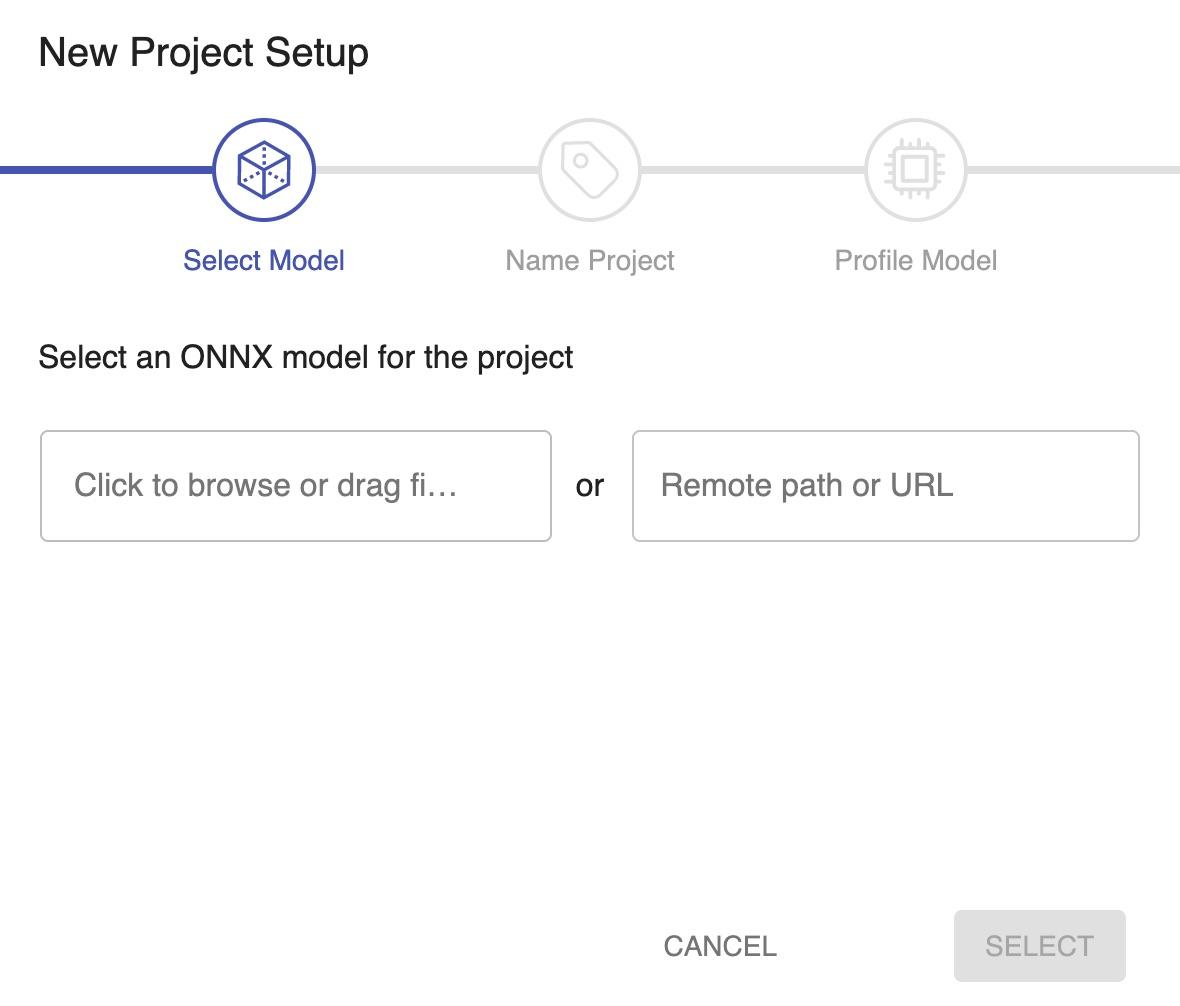
Sparsify only accepts [ONNX](https://onnx.ai/) model formats currently.
To easily convert to ONNX from common ML frameworks, see the [SparseML repository.](https://github.com/neuralmagic/sparseml)
**Compatibility/Support Notes**
- ONNX version 1.5-1.7
- ONNX opset version 11+
- ONNX IR version has not been tested at this time
To begin creating a project use one of the following flows:
- Upload your model file through the browser by clicking on `Click to browse`.
- Download your model file through a public URL by filling in the field `Remote Path or URL`.
- Move your model file from an accessible file location on the server by filling in the field `Remote Path or URL`.
Continue through the popup and fill in information as specified to finish creating the project.
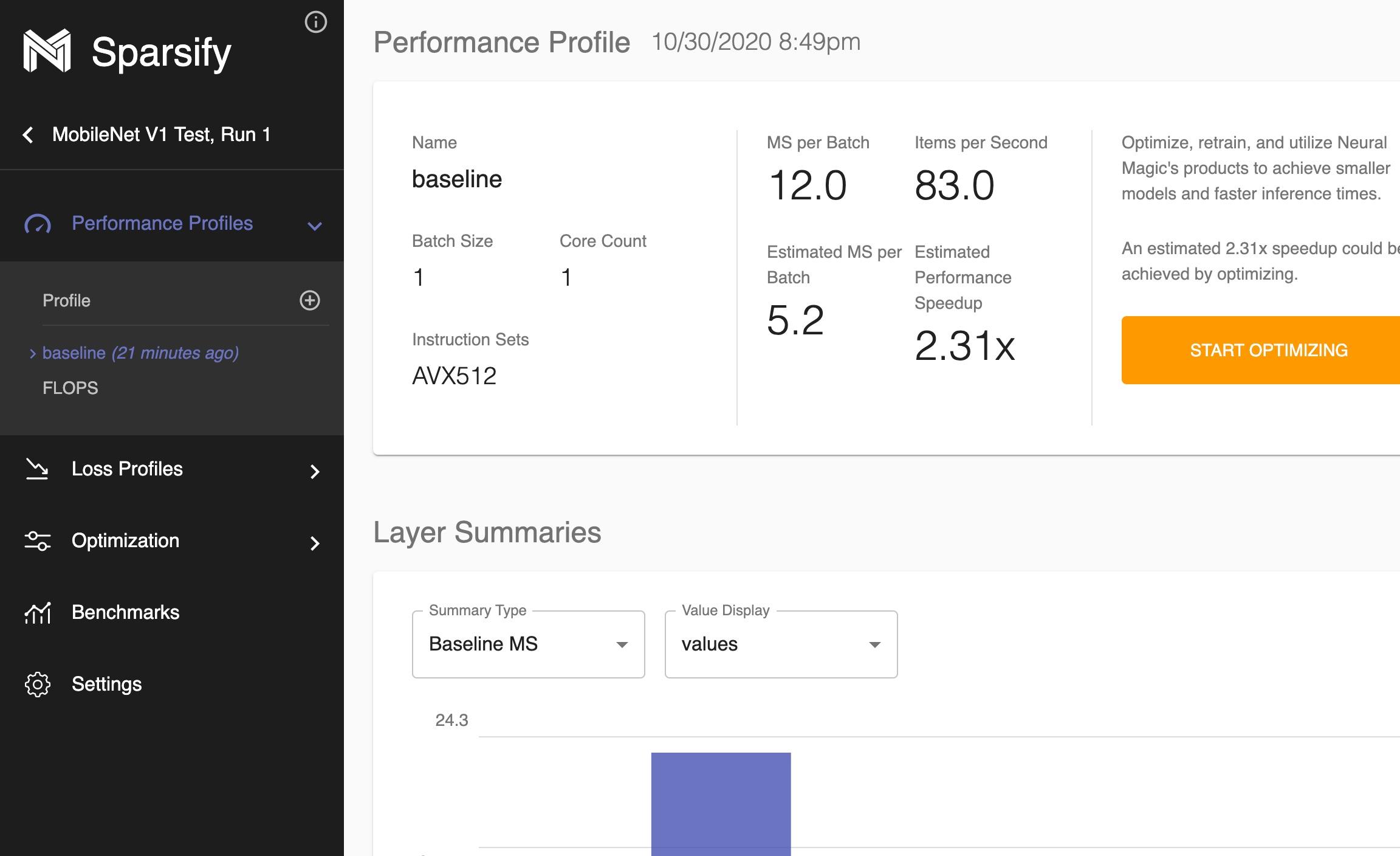
### Analyzing a Model
After model creation, sensitivity analysis for the model are shown under the `Performance Profiles` and `Loss Profiles` in the left navigation.
The profiles will show the effects that different types of algorithms and degrees of those algorithms have on both the models inference speed and the baseline loss.
Performance Profiles:
Loss Profiles:
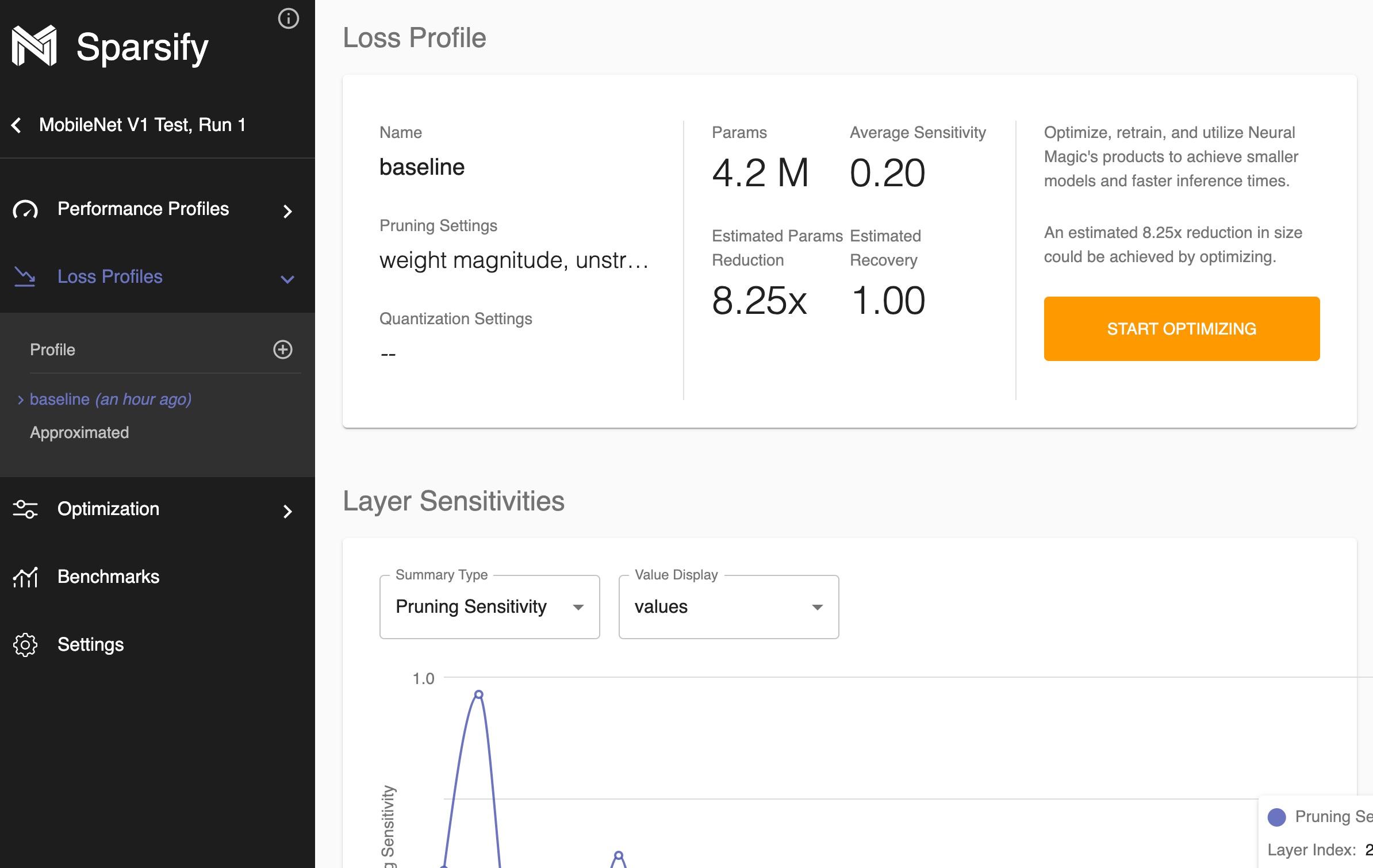
### Optimizing a Model
Click on the `Optimization` in the left navigation or the `Start Optimizing` button on the analyzing pages to begin sparsifying your model.
After clicking, the sparsification creation popup will be displayed:
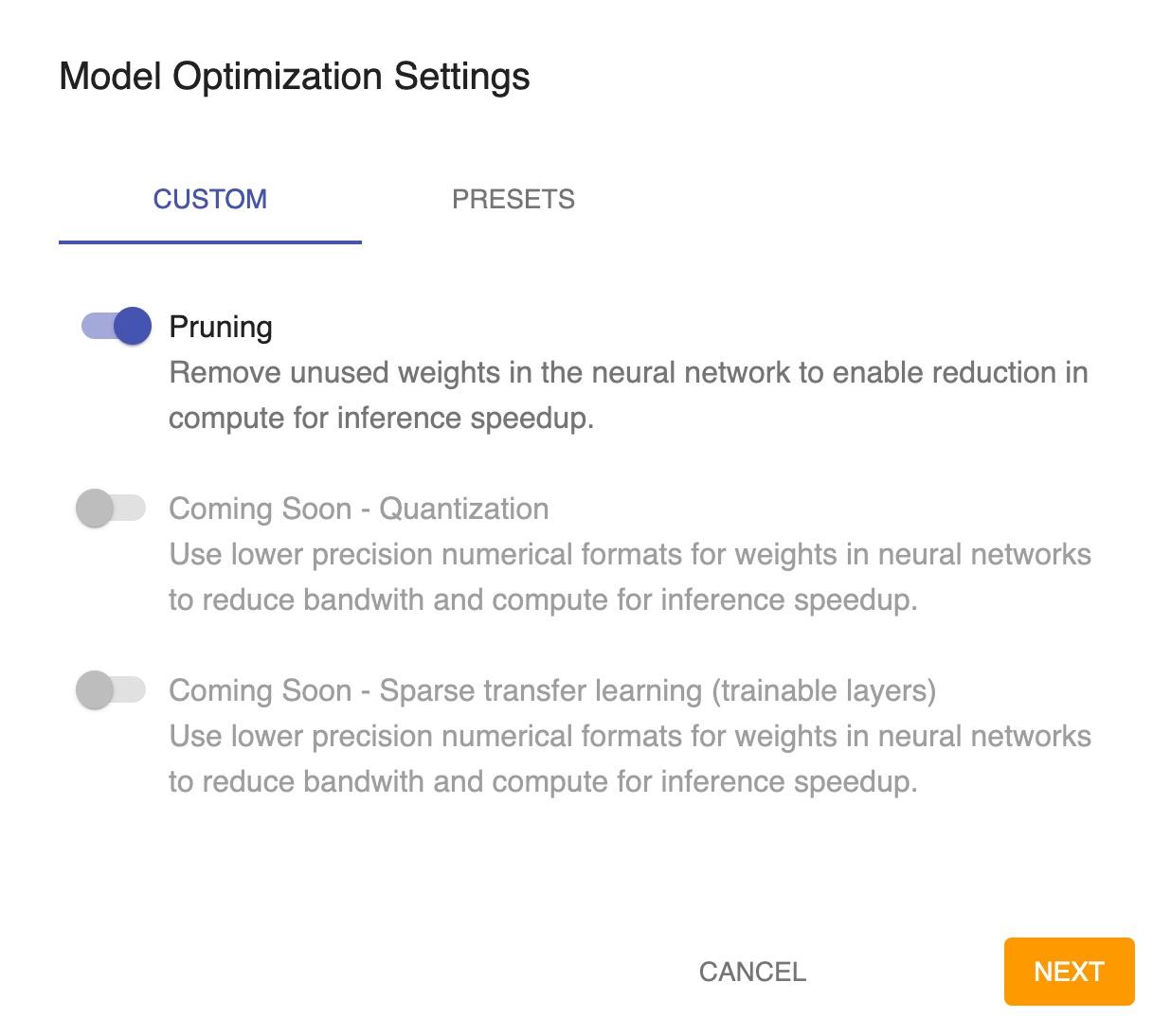
Fill in the information as required in the modal.
Once completed, Sparsify's autoML algorithms will choose the best settings it can find for optimizing your model.
The resulting recipe will be displayed along with estimated metrics for the optimized model.
The recipe can then be further edited if desired:
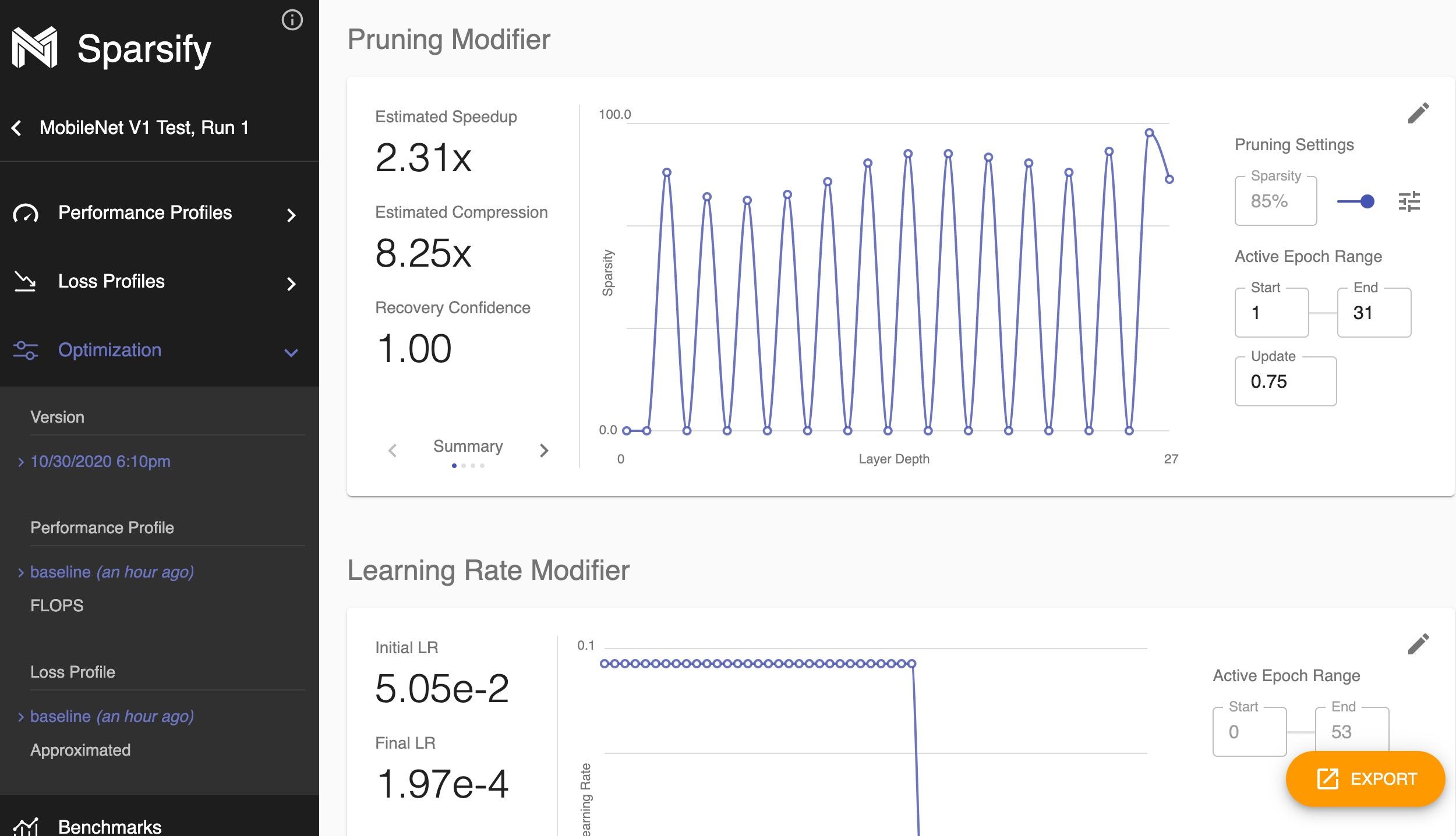
### Exporting a Recipe
Currently Sparsify is focused on training-aware methods; these allow much better loss recovery for a given target performance.
A future release will enable the option of one-shot sparsification with limited to no retraining.
Given that the recipe is created with training-aware algorithms, it must be exported for inclusion in your original training pipeline using [SparseML](https://github.com/neuralmagic/sparseml).
SparseML enables this inclusion with only a few lines of code for most training workflows.
On the optimization page, click the `Export` button in the bottom right.
This will open up the export popup:
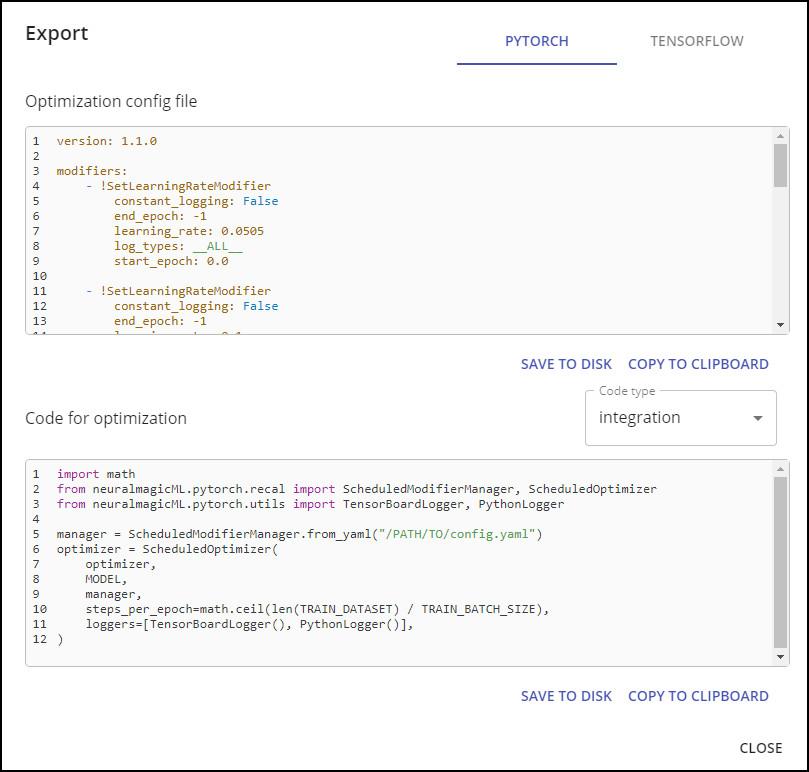
Select the framework the model was originally trained in on the upper right of the popup.
Once selected, either copy or download the recipe for use with SparseML.
In addition, some sample code using SparseML is given to integrate the exported sparsification recipe.
## Resources
### Learning More
- Documentation: [SparseML,](https://docs.neuralmagic.com/sparseml/) [SparseZoo,](https://docs.neuralmagic.com/sparsezoo/) [Sparsify,](https://docs.neuralmagic.com/sparsify/) [DeepSparse](https://docs.neuralmagic.com/deepsparse/)
- Neural Magic: [Blog,](https://www.neuralmagic.com/blog/) [Resources](https://www.neuralmagic.com/resources/)
### Release History
Official builds are hosted on PyPI
- stable: [sparsify](https://pypi.org/project/sparsify/)
- nightly (dev): [sparsify-nightly](https://pypi.org/project/sparsify-nightly/)
Additionally, more information can be found via [GitHub Releases.](https://github.com/neuralmagic/sparsify/releases)
### License
The project is licensed under the [Apache License Version 2.0](https://github.com/neuralmagic/sparsify/blob/main/LICENSE).
## Community
### Contribute
We appreciate contributions to the code, examples, integrations, and documentation as well as bug reports and feature requests! [Learn how here.](https://github.com/neuralmagic/sparsify/blob/main/CONTRIBUTING.md)
### Join
For user help or questions about Sparsify, sign up or log in to our [**Neural Magic Community Slack**](https://join.slack.com/t/discuss-neuralmagic/shared_invite/zt-q1a1cnvo-YBoICSIw3L1dmQpjBeDurQ). We are growing the community member by member and happy to see you there. Bugs, feature requests, or additional questions can also be posted to our [GitHub Issue Queue.](https://github.com/neuralmagic/sparsify/issues)
You can get the latest news, webinar and event invites, research papers, and other ML Performance tidbits by [subscribing](https://neuralmagic.com/subscribe/) to the Neural Magic community.
For more general questions about Neural Magic, please fill out this [form.](http://neuralmagic.com/contact/)
### Cite
Find this project useful in your research or other communications? Please consider citing:
```bibtex
@InProceedings{
pmlr-v119-kurtz20a,
title = {Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks},
author = {Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan},
booktitle = {Proceedings of the 37th International Conference on Machine Learning},
pages = {5533--5543},
year = {2020},
editor = {Hal Daumé III and Aarti Singh},
volume = {119},
series = {Proceedings of Machine Learning Research},
address = {Virtual},
month = {13--18 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf},
url = {http://proceedings.mlr.press/v119/kurtz20a.html},
abstract = {Optimizing convolutional neural networks for fast inference has recently become an extremely active area of research. One of the go-to solutions in this context is weight pruning, which aims to reduce computational and memory footprint by removing large subsets of the connections in a neural network. Surprisingly, much less attention has been given to exploiting sparsity in the activation maps, which tend to be naturally sparse in many settings thanks to the structure of rectified linear (ReLU) activation functions. In this paper, we present an in-depth analysis of methods for maximizing the sparsity of the activations in a trained neural network, and show that, when coupled with an efficient sparse-input convolution algorithm, we can leverage this sparsity for significant performance gains. To induce highly sparse activation maps without accuracy loss, we introduce a new regularization technique, coupled with a new threshold-based sparsification method based on a parameterized activation function called Forced-Activation-Threshold Rectified Linear Unit (FATReLU). We examine the impact of our methods on popular image classification models, showing that most architectures can adapt to significantly sparser activation maps without any accuracy loss. Our second contribution is showing that these these compression gains can be translated into inference speedups: we provide a new algorithm to enable fast convolution operations over networks with sparse activations, and show that it can enable significant speedups for end-to-end inference on a range of popular models on the large-scale ImageNet image classification task on modern Intel CPUs, with little or no retraining cost.}
}
```
```bibtex
@misc{
singh2020woodfisher,
title={WoodFisher: Efficient Second-Order Approximation for Neural Network Compression},
author={Sidak Pal Singh and Dan Alistarh},
year={2020},
eprint={2004.14340},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
%package -n python3-sparsify-nightly
Summary: Easy-to-use UI for automatically sparsifying neural networks and creating sparsification recipes for better inference performance and a smaller footprint
Provides: python-sparsify-nightly
BuildRequires: python3-devel
BuildRequires: python3-setuptools
BuildRequires: python3-pip
%description -n python3-sparsify-nightly
Sparsify
Easy-to-use UI for automatically sparsifying neural networks and creating sparsification recipes for better inference performance and a smaller footprint
## 🚨 FEBRUARY 2023 MAJOR ANNOUNCEMENT 🚨
We are excited to mention the next generation of Sparsify is underway. You can expect more features and simplicity to build sparse models to target optimal general performance at scale.
We will share more in the coming months. In the meantime, sign up for our [Early Access Waitlist](https://neuralmagic.com/request-early-access-to-sparsify/) and be the first to try the Sparsify Alpha.
## Overview
Sparsify is an easy-to-use UI tool that simplifies the deep learning model [sparsification](https://docs.neuralmagic.com/user-guides/sparsification) process to rapidly achieve the best combination of size, speed, and accuracy.
It sparsifies and benchmarks models informed by industry research insights for ML practitioners, including ML engineers and operators, who need to deploy performant deep learning models fast and at scale.
Sparsify shows visual performance potential for your model, including a sliding scale between performance and recovery, ultimately speeding up the model sparsification process from weeks to minutes.
The [GitHub repository](https://github.com/neuralmagic/sparsify) contains the package to locally launch Sparsify where you can create projects to load and sparsify your deep learning models.
At the end, you can export sparsification recipes to integrate with your training workflow.
## Highlights
- [User Guide](https://docs.neuralmagic.com/sparsify/source/userguide/01-intro.html)
## Tutorials
Coming soon!
## Installation
This repository is tested on Python 3.7-3.10, Linux/Debian systems, and Chrome 87+.
It is recommended to install in a [virtual environment](https://docs.python.org/3/library/venv.html) to keep your system in order.
Install with pip using:
```bash
pip install sparsify
```
Depending on your flow, PyTorch, Keras, or TensorFlow must be installed in the local environment along with Sparsify to export recipes through the UI.
## Quick Tour
A console script entry point is installed with the package: `sparsify`.
This enables easy interaction through your console/terminal.
Note, for some environments the console scripts cannot install properly.
If this happens for your system and the `sparsify` command is not available,
`scripts/main.py` may be used in its place. Documentation is provided in the
script file.
To launch Sparsify locally, open up a console or terminal window and enter the following:
```bash
sparsify
```
The Sparsify server will begin running locally on the machine and can be accessed through a web browser.
The default host:port Sparsify starts on is `0.0.0.0:5543`.
Therefore, after starting Sparsify with the default commands, you may enter the following into a web browser to begin using Sparsify: `http://0.0.0.0:5543`.
If you are running Sparsify on a separate server from where the web browser is located,
then you will need to substitute in the proper IP address for that server in place of `0.0.0.0`.
Additionally, confirm that the networking rules on your server allow for access to port 5543.
After visiting `http://0.0.0.0:5543` in a web browser, the home page for Sparsify will load if configured correctly:
A quick start flow is given below. For a more in-depth read, check out [Sparsify documentation](https://docs.neuralmagic.com/sparsify/).
### New Project
To begin sparsifying a model, a new project must be created.
The New Project button is located in the lower right of Sparsify's home screen.
After clicking, the create project popup will be displayed:
Sparsify only accepts [ONNX](https://onnx.ai/) model formats currently.
To easily convert to ONNX from common ML frameworks, see the [SparseML repository.](https://github.com/neuralmagic/sparseml)
**Compatibility/Support Notes**
- ONNX version 1.5-1.7
- ONNX opset version 11+
- ONNX IR version has not been tested at this time
To begin creating a project use one of the following flows:
- Upload your model file through the browser by clicking on `Click to browse`.
- Download your model file through a public URL by filling in the field `Remote Path or URL`.
- Move your model file from an accessible file location on the server by filling in the field `Remote Path or URL`.
Continue through the popup and fill in information as specified to finish creating the project.
### Analyzing a Model
After model creation, sensitivity analysis for the model are shown under the `Performance Profiles` and `Loss Profiles` in the left navigation.
The profiles will show the effects that different types of algorithms and degrees of those algorithms have on both the models inference speed and the baseline loss.
Performance Profiles:
Loss Profiles:
### Optimizing a Model
Click on the `Optimization` in the left navigation or the `Start Optimizing` button on the analyzing pages to begin sparsifying your model.
After clicking, the sparsification creation popup will be displayed:
Fill in the information as required in the modal.
Once completed, Sparsify's autoML algorithms will choose the best settings it can find for optimizing your model.
The resulting recipe will be displayed along with estimated metrics for the optimized model.
The recipe can then be further edited if desired:
### Exporting a Recipe
Currently Sparsify is focused on training-aware methods; these allow much better loss recovery for a given target performance.
A future release will enable the option of one-shot sparsification with limited to no retraining.
Given that the recipe is created with training-aware algorithms, it must be exported for inclusion in your original training pipeline using [SparseML](https://github.com/neuralmagic/sparseml).
SparseML enables this inclusion with only a few lines of code for most training workflows.
On the optimization page, click the `Export` button in the bottom right.
This will open up the export popup:
Select the framework the model was originally trained in on the upper right of the popup.
Once selected, either copy or download the recipe for use with SparseML.
In addition, some sample code using SparseML is given to integrate the exported sparsification recipe.
## Resources
### Learning More
- Documentation: [SparseML,](https://docs.neuralmagic.com/sparseml/) [SparseZoo,](https://docs.neuralmagic.com/sparsezoo/) [Sparsify,](https://docs.neuralmagic.com/sparsify/) [DeepSparse](https://docs.neuralmagic.com/deepsparse/)
- Neural Magic: [Blog,](https://www.neuralmagic.com/blog/) [Resources](https://www.neuralmagic.com/resources/)
### Release History
Official builds are hosted on PyPI
- stable: [sparsify](https://pypi.org/project/sparsify/)
- nightly (dev): [sparsify-nightly](https://pypi.org/project/sparsify-nightly/)
Additionally, more information can be found via [GitHub Releases.](https://github.com/neuralmagic/sparsify/releases)
### License
The project is licensed under the [Apache License Version 2.0](https://github.com/neuralmagic/sparsify/blob/main/LICENSE).
## Community
### Contribute
We appreciate contributions to the code, examples, integrations, and documentation as well as bug reports and feature requests! [Learn how here.](https://github.com/neuralmagic/sparsify/blob/main/CONTRIBUTING.md)
### Join
For user help or questions about Sparsify, sign up or log in to our [**Neural Magic Community Slack**](https://join.slack.com/t/discuss-neuralmagic/shared_invite/zt-q1a1cnvo-YBoICSIw3L1dmQpjBeDurQ). We are growing the community member by member and happy to see you there. Bugs, feature requests, or additional questions can also be posted to our [GitHub Issue Queue.](https://github.com/neuralmagic/sparsify/issues)
You can get the latest news, webinar and event invites, research papers, and other ML Performance tidbits by [subscribing](https://neuralmagic.com/subscribe/) to the Neural Magic community.
For more general questions about Neural Magic, please fill out this [form.](http://neuralmagic.com/contact/)
### Cite
Find this project useful in your research or other communications? Please consider citing:
```bibtex
@InProceedings{
pmlr-v119-kurtz20a,
title = {Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks},
author = {Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan},
booktitle = {Proceedings of the 37th International Conference on Machine Learning},
pages = {5533--5543},
year = {2020},
editor = {Hal Daumé III and Aarti Singh},
volume = {119},
series = {Proceedings of Machine Learning Research},
address = {Virtual},
month = {13--18 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf},
url = {http://proceedings.mlr.press/v119/kurtz20a.html},
abstract = {Optimizing convolutional neural networks for fast inference has recently become an extremely active area of research. One of the go-to solutions in this context is weight pruning, which aims to reduce computational and memory footprint by removing large subsets of the connections in a neural network. Surprisingly, much less attention has been given to exploiting sparsity in the activation maps, which tend to be naturally sparse in many settings thanks to the structure of rectified linear (ReLU) activation functions. In this paper, we present an in-depth analysis of methods for maximizing the sparsity of the activations in a trained neural network, and show that, when coupled with an efficient sparse-input convolution algorithm, we can leverage this sparsity for significant performance gains. To induce highly sparse activation maps without accuracy loss, we introduce a new regularization technique, coupled with a new threshold-based sparsification method based on a parameterized activation function called Forced-Activation-Threshold Rectified Linear Unit (FATReLU). We examine the impact of our methods on popular image classification models, showing that most architectures can adapt to significantly sparser activation maps without any accuracy loss. Our second contribution is showing that these these compression gains can be translated into inference speedups: we provide a new algorithm to enable fast convolution operations over networks with sparse activations, and show that it can enable significant speedups for end-to-end inference on a range of popular models on the large-scale ImageNet image classification task on modern Intel CPUs, with little or no retraining cost.}
}
```
```bibtex
@misc{
singh2020woodfisher,
title={WoodFisher: Efficient Second-Order Approximation for Neural Network Compression},
author={Sidak Pal Singh and Dan Alistarh},
year={2020},
eprint={2004.14340},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
%package help
Summary: Development documents and examples for sparsify-nightly
Provides: python3-sparsify-nightly-doc
%description help
Sparsify
Easy-to-use UI for automatically sparsifying neural networks and creating sparsification recipes for better inference performance and a smaller footprint
## 🚨 FEBRUARY 2023 MAJOR ANNOUNCEMENT 🚨
We are excited to mention the next generation of Sparsify is underway. You can expect more features and simplicity to build sparse models to target optimal general performance at scale.
We will share more in the coming months. In the meantime, sign up for our [Early Access Waitlist](https://neuralmagic.com/request-early-access-to-sparsify/) and be the first to try the Sparsify Alpha.
## Overview
Sparsify is an easy-to-use UI tool that simplifies the deep learning model [sparsification](https://docs.neuralmagic.com/user-guides/sparsification) process to rapidly achieve the best combination of size, speed, and accuracy.
It sparsifies and benchmarks models informed by industry research insights for ML practitioners, including ML engineers and operators, who need to deploy performant deep learning models fast and at scale.
Sparsify shows visual performance potential for your model, including a sliding scale between performance and recovery, ultimately speeding up the model sparsification process from weeks to minutes.
The [GitHub repository](https://github.com/neuralmagic/sparsify) contains the package to locally launch Sparsify where you can create projects to load and sparsify your deep learning models.
At the end, you can export sparsification recipes to integrate with your training workflow.
## Highlights
- [User Guide](https://docs.neuralmagic.com/sparsify/source/userguide/01-intro.html)
## Tutorials
Coming soon!
## Installation
This repository is tested on Python 3.7-3.10, Linux/Debian systems, and Chrome 87+.
It is recommended to install in a [virtual environment](https://docs.python.org/3/library/venv.html) to keep your system in order.
Install with pip using:
```bash
pip install sparsify
```
Depending on your flow, PyTorch, Keras, or TensorFlow must be installed in the local environment along with Sparsify to export recipes through the UI.
## Quick Tour
A console script entry point is installed with the package: `sparsify`.
This enables easy interaction through your console/terminal.
Note, for some environments the console scripts cannot install properly.
If this happens for your system and the `sparsify` command is not available,
`scripts/main.py` may be used in its place. Documentation is provided in the
script file.
To launch Sparsify locally, open up a console or terminal window and enter the following:
```bash
sparsify
```
The Sparsify server will begin running locally on the machine and can be accessed through a web browser.
The default host:port Sparsify starts on is `0.0.0.0:5543`.
Therefore, after starting Sparsify with the default commands, you may enter the following into a web browser to begin using Sparsify: `http://0.0.0.0:5543`.
If you are running Sparsify on a separate server from where the web browser is located,
then you will need to substitute in the proper IP address for that server in place of `0.0.0.0`.
Additionally, confirm that the networking rules on your server allow for access to port 5543.
After visiting `http://0.0.0.0:5543` in a web browser, the home page for Sparsify will load if configured correctly:
A quick start flow is given below. For a more in-depth read, check out [Sparsify documentation](https://docs.neuralmagic.com/sparsify/).
### New Project
To begin sparsifying a model, a new project must be created.
The New Project button is located in the lower right of Sparsify's home screen.
After clicking, the create project popup will be displayed:
Sparsify only accepts [ONNX](https://onnx.ai/) model formats currently.
To easily convert to ONNX from common ML frameworks, see the [SparseML repository.](https://github.com/neuralmagic/sparseml)
**Compatibility/Support Notes**
- ONNX version 1.5-1.7
- ONNX opset version 11+
- ONNX IR version has not been tested at this time
To begin creating a project use one of the following flows:
- Upload your model file through the browser by clicking on `Click to browse`.
- Download your model file through a public URL by filling in the field `Remote Path or URL`.
- Move your model file from an accessible file location on the server by filling in the field `Remote Path or URL`.
Continue through the popup and fill in information as specified to finish creating the project.
### Analyzing a Model
After model creation, sensitivity analysis for the model are shown under the `Performance Profiles` and `Loss Profiles` in the left navigation.
The profiles will show the effects that different types of algorithms and degrees of those algorithms have on both the models inference speed and the baseline loss.
Performance Profiles:
Loss Profiles:
### Optimizing a Model
Click on the `Optimization` in the left navigation or the `Start Optimizing` button on the analyzing pages to begin sparsifying your model.
After clicking, the sparsification creation popup will be displayed:
Fill in the information as required in the modal.
Once completed, Sparsify's autoML algorithms will choose the best settings it can find for optimizing your model.
The resulting recipe will be displayed along with estimated metrics for the optimized model.
The recipe can then be further edited if desired:
### Exporting a Recipe
Currently Sparsify is focused on training-aware methods; these allow much better loss recovery for a given target performance.
A future release will enable the option of one-shot sparsification with limited to no retraining.
Given that the recipe is created with training-aware algorithms, it must be exported for inclusion in your original training pipeline using [SparseML](https://github.com/neuralmagic/sparseml).
SparseML enables this inclusion with only a few lines of code for most training workflows.
On the optimization page, click the `Export` button in the bottom right.
This will open up the export popup:
Select the framework the model was originally trained in on the upper right of the popup.
Once selected, either copy or download the recipe for use with SparseML.
In addition, some sample code using SparseML is given to integrate the exported sparsification recipe.
## Resources
### Learning More
- Documentation: [SparseML,](https://docs.neuralmagic.com/sparseml/) [SparseZoo,](https://docs.neuralmagic.com/sparsezoo/) [Sparsify,](https://docs.neuralmagic.com/sparsify/) [DeepSparse](https://docs.neuralmagic.com/deepsparse/)
- Neural Magic: [Blog,](https://www.neuralmagic.com/blog/) [Resources](https://www.neuralmagic.com/resources/)
### Release History
Official builds are hosted on PyPI
- stable: [sparsify](https://pypi.org/project/sparsify/)
- nightly (dev): [sparsify-nightly](https://pypi.org/project/sparsify-nightly/)
Additionally, more information can be found via [GitHub Releases.](https://github.com/neuralmagic/sparsify/releases)
### License
The project is licensed under the [Apache License Version 2.0](https://github.com/neuralmagic/sparsify/blob/main/LICENSE).
## Community
### Contribute
We appreciate contributions to the code, examples, integrations, and documentation as well as bug reports and feature requests! [Learn how here.](https://github.com/neuralmagic/sparsify/blob/main/CONTRIBUTING.md)
### Join
For user help or questions about Sparsify, sign up or log in to our [**Neural Magic Community Slack**](https://join.slack.com/t/discuss-neuralmagic/shared_invite/zt-q1a1cnvo-YBoICSIw3L1dmQpjBeDurQ). We are growing the community member by member and happy to see you there. Bugs, feature requests, or additional questions can also be posted to our [GitHub Issue Queue.](https://github.com/neuralmagic/sparsify/issues)
You can get the latest news, webinar and event invites, research papers, and other ML Performance tidbits by [subscribing](https://neuralmagic.com/subscribe/) to the Neural Magic community.
For more general questions about Neural Magic, please fill out this [form.](http://neuralmagic.com/contact/)
### Cite
Find this project useful in your research or other communications? Please consider citing:
```bibtex
@InProceedings{
pmlr-v119-kurtz20a,
title = {Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks},
author = {Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan},
booktitle = {Proceedings of the 37th International Conference on Machine Learning},
pages = {5533--5543},
year = {2020},
editor = {Hal Daumé III and Aarti Singh},
volume = {119},
series = {Proceedings of Machine Learning Research},
address = {Virtual},
month = {13--18 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf},
url = {http://proceedings.mlr.press/v119/kurtz20a.html},
abstract = {Optimizing convolutional neural networks for fast inference has recently become an extremely active area of research. One of the go-to solutions in this context is weight pruning, which aims to reduce computational and memory footprint by removing large subsets of the connections in a neural network. Surprisingly, much less attention has been given to exploiting sparsity in the activation maps, which tend to be naturally sparse in many settings thanks to the structure of rectified linear (ReLU) activation functions. In this paper, we present an in-depth analysis of methods for maximizing the sparsity of the activations in a trained neural network, and show that, when coupled with an efficient sparse-input convolution algorithm, we can leverage this sparsity for significant performance gains. To induce highly sparse activation maps without accuracy loss, we introduce a new regularization technique, coupled with a new threshold-based sparsification method based on a parameterized activation function called Forced-Activation-Threshold Rectified Linear Unit (FATReLU). We examine the impact of our methods on popular image classification models, showing that most architectures can adapt to significantly sparser activation maps without any accuracy loss. Our second contribution is showing that these these compression gains can be translated into inference speedups: we provide a new algorithm to enable fast convolution operations over networks with sparse activations, and show that it can enable significant speedups for end-to-end inference on a range of popular models on the large-scale ImageNet image classification task on modern Intel CPUs, with little or no retraining cost.}
}
```
```bibtex
@misc{
singh2020woodfisher,
title={WoodFisher: Efficient Second-Order Approximation for Neural Network Compression},
author={Sidak Pal Singh and Dan Alistarh},
year={2020},
eprint={2004.14340},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
%prep
%autosetup -n sparsify-nightly-1.6.0.20230616
%build
%py3_build
%install
%py3_install
install -d -m755 %{buildroot}/%{_pkgdocdir}
if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi
if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi
if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi
if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi
pushd %{buildroot}
if [ -d usr/lib ]; then
find usr/lib -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
if [ -d usr/lib64 ]; then
find usr/lib64 -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
if [ -d usr/bin ]; then
find usr/bin -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
if [ -d usr/sbin ]; then
find usr/sbin -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
touch doclist.lst
if [ -d usr/share/man ]; then
find usr/share/man -type f -printf "\"/%h/%f.gz\"\n" >> doclist.lst
fi
popd
mv %{buildroot}/filelist.lst .
mv %{buildroot}/doclist.lst .
%files -n python3-sparsify-nightly -f filelist.lst
%dir %{python3_sitelib}/*
%files help -f doclist.lst
%{_docdir}/*
%changelog
* Tue Jun 20 2023 Python_Bot - 1.6.0.20230616-1
- Package Spec generated