
diff options
| author | CoprDistGit <infra@openeuler.org> | 2023-05-29 12:29:43 +0000 |
|---|---|---|
| committer | CoprDistGit <infra@openeuler.org> | 2023-05-29 12:29:43 +0000 |
| commit | 134e81cf3bed9bae5e13fb1525b89b18f3ddeb31 (patch) | |
| tree | 18f6b83fb69a674bc02de7c641314b4395d31db9 | |
| parent | 92da95c8082435c143c9675d70e8ae622197ccfc (diff) | |
automatic import of python-logparser
| -rw-r--r-- | .gitignore | 1 | ||||
| -rw-r--r-- | python-logparser.spec | 620 | ||||
| -rw-r--r-- | sources | 1 |
3 files changed, 622 insertions, 0 deletions
@@ -0,0 +1 @@ +/logparser-0.8.2.tar.gz diff --git a/python-logparser.spec b/python-logparser.spec new file mode 100644 index 0000000..50dce15 --- /dev/null +++ b/python-logparser.spec @@ -0,0 +1,620 @@ +%global _empty_manifest_terminate_build 0 +Name: python-logparser +Version: 0.8.2 +Release: 1 +Summary: A tool for parsing Scrapy log files periodically and incrementally, designed for ScrapydWeb. +License: GNU General Public License v3.0 +URL: https://github.com/my8100/logparser +Source0: https://mirrors.nju.edu.cn/pypi/web/packages/0e/e1/c2679116e29ff09cb5018635297fbe59ab371eae1d9b913b0e9e22a6e974/logparser-0.8.2.tar.gz +BuildArch: noarch + +Requires: python3-pexpect +Requires: python3-six + +%description +# LogParser: A tool for parsing Scrapy log files periodically and incrementally, designed for [*ScrapydWeb*](https://github.com/my8100/scrapydweb). + +[](https://pypi.org/project/logparser/) +[](https://pypi.org/project/logparser/) +[](https://circleci.com/gh/my8100/logparser/tree/master) +[](https://codecov.io/gh/my8100/logparser) +[](https://coveralls.io/github/my8100/logparser?branch=master) +[](https://pepy.tech/project/logparser) +[](https://github.com/my8100/logparser/blob/master/LICENSE) + + +## Installation +- Use pip: +```bash +pip install logparser +``` +Note that you may need to execute `python -m pip install --upgrade pip` first in order to get the latest version of logparser, or download the tar.gz file from https://pypi.org/project/logparser/#files and get it installed via `pip install logparser-x.x.x.tar.gz` + +- Use git: +```bash +pip install --upgrade git+https://github.com/my8100/logparser.git +``` +Or: +```bash +git clone https://github.com/my8100/logparser.git +cd logparser +python setup.py install +``` + +## Usage +### To use in Python +<details> +<summary>View codes</summary> + +```python +In [1]: from logparser import parse + +In [2]: log = """2018-10-23 18:28:34 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: demo) + ...: 2018-10-23 18:29:41 [scrapy.statscollectors] INFO: Dumping Scrapy stats: + ...: {'downloader/exception_count': 3, + ...: 'downloader/exception_type_count/twisted.internet.error.TCPTimedOutError': 3, + ...: 'downloader/request_bytes': 1336, + ...: 'downloader/request_count': 7, + ...: 'downloader/request_method_count/GET': 7, + ...: 'downloader/response_bytes': 1669, + ...: 'downloader/response_count': 4, + ...: 'downloader/response_status_count/200': 2, + ...: 'downloader/response_status_count/302': 1, + ...: 'downloader/response_status_count/404': 1, + ...: 'dupefilter/filtered': 1, + ...: 'finish_reason': 'finished', + ...: 'finish_time': datetime.datetime(2018, 10, 23, 10, 29, 41, 174719), + ...: 'httperror/response_ignored_count': 1, + ...: 'httperror/response_ignored_status_count/404': 1, + ...: 'item_scraped_count': 2, + ...: 'log_count/CRITICAL': 5, + ...: 'log_count/DEBUG': 14, + ...: 'log_count/ERROR': 5, + ...: 'log_count/INFO': 75, + ...: 'log_count/WARNING': 3, + ...: 'offsite/domains': 1, + ...: 'offsite/filtered': 1, + ...: 'request_depth_max': 1, + ...: 'response_received_count': 3, + ...: 'retry/count': 2, + ...: 'retry/max_reached': 1, + ...: 'retry/reason_count/twisted.internet.error.TCPTimedOutError': 2, + ...: 'scheduler/dequeued': 7, + ...: 'scheduler/dequeued/memory': 7, + ...: 'scheduler/enqueued': 7, + ...: 'scheduler/enqueued/memory': 7, + ...: 'start_time': datetime.datetime(2018, 10, 23, 10, 28, 35, 70938)} + ...: 2018-10-23 18:29:42 [scrapy.core.engine] INFO: Spider closed (finished)""" + +In [3]: odict = parse(log, headlines=1, taillines=1) + +In [4]: odict +Out[4]: +OrderedDict([('head', + '2018-10-23 18:28:34 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: demo)'), + ('tail', + '2018-10-23 18:29:42 [scrapy.core.engine] INFO: Spider closed (finished)'), + ('first_log_time', '2018-10-23 18:28:34'), + ('latest_log_time', '2018-10-23 18:29:42'), + ('runtime', '0:01:08'), + ('first_log_timestamp', 1540290514), + ('latest_log_timestamp', 1540290582), + ('datas', []), + ('pages', 3), + ('items', 2), + ('latest_matches', + {'telnet_console': '', + 'resuming_crawl': '', + 'latest_offsite': '', + 'latest_duplicate': '', + 'latest_crawl': '', + 'latest_scrape': '', + 'latest_item': '', + 'latest_stat': ''}), + ('latest_crawl_timestamp', 0), + ('latest_scrape_timestamp', 0), + ('log_categories', + {'critical_logs': {'count': 5, 'details': []}, + 'error_logs': {'count': 5, 'details': []}, + 'warning_logs': {'count': 3, 'details': []}, + 'redirect_logs': {'count': 1, 'details': []}, + 'retry_logs': {'count': 2, 'details': []}, + 'ignore_logs': {'count': 1, 'details': []}}), + ('shutdown_reason', 'N/A'), + ('finish_reason', 'finished'), + ('crawler_stats', + OrderedDict([('source', 'log'), + ('last_update_time', '2018-10-23 18:29:41'), + ('last_update_timestamp', 1540290581), + ('downloader/exception_count', 3), + ('downloader/exception_type_count/twisted.internet.error.TCPTimedOutError', + 3), + ('downloader/request_bytes', 1336), + ('downloader/request_count', 7), + ('downloader/request_method_count/GET', 7), + ('downloader/response_bytes', 1669), + ('downloader/response_count', 4), + ('downloader/response_status_count/200', 2), + ('downloader/response_status_count/302', 1), + ('downloader/response_status_count/404', 1), + ('dupefilter/filtered', 1), + ('finish_reason', 'finished'), + ('finish_time', + 'datetime.datetime(2018, 10, 23, 10, 29, 41, 174719)'), + ('httperror/response_ignored_count', 1), + ('httperror/response_ignored_status_count/404', 1), + ('item_scraped_count', 2), + ('log_count/CRITICAL', 5), + ('log_count/DEBUG', 14), + ('log_count/ERROR', 5), + ('log_count/INFO', 75), + ('log_count/WARNING', 3), + ('offsite/domains', 1), + ('offsite/filtered', 1), + ('request_depth_max', 1), + ('response_received_count', 3), + ('retry/count', 2), + ('retry/max_reached', 1), + ('retry/reason_count/twisted.internet.error.TCPTimedOutError', + 2), + ('scheduler/dequeued', 7), + ('scheduler/dequeued/memory', 7), + ('scheduler/enqueued', 7), + ('scheduler/enqueued/memory', 7), + ('start_time', + 'datetime.datetime(2018, 10, 23, 10, 28, 35, 70938)')])), + ('last_update_time', '2019-03-08 16:53:50'), + ('last_update_timestamp', 1552035230), + ('logparser_version', '0.8.1')]) + +In [5]: odict['runtime'] +Out[5]: '0:01:08' + +In [6]: odict['pages'] +Out[6]: 3 + +In [7]: odict['items'] +Out[7]: 2 + +In [8]: odict['finish_reason'] +Out[8]: 'finished' +``` + +</details> + +### To run as a service +1. **Make sure that [*Scrapyd*](https://github.com/scrapy/scrapyd) has been installed and started on the current host.** +2. Start ***LogParser*** via command `logparser` +3. Visit http://127.0.0.1:6800/logs/stats.json **(Assuming the Scrapyd service runs on port 6800.)** +4. Visit http://127.0.0.1:6800/logs/projectname/spidername/jobid.json to get stats of a job in details. + +### To work with *ScrapydWeb* for visualization +Check out https://github.com/my8100/scrapydweb for more info. + +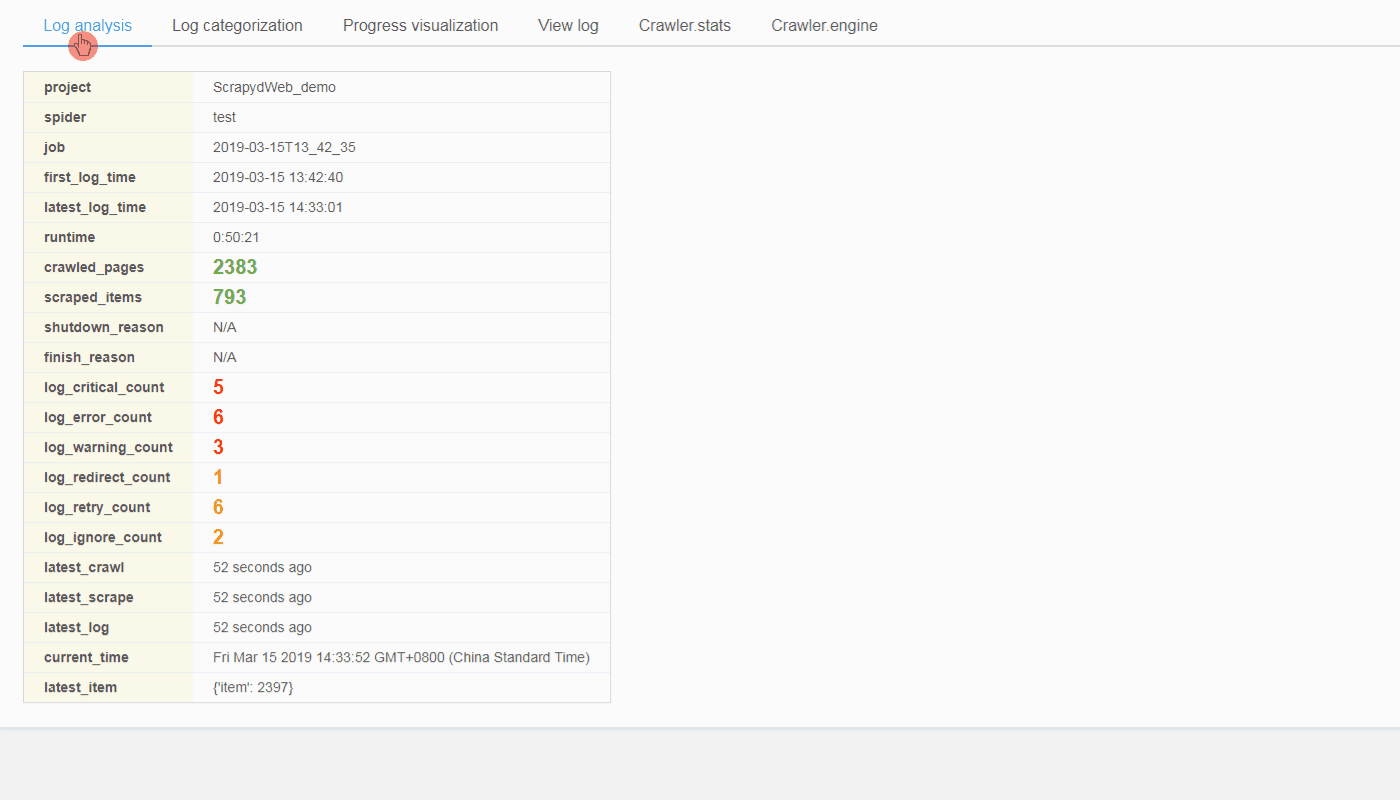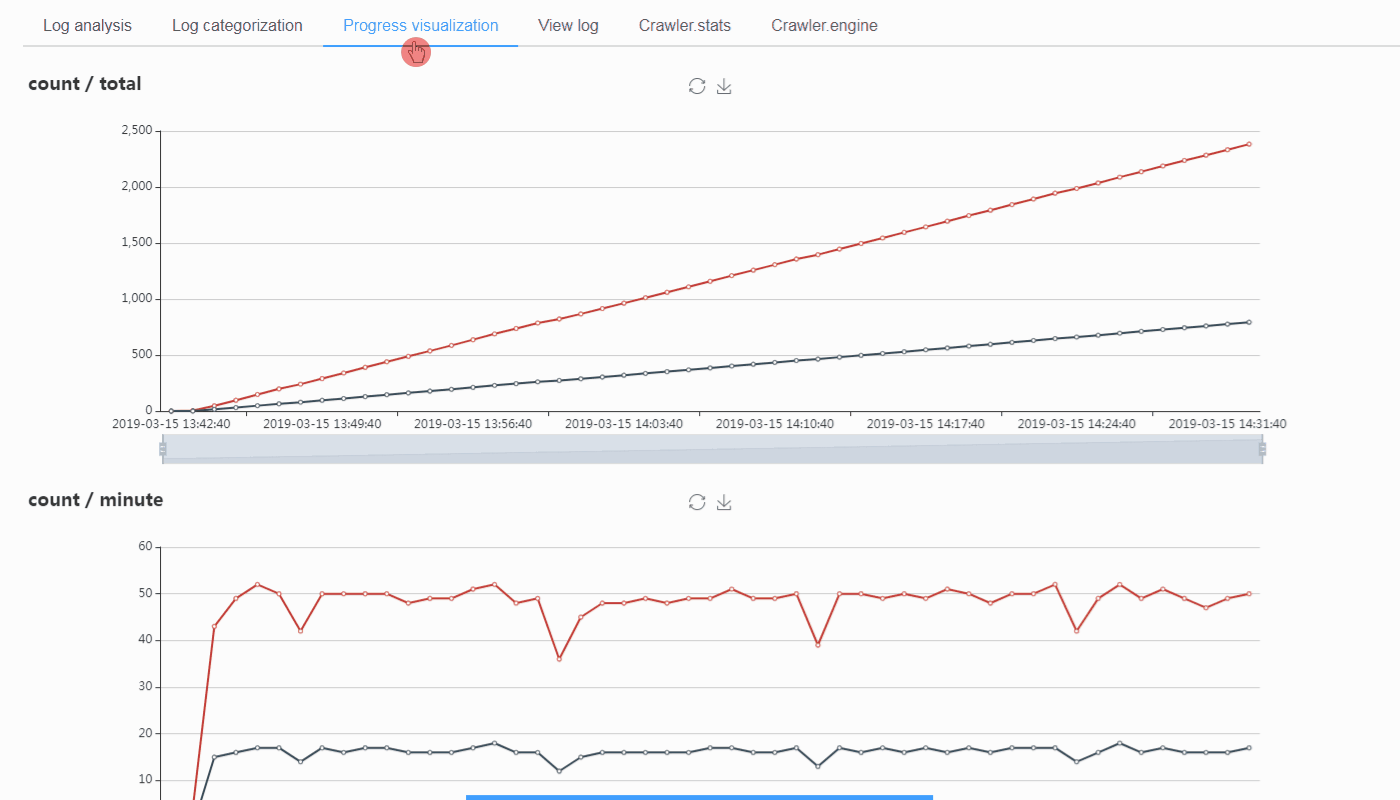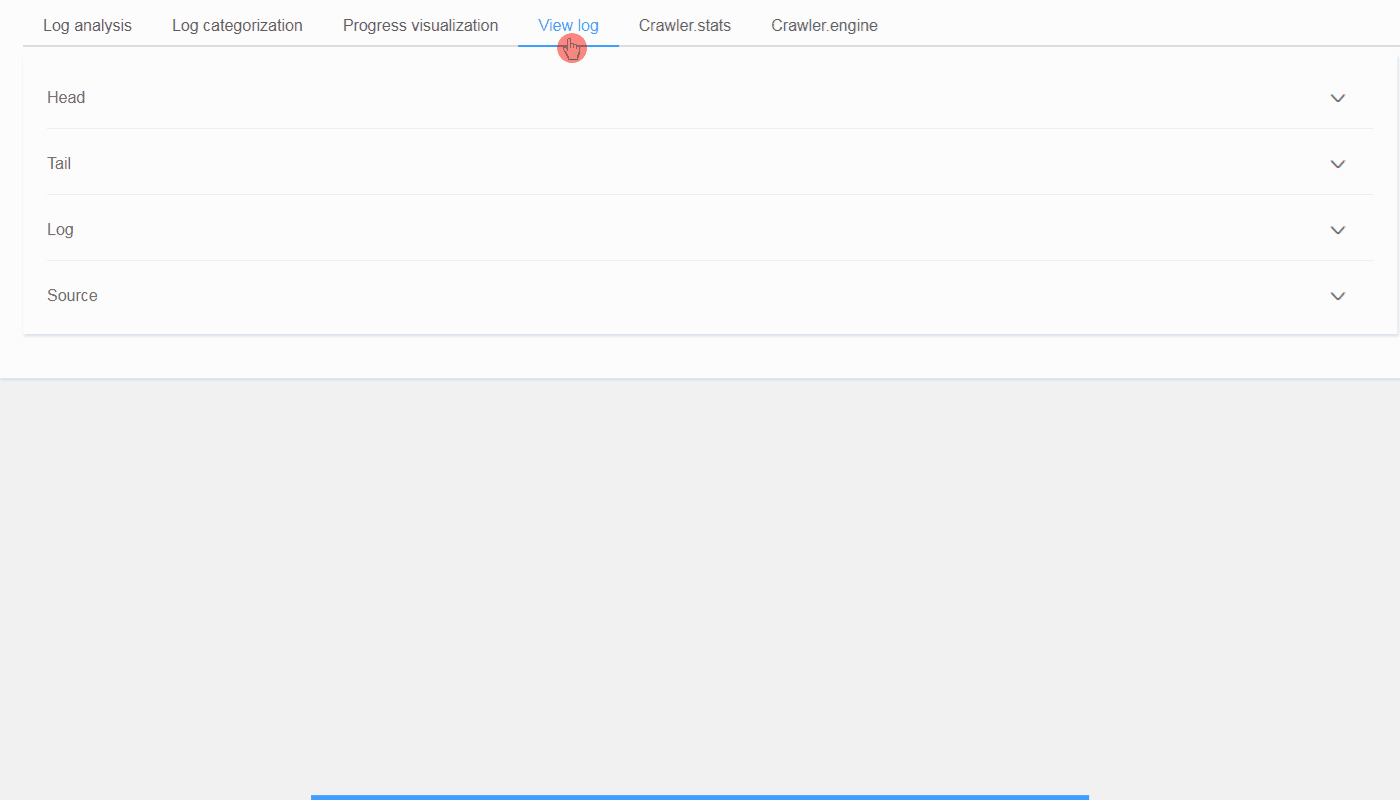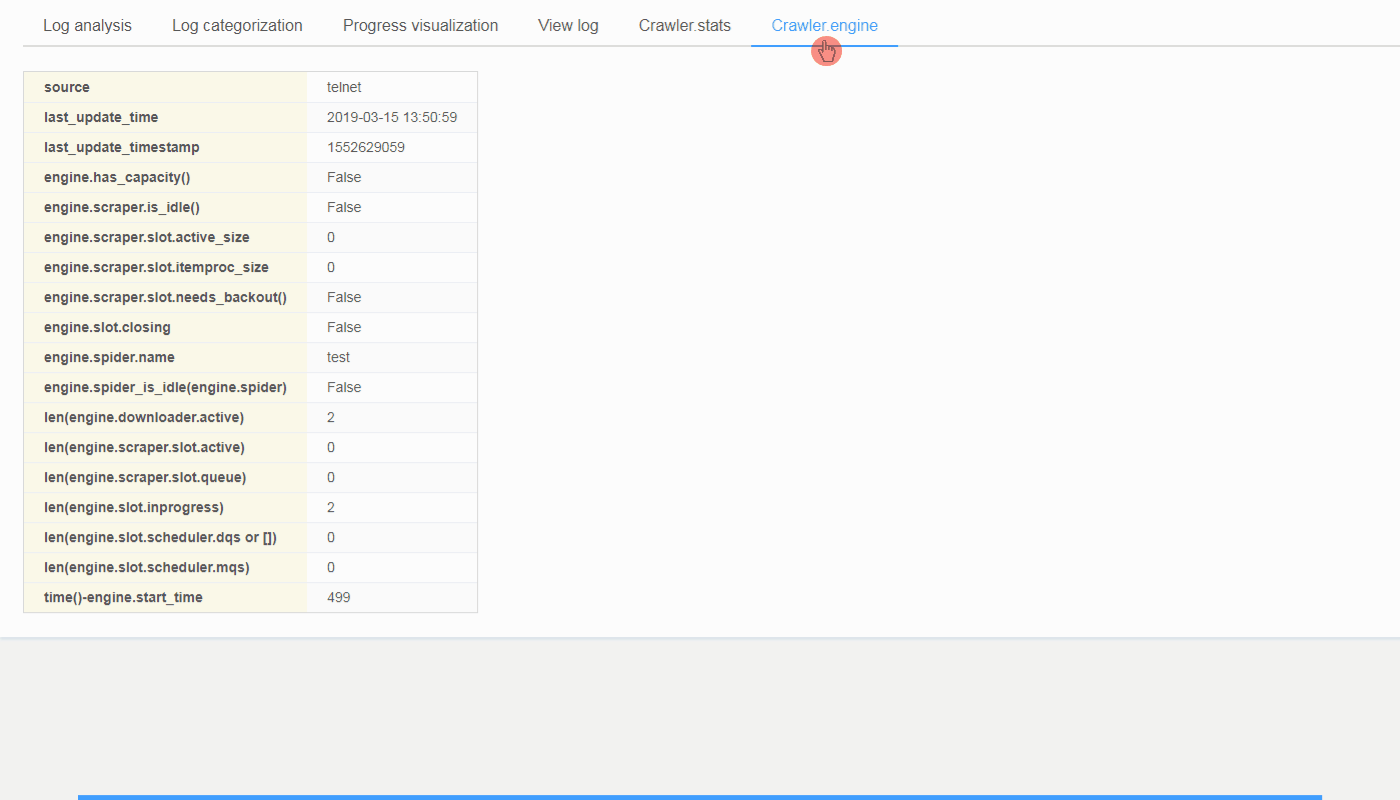 + + + + +%package -n python3-logparser +Summary: A tool for parsing Scrapy log files periodically and incrementally, designed for ScrapydWeb. +Provides: python-logparser +BuildRequires: python3-devel +BuildRequires: python3-setuptools +BuildRequires: python3-pip +%description -n python3-logparser +# LogParser: A tool for parsing Scrapy log files periodically and incrementally, designed for [*ScrapydWeb*](https://github.com/my8100/scrapydweb). + +[](https://pypi.org/project/logparser/) +[](https://pypi.org/project/logparser/) +[](https://circleci.com/gh/my8100/logparser/tree/master) +[](https://codecov.io/gh/my8100/logparser) +[](https://coveralls.io/github/my8100/logparser?branch=master) +[](https://pepy.tech/project/logparser) +[](https://github.com/my8100/logparser/blob/master/LICENSE) + + +## Installation +- Use pip: +```bash +pip install logparser +``` +Note that you may need to execute `python -m pip install --upgrade pip` first in order to get the latest version of logparser, or download the tar.gz file from https://pypi.org/project/logparser/#files and get it installed via `pip install logparser-x.x.x.tar.gz` + +- Use git: +```bash +pip install --upgrade git+https://github.com/my8100/logparser.git +``` +Or: +```bash +git clone https://github.com/my8100/logparser.git +cd logparser +python setup.py install +``` + +## Usage +### To use in Python +<details> +<summary>View codes</summary> + +```python +In [1]: from logparser import parse + +In [2]: log = """2018-10-23 18:28:34 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: demo) + ...: 2018-10-23 18:29:41 [scrapy.statscollectors] INFO: Dumping Scrapy stats: + ...: {'downloader/exception_count': 3, + ...: 'downloader/exception_type_count/twisted.internet.error.TCPTimedOutError': 3, + ...: 'downloader/request_bytes': 1336, + ...: 'downloader/request_count': 7, + ...: 'downloader/request_method_count/GET': 7, + ...: 'downloader/response_bytes': 1669, + ...: 'downloader/response_count': 4, + ...: 'downloader/response_status_count/200': 2, + ...: 'downloader/response_status_count/302': 1, + ...: 'downloader/response_status_count/404': 1, + ...: 'dupefilter/filtered': 1, + ...: 'finish_reason': 'finished', + ...: 'finish_time': datetime.datetime(2018, 10, 23, 10, 29, 41, 174719), + ...: 'httperror/response_ignored_count': 1, + ...: 'httperror/response_ignored_status_count/404': 1, + ...: 'item_scraped_count': 2, + ...: 'log_count/CRITICAL': 5, + ...: 'log_count/DEBUG': 14, + ...: 'log_count/ERROR': 5, + ...: 'log_count/INFO': 75, + ...: 'log_count/WARNING': 3, + ...: 'offsite/domains': 1, + ...: 'offsite/filtered': 1, + ...: 'request_depth_max': 1, + ...: 'response_received_count': 3, + ...: 'retry/count': 2, + ...: 'retry/max_reached': 1, + ...: 'retry/reason_count/twisted.internet.error.TCPTimedOutError': 2, + ...: 'scheduler/dequeued': 7, + ...: 'scheduler/dequeued/memory': 7, + ...: 'scheduler/enqueued': 7, + ...: 'scheduler/enqueued/memory': 7, + ...: 'start_time': datetime.datetime(2018, 10, 23, 10, 28, 35, 70938)} + ...: 2018-10-23 18:29:42 [scrapy.core.engine] INFO: Spider closed (finished)""" + +In [3]: odict = parse(log, headlines=1, taillines=1) + +In [4]: odict +Out[4]: +OrderedDict([('head', + '2018-10-23 18:28:34 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: demo)'), + ('tail', + '2018-10-23 18:29:42 [scrapy.core.engine] INFO: Spider closed (finished)'), + ('first_log_time', '2018-10-23 18:28:34'), + ('latest_log_time', '2018-10-23 18:29:42'), + ('runtime', '0:01:08'), + ('first_log_timestamp', 1540290514), + ('latest_log_timestamp', 1540290582), + ('datas', []), + ('pages', 3), + ('items', 2), + ('latest_matches', + {'telnet_console': '', + 'resuming_crawl': '', + 'latest_offsite': '', + 'latest_duplicate': '', + 'latest_crawl': '', + 'latest_scrape': '', + 'latest_item': '', + 'latest_stat': ''}), + ('latest_crawl_timestamp', 0), + ('latest_scrape_timestamp', 0), + ('log_categories', + {'critical_logs': {'count': 5, 'details': []}, + 'error_logs': {'count': 5, 'details': []}, + 'warning_logs': {'count': 3, 'details': []}, + 'redirect_logs': {'count': 1, 'details': []}, + 'retry_logs': {'count': 2, 'details': []}, + 'ignore_logs': {'count': 1, 'details': []}}), + ('shutdown_reason', 'N/A'), + ('finish_reason', 'finished'), + ('crawler_stats', + OrderedDict([('source', 'log'), + ('last_update_time', '2018-10-23 18:29:41'), + ('last_update_timestamp', 1540290581), + ('downloader/exception_count', 3), + ('downloader/exception_type_count/twisted.internet.error.TCPTimedOutError', + 3), + ('downloader/request_bytes', 1336), + ('downloader/request_count', 7), + ('downloader/request_method_count/GET', 7), + ('downloader/response_bytes', 1669), + ('downloader/response_count', 4), + ('downloader/response_status_count/200', 2), + ('downloader/response_status_count/302', 1), + ('downloader/response_status_count/404', 1), + ('dupefilter/filtered', 1), + ('finish_reason', 'finished'), + ('finish_time', + 'datetime.datetime(2018, 10, 23, 10, 29, 41, 174719)'), + ('httperror/response_ignored_count', 1), + ('httperror/response_ignored_status_count/404', 1), + ('item_scraped_count', 2), + ('log_count/CRITICAL', 5), + ('log_count/DEBUG', 14), + ('log_count/ERROR', 5), + ('log_count/INFO', 75), + ('log_count/WARNING', 3), + ('offsite/domains', 1), + ('offsite/filtered', 1), + ('request_depth_max', 1), + ('response_received_count', 3), + ('retry/count', 2), + ('retry/max_reached', 1), + ('retry/reason_count/twisted.internet.error.TCPTimedOutError', + 2), + ('scheduler/dequeued', 7), + ('scheduler/dequeued/memory', 7), + ('scheduler/enqueued', 7), + ('scheduler/enqueued/memory', 7), + ('start_time', + 'datetime.datetime(2018, 10, 23, 10, 28, 35, 70938)')])), + ('last_update_time', '2019-03-08 16:53:50'), + ('last_update_timestamp', 1552035230), + ('logparser_version', '0.8.1')]) + +In [5]: odict['runtime'] +Out[5]: '0:01:08' + +In [6]: odict['pages'] +Out[6]: 3 + +In [7]: odict['items'] +Out[7]: 2 + +In [8]: odict['finish_reason'] +Out[8]: 'finished' +``` + +</details> + +### To run as a service +1. **Make sure that [*Scrapyd*](https://github.com/scrapy/scrapyd) has been installed and started on the current host.** +2. Start ***LogParser*** via command `logparser` +3. Visit http://127.0.0.1:6800/logs/stats.json **(Assuming the Scrapyd service runs on port 6800.)** +4. Visit http://127.0.0.1:6800/logs/projectname/spidername/jobid.json to get stats of a job in details. + +### To work with *ScrapydWeb* for visualization +Check out https://github.com/my8100/scrapydweb for more info. + + + + + + +%package help +Summary: Development documents and examples for logparser +Provides: python3-logparser-doc +%description help +# LogParser: A tool for parsing Scrapy log files periodically and incrementally, designed for [*ScrapydWeb*](https://github.com/my8100/scrapydweb). + +[](https://pypi.org/project/logparser/) +[](https://pypi.org/project/logparser/) +[](https://circleci.com/gh/my8100/logparser/tree/master) +[](https://codecov.io/gh/my8100/logparser) +[](https://coveralls.io/github/my8100/logparser?branch=master) +[](https://pepy.tech/project/logparser) +[](https://github.com/my8100/logparser/blob/master/LICENSE) + + +## Installation +- Use pip: +```bash +pip install logparser +``` +Note that you may need to execute `python -m pip install --upgrade pip` first in order to get the latest version of logparser, or download the tar.gz file from https://pypi.org/project/logparser/#files and get it installed via `pip install logparser-x.x.x.tar.gz` + +- Use git: +```bash +pip install --upgrade git+https://github.com/my8100/logparser.git +``` +Or: +```bash +git clone https://github.com/my8100/logparser.git +cd logparser +python setup.py install +``` + +## Usage +### To use in Python +<details> +<summary>View codes</summary> + +```python +In [1]: from logparser import parse + +In [2]: log = """2018-10-23 18:28:34 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: demo) + ...: 2018-10-23 18:29:41 [scrapy.statscollectors] INFO: Dumping Scrapy stats: + ...: {'downloader/exception_count': 3, + ...: 'downloader/exception_type_count/twisted.internet.error.TCPTimedOutError': 3, + ...: 'downloader/request_bytes': 1336, + ...: 'downloader/request_count': 7, + ...: 'downloader/request_method_count/GET': 7, + ...: 'downloader/response_bytes': 1669, + ...: 'downloader/response_count': 4, + ...: 'downloader/response_status_count/200': 2, + ...: 'downloader/response_status_count/302': 1, + ...: 'downloader/response_status_count/404': 1, + ...: 'dupefilter/filtered': 1, + ...: 'finish_reason': 'finished', + ...: 'finish_time': datetime.datetime(2018, 10, 23, 10, 29, 41, 174719), + ...: 'httperror/response_ignored_count': 1, + ...: 'httperror/response_ignored_status_count/404': 1, + ...: 'item_scraped_count': 2, + ...: 'log_count/CRITICAL': 5, + ...: 'log_count/DEBUG': 14, + ...: 'log_count/ERROR': 5, + ...: 'log_count/INFO': 75, + ...: 'log_count/WARNING': 3, + ...: 'offsite/domains': 1, + ...: 'offsite/filtered': 1, + ...: 'request_depth_max': 1, + ...: 'response_received_count': 3, + ...: 'retry/count': 2, + ...: 'retry/max_reached': 1, + ...: 'retry/reason_count/twisted.internet.error.TCPTimedOutError': 2, + ...: 'scheduler/dequeued': 7, + ...: 'scheduler/dequeued/memory': 7, + ...: 'scheduler/enqueued': 7, + ...: 'scheduler/enqueued/memory': 7, + ...: 'start_time': datetime.datetime(2018, 10, 23, 10, 28, 35, 70938)} + ...: 2018-10-23 18:29:42 [scrapy.core.engine] INFO: Spider closed (finished)""" + +In [3]: odict = parse(log, headlines=1, taillines=1) + +In [4]: odict +Out[4]: +OrderedDict([('head', + '2018-10-23 18:28:34 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: demo)'), + ('tail', + '2018-10-23 18:29:42 [scrapy.core.engine] INFO: Spider closed (finished)'), + ('first_log_time', '2018-10-23 18:28:34'), + ('latest_log_time', '2018-10-23 18:29:42'), + ('runtime', '0:01:08'), + ('first_log_timestamp', 1540290514), + ('latest_log_timestamp', 1540290582), + ('datas', []), + ('pages', 3), + ('items', 2), + ('latest_matches', + {'telnet_console': '', + 'resuming_crawl': '', + 'latest_offsite': '', + 'latest_duplicate': '', + 'latest_crawl': '', + 'latest_scrape': '', + 'latest_item': '', + 'latest_stat': ''}), + ('latest_crawl_timestamp', 0), + ('latest_scrape_timestamp', 0), + ('log_categories', + {'critical_logs': {'count': 5, 'details': []}, + 'error_logs': {'count': 5, 'details': []}, + 'warning_logs': {'count': 3, 'details': []}, + 'redirect_logs': {'count': 1, 'details': []}, + 'retry_logs': {'count': 2, 'details': []}, + 'ignore_logs': {'count': 1, 'details': []}}), + ('shutdown_reason', 'N/A'), + ('finish_reason', 'finished'), + ('crawler_stats', + OrderedDict([('source', 'log'), + ('last_update_time', '2018-10-23 18:29:41'), + ('last_update_timestamp', 1540290581), + ('downloader/exception_count', 3), + ('downloader/exception_type_count/twisted.internet.error.TCPTimedOutError', + 3), + ('downloader/request_bytes', 1336), + ('downloader/request_count', 7), + ('downloader/request_method_count/GET', 7), + ('downloader/response_bytes', 1669), + ('downloader/response_count', 4), + ('downloader/response_status_count/200', 2), + ('downloader/response_status_count/302', 1), + ('downloader/response_status_count/404', 1), + ('dupefilter/filtered', 1), + ('finish_reason', 'finished'), + ('finish_time', + 'datetime.datetime(2018, 10, 23, 10, 29, 41, 174719)'), + ('httperror/response_ignored_count', 1), + ('httperror/response_ignored_status_count/404', 1), + ('item_scraped_count', 2), + ('log_count/CRITICAL', 5), + ('log_count/DEBUG', 14), + ('log_count/ERROR', 5), + ('log_count/INFO', 75), + ('log_count/WARNING', 3), + ('offsite/domains', 1), + ('offsite/filtered', 1), + ('request_depth_max', 1), + ('response_received_count', 3), + ('retry/count', 2), + ('retry/max_reached', 1), + ('retry/reason_count/twisted.internet.error.TCPTimedOutError', + 2), + ('scheduler/dequeued', 7), + ('scheduler/dequeued/memory', 7), + ('scheduler/enqueued', 7), + ('scheduler/enqueued/memory', 7), + ('start_time', + 'datetime.datetime(2018, 10, 23, 10, 28, 35, 70938)')])), + ('last_update_time', '2019-03-08 16:53:50'), + ('last_update_timestamp', 1552035230), + ('logparser_version', '0.8.1')]) + +In [5]: odict['runtime'] +Out[5]: '0:01:08' + +In [6]: odict['pages'] +Out[6]: 3 + +In [7]: odict['items'] +Out[7]: 2 + +In [8]: odict['finish_reason'] +Out[8]: 'finished' +``` + +</details> + +### To run as a service +1. **Make sure that [*Scrapyd*](https://github.com/scrapy/scrapyd) has been installed and started on the current host.** +2. Start ***LogParser*** via command `logparser` +3. Visit http://127.0.0.1:6800/logs/stats.json **(Assuming the Scrapyd service runs on port 6800.)** +4. Visit http://127.0.0.1:6800/logs/projectname/spidername/jobid.json to get stats of a job in details. + +### To work with *ScrapydWeb* for visualization +Check out https://github.com/my8100/scrapydweb for more info. + + + + + + +%prep +%autosetup -n logparser-0.8.2 + +%build +%py3_build + +%install +%py3_install +install -d -m755 %{buildroot}/%{_pkgdocdir} +if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi +if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi +if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi +if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi +pushd %{buildroot} +if [ -d usr/lib ]; then + find usr/lib -type f -printf "/%h/%f\n" >> filelist.lst +fi +if [ -d usr/lib64 ]; then + find usr/lib64 -type f -printf "/%h/%f\n" >> filelist.lst +fi +if [ -d usr/bin ]; then + find usr/bin -type f -printf "/%h/%f\n" >> filelist.lst +fi +if [ -d usr/sbin ]; then + find usr/sbin -type f -printf "/%h/%f\n" >> filelist.lst +fi +touch doclist.lst +if [ -d usr/share/man ]; then + find usr/share/man -type f -printf "/%h/%f.gz\n" >> doclist.lst +fi +popd +mv %{buildroot}/filelist.lst . +mv %{buildroot}/doclist.lst . + +%files -n python3-logparser -f filelist.lst +%dir %{python3_sitelib}/* + +%files help -f doclist.lst +%{_docdir}/* + +%changelog +* Mon May 29 2023 Python_Bot <Python_Bot@openeuler.org> - 0.8.2-1 +- Package Spec generated @@ -0,0 +1 @@ +11bed4a1de8927840325600137aa6be4 logparser-0.8.2.tar.gz |