
diff options
| author | CoprDistGit <infra@openeuler.org> | 2023-05-10 05:24:50 +0000 |
|---|---|---|
| committer | CoprDistGit <infra@openeuler.org> | 2023-05-10 05:24:50 +0000 |
| commit | 889b6774d926bdb6d575d9dd32c6e820341101da (patch) | |
| tree | 2cb00549bd5b45e997fb4e03040eef45d36ba71d | |
| parent | bd3cd4be20466550a73bc9cbd6abd68682c65077 (diff) | |
automatic import of python-attacutopeneuler20.03
| -rw-r--r-- | .gitignore | 1 | ||||
| -rw-r--r-- | python-attacut.spec | 362 | ||||
| -rw-r--r-- | sources | 1 |
3 files changed, 364 insertions, 0 deletions
@@ -0,0 +1 @@ +/attacut-1.0.6.tar.gz diff --git a/python-attacut.spec b/python-attacut.spec new file mode 100644 index 0000000..bc6af0e --- /dev/null +++ b/python-attacut.spec @@ -0,0 +1,362 @@ +%global _empty_manifest_terminate_build 0 +Name: python-attacut +Version: 1.0.6 +Release: 1 +Summary: Fast and Reasonably Accurate Word Tokenizer for Thai +License: MIT License +URL: https://github.com/PyThaiNLP/attacut +Source0: https://mirrors.nju.edu.cn/pypi/web/packages/9c/08/6b905097d1cd72dabc50b867c68bda1f971412a7dfee37b5b68fae997258/attacut-1.0.6.tar.gz +BuildArch: noarch + +Requires: python3-docopt +Requires: python3-fire +Requires: python3-nptyping +Requires: python3-numpy +Requires: python3-pyyaml +Requires: python3-six +Requires: python3-ssg +Requires: python3-torch + +%description +# AttaCut: Fast and Reasonably Accurate Word Tokenizer for Thai + +[](https://travis-ci.org/PyThaiNLP/attacut) +[](https://ci.appveyor.com/project/wannaphongcom/attacut/branch/master) +[](https://drive.google.com/file/d/16AUNZv1HXVmERgryfBf4JpCo1QrQyHHE/view?usp=sharing) +[](https://arxiv.org/abs/1911.07056) + +## How does AttaCut look like? + +<div align="center"> + <img src="https://i.imgur.com/8yMq7IB.png" width="700px"/> + <br/> + <b>TL;DR:</b> +3-Layer Dilated CNN on syllable and character features. It’s <b>6x faster</b> than DeepCut (SOTA) while its WL-f1 on BEST is <b>91%</b>, only 2% lower. +</div> + +## Installation + +``` +$ pip install attacut +``` + +**Remarks:** Windows users need to install **PyTorch** before the command above. +Please consult [PyTorch.org](https://pytorch.org) for more details. + +## Usage + +### Command-Line Interface + +``` +$ attacut-cli -h +AttaCut: Fast and Reasonably Accurate Word Tokenizer for Thai + +Usage: + attacut-cli <src> [--dest=<dest>] [--model=<model>] + attacut-cli [-v | --version] + attacut-cli [-h | --help] + +Arguments: + <src> Path to input text file to be tokenized + +Options: + -h --help Show this screen. + --model=<model> Model to be used [default: attacut-sc]. + --dest=<dest> If not specified, it'll be <src>-tokenized-by-<model>.txt + -v --version Show version +``` + +### High-Level API +``` +from attacut import tokenize, Tokenizer + +# tokenize `txt` using our best model `attacut-sc` +words = tokenize(txt) + +# alternatively, an AttaCut tokenizer might be instantiated directly, allowing +# one to specify whether to use `attacut-sc` or `attacut-c`. +atta = Tokenizer(model="attacut-sc") +words = atta.tokenize(txt) +``` + +## Benchmark Results + +Belows are brief summaries. More details can be found on [our benchmarking page](https://pythainlp.github.io/attacut/benchmark.html). + + +### Tokenization Quality +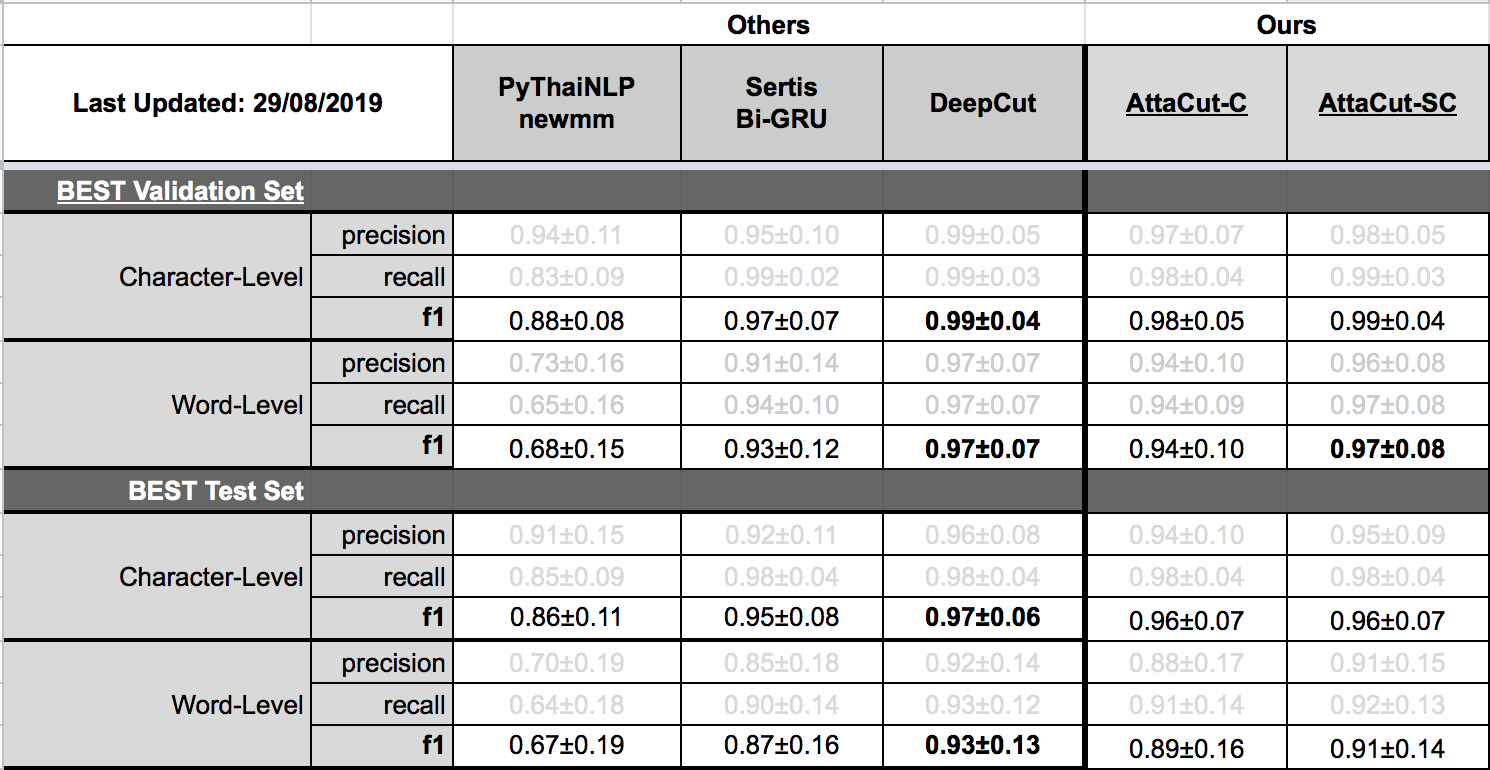 + +### Speed +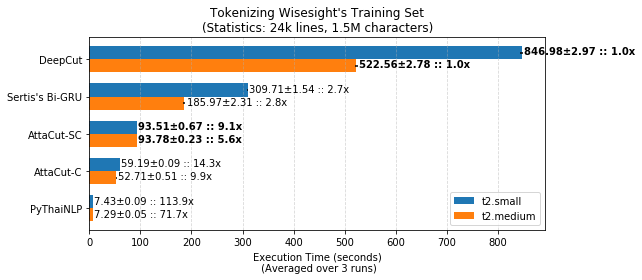 + + +## Retraining on Custom Dataset +Please refer to [our retraining page](https://pythainlp.github.io/attacut/) + +## Related Resources +- [Tokenization Visualization][tovis] +- [Thai Tokenizer Dockers][docker] + +## Acknowledgements +This repository was initially done by [Pattarawat Chormai][pat], while interning at [Dr. Attapol Thamrongrattanarit's NLP Lab][ate], Chulalongkorn University, Bangkok, Thailand. +Many people have involed in this project. Complete list of names can be found on [Acknowledgement](https://pythainlp.github.io/attacut/acknowledgement.html). + + +[pat]: http://pat.chormai.org +[ate]: https://attapol.github.io/lab.html +[noom]: https://github.com/Ekkalak-T +[can]: https://github.com/c4n +[ake]: https://github.com/ekapolc +[tovis]: https://pythainlp.github.io/tokenization-benchmark-visualization/ +[docker]: https://github.com/PyThaiNLP/docker-thai-tokenizers + + + + +%package -n python3-attacut +Summary: Fast and Reasonably Accurate Word Tokenizer for Thai +Provides: python-attacut +BuildRequires: python3-devel +BuildRequires: python3-setuptools +BuildRequires: python3-pip +%description -n python3-attacut +# AttaCut: Fast and Reasonably Accurate Word Tokenizer for Thai + +[](https://travis-ci.org/PyThaiNLP/attacut) +[](https://ci.appveyor.com/project/wannaphongcom/attacut/branch/master) +[](https://drive.google.com/file/d/16AUNZv1HXVmERgryfBf4JpCo1QrQyHHE/view?usp=sharing) +[](https://arxiv.org/abs/1911.07056) + +## How does AttaCut look like? + +<div align="center"> + <img src="https://i.imgur.com/8yMq7IB.png" width="700px"/> + <br/> + <b>TL;DR:</b> +3-Layer Dilated CNN on syllable and character features. It’s <b>6x faster</b> than DeepCut (SOTA) while its WL-f1 on BEST is <b>91%</b>, only 2% lower. +</div> + +## Installation + +``` +$ pip install attacut +``` + +**Remarks:** Windows users need to install **PyTorch** before the command above. +Please consult [PyTorch.org](https://pytorch.org) for more details. + +## Usage + +### Command-Line Interface + +``` +$ attacut-cli -h +AttaCut: Fast and Reasonably Accurate Word Tokenizer for Thai + +Usage: + attacut-cli <src> [--dest=<dest>] [--model=<model>] + attacut-cli [-v | --version] + attacut-cli [-h | --help] + +Arguments: + <src> Path to input text file to be tokenized + +Options: + -h --help Show this screen. + --model=<model> Model to be used [default: attacut-sc]. + --dest=<dest> If not specified, it'll be <src>-tokenized-by-<model>.txt + -v --version Show version +``` + +### High-Level API +``` +from attacut import tokenize, Tokenizer + +# tokenize `txt` using our best model `attacut-sc` +words = tokenize(txt) + +# alternatively, an AttaCut tokenizer might be instantiated directly, allowing +# one to specify whether to use `attacut-sc` or `attacut-c`. +atta = Tokenizer(model="attacut-sc") +words = atta.tokenize(txt) +``` + +## Benchmark Results + +Belows are brief summaries. More details can be found on [our benchmarking page](https://pythainlp.github.io/attacut/benchmark.html). + + +### Tokenization Quality + + +### Speed + + + +## Retraining on Custom Dataset +Please refer to [our retraining page](https://pythainlp.github.io/attacut/) + +## Related Resources +- [Tokenization Visualization][tovis] +- [Thai Tokenizer Dockers][docker] + +## Acknowledgements +This repository was initially done by [Pattarawat Chormai][pat], while interning at [Dr. Attapol Thamrongrattanarit's NLP Lab][ate], Chulalongkorn University, Bangkok, Thailand. +Many people have involed in this project. Complete list of names can be found on [Acknowledgement](https://pythainlp.github.io/attacut/acknowledgement.html). + + +[pat]: http://pat.chormai.org +[ate]: https://attapol.github.io/lab.html +[noom]: https://github.com/Ekkalak-T +[can]: https://github.com/c4n +[ake]: https://github.com/ekapolc +[tovis]: https://pythainlp.github.io/tokenization-benchmark-visualization/ +[docker]: https://github.com/PyThaiNLP/docker-thai-tokenizers + + + + +%package help +Summary: Development documents and examples for attacut +Provides: python3-attacut-doc +%description help +# AttaCut: Fast and Reasonably Accurate Word Tokenizer for Thai + +[](https://travis-ci.org/PyThaiNLP/attacut) +[](https://ci.appveyor.com/project/wannaphongcom/attacut/branch/master) +[](https://drive.google.com/file/d/16AUNZv1HXVmERgryfBf4JpCo1QrQyHHE/view?usp=sharing) +[](https://arxiv.org/abs/1911.07056) + +## How does AttaCut look like? + +<div align="center"> + <img src="https://i.imgur.com/8yMq7IB.png" width="700px"/> + <br/> + <b>TL;DR:</b> +3-Layer Dilated CNN on syllable and character features. It’s <b>6x faster</b> than DeepCut (SOTA) while its WL-f1 on BEST is <b>91%</b>, only 2% lower. +</div> + +## Installation + +``` +$ pip install attacut +``` + +**Remarks:** Windows users need to install **PyTorch** before the command above. +Please consult [PyTorch.org](https://pytorch.org) for more details. + +## Usage + +### Command-Line Interface + +``` +$ attacut-cli -h +AttaCut: Fast and Reasonably Accurate Word Tokenizer for Thai + +Usage: + attacut-cli <src> [--dest=<dest>] [--model=<model>] + attacut-cli [-v | --version] + attacut-cli [-h | --help] + +Arguments: + <src> Path to input text file to be tokenized + +Options: + -h --help Show this screen. + --model=<model> Model to be used [default: attacut-sc]. + --dest=<dest> If not specified, it'll be <src>-tokenized-by-<model>.txt + -v --version Show version +``` + +### High-Level API +``` +from attacut import tokenize, Tokenizer + +# tokenize `txt` using our best model `attacut-sc` +words = tokenize(txt) + +# alternatively, an AttaCut tokenizer might be instantiated directly, allowing +# one to specify whether to use `attacut-sc` or `attacut-c`. +atta = Tokenizer(model="attacut-sc") +words = atta.tokenize(txt) +``` + +## Benchmark Results + +Belows are brief summaries. More details can be found on [our benchmarking page](https://pythainlp.github.io/attacut/benchmark.html). + + +### Tokenization Quality + + +### Speed + + + +## Retraining on Custom Dataset +Please refer to [our retraining page](https://pythainlp.github.io/attacut/) + +## Related Resources +- [Tokenization Visualization][tovis] +- [Thai Tokenizer Dockers][docker] + +## Acknowledgements +This repository was initially done by [Pattarawat Chormai][pat], while interning at [Dr. Attapol Thamrongrattanarit's NLP Lab][ate], Chulalongkorn University, Bangkok, Thailand. +Many people have involed in this project. Complete list of names can be found on [Acknowledgement](https://pythainlp.github.io/attacut/acknowledgement.html). + + +[pat]: http://pat.chormai.org +[ate]: https://attapol.github.io/lab.html +[noom]: https://github.com/Ekkalak-T +[can]: https://github.com/c4n +[ake]: https://github.com/ekapolc +[tovis]: https://pythainlp.github.io/tokenization-benchmark-visualization/ +[docker]: https://github.com/PyThaiNLP/docker-thai-tokenizers + + + + +%prep +%autosetup -n attacut-1.0.6 + +%build +%py3_build + +%install +%py3_install +install -d -m755 %{buildroot}/%{_pkgdocdir} +if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi +if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi +if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi +if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi +pushd %{buildroot} +if [ -d usr/lib ]; then + find usr/lib -type f -printf "/%h/%f\n" >> filelist.lst +fi +if [ -d usr/lib64 ]; then + find usr/lib64 -type f -printf "/%h/%f\n" >> filelist.lst +fi +if [ -d usr/bin ]; then + find usr/bin -type f -printf "/%h/%f\n" >> filelist.lst +fi +if [ -d usr/sbin ]; then + find usr/sbin -type f -printf "/%h/%f\n" >> filelist.lst +fi +touch doclist.lst +if [ -d usr/share/man ]; then + find usr/share/man -type f -printf "/%h/%f.gz\n" >> doclist.lst +fi +popd +mv %{buildroot}/filelist.lst . +mv %{buildroot}/doclist.lst . + +%files -n python3-attacut -f filelist.lst +%dir %{python3_sitelib}/* + +%files help -f doclist.lst +%{_docdir}/* + +%changelog +* Wed May 10 2023 Python_Bot <Python_Bot@openeuler.org> - 1.0.6-1 +- Package Spec generated @@ -0,0 +1 @@ +0d32368ece14466da30601e9181e996f attacut-1.0.6.tar.gz |