
diff options
| -rw-r--r-- | .gitignore | 1 | ||||
| -rw-r--r-- | python-langhuan.spec | 483 | ||||
| -rw-r--r-- | sources | 1 |
3 files changed, 485 insertions, 0 deletions
@@ -0,0 +1 @@ +/langhuan-0.1.12.tar.gz diff --git a/python-langhuan.spec b/python-langhuan.spec new file mode 100644 index 0000000..e49528b --- /dev/null +++ b/python-langhuan.spec @@ -0,0 +1,483 @@ +%global _empty_manifest_terminate_build 0 +Name: python-langhuan +Version: 0.1.12 +Release: 1 +Summary: Language Human Annotation +License: Apache Software License 2.0 +URL: https://github.com/raynardj/langhuan +Source0: https://mirrors.aliyun.com/pypi/web/packages/e9/ab/5bb42a04d5bb5d16d089fb90f3a621147c03c65f393528ca9c0fb1653e05/langhuan-0.1.12.tar.gz +BuildArch: noarch + + +%description +# LangHuAn +> **Lang**uage **Hu**man **An**notations, a frontend for tagging AI project labels, drived by pandas dataframe data. + +> From Chinese word **琅嬛[langhuan]** (Legendary realm where god curates books) + +Here's a [5 minutes youtube video](https://www.youtube.com/watch?v=Nwh6roiX_9I) explaining how langhuan works + +[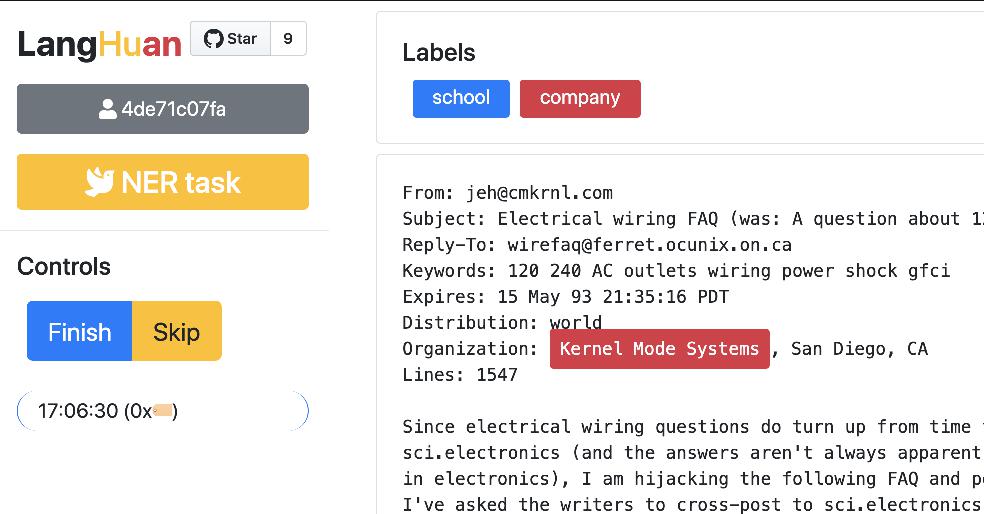](https://www.youtube.com/watch?v=Nwh6roiX_9I) + +## Installation +```shell +pip install langhuan +``` + +## Minimun configuration walk through +> langhuan start a flask application from **pandas dataframe** 🐼 ! + +### Simplest configuration for **NER** task 🚀 + +```python +from langhuan import NERTask + +app = NERTask.from_df( + df, text_col="description", + options=["institution", "company", "name"]) +app.run("0.0.0.0", port=5000) +``` + +### Simplest configuration for **Classify** task 🚀 +```python +from langhuan import ClassifyTask + +app = ClassifyTask.from_df( + df, text_col="comment", + options=["positive", "negative", "unbiased", "not sure"]) +app.run("0.0.0.0", port=5000) +``` +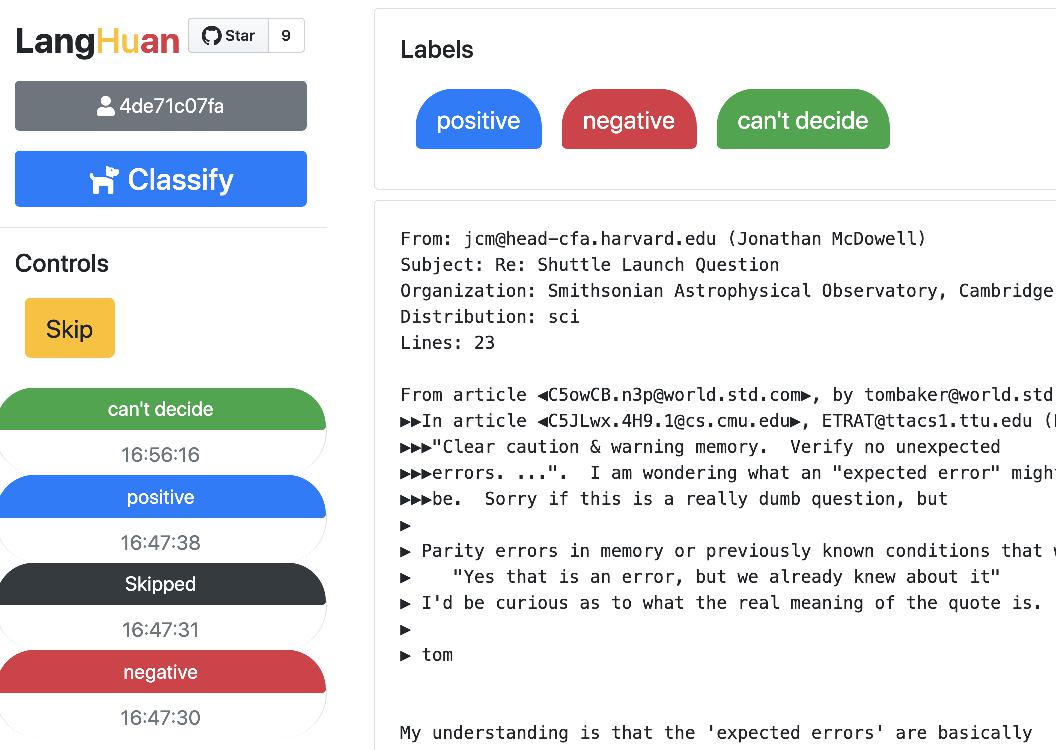 + +## Frontend +> You can visit following pages for this app. + +### Tagging +```http://[ip]:[port]/``` is for our hard working taggers to visit. + +### Admin +```http://[ip]:[port]/admin``` is a page where you can 👮🏽♂️: +* See the progress of each user. +* Force save the progress, (or it will only save according to ```save_frequency```, default 42 entries) +* Download the tagged entries + +## Advanced settings +#### Validation +You can set minimun verification number: ```cross_verify_num```, aka, how each entry will be validated, default is 1 + +If you set ```cross_verify_num``` to 2, and you have 5 taggers, each entry will be seen by 2 taggers + +```python +app = ClassifyTask.from_df( + df, text_col="comment", + options=["positive", "negative", "unbiased", "not sure"], + cross_verify_num=2,) +``` + +#### Preset the tagging +You can set a column in dataframe, eg. called ```guessed_tags```, to preset the tagging result. + +Each cell can contain the format of tagging result, eg. +```json +{"tags":[ + {"text": "Genomicare Bio Tech", "offset":32, "label":"company"}, + {"text": "East China University of Politic Science & Law", "offset":96, "label":"company"}, + ]} +``` + +Then you can run the app with preset tag column +```python +app = NERTask.from_df( + df, text_col="description", + options=["institution", "company", "name"], + preset_tag_col="guessed_tags") +app.run("0.0.0.0", port=5000) +``` + +#### Order strategy +The order of which text got tagged first is according to order_strategy. + +Default is set to ```"forward_match"```, you can try ```pincer``` or ```trident``` +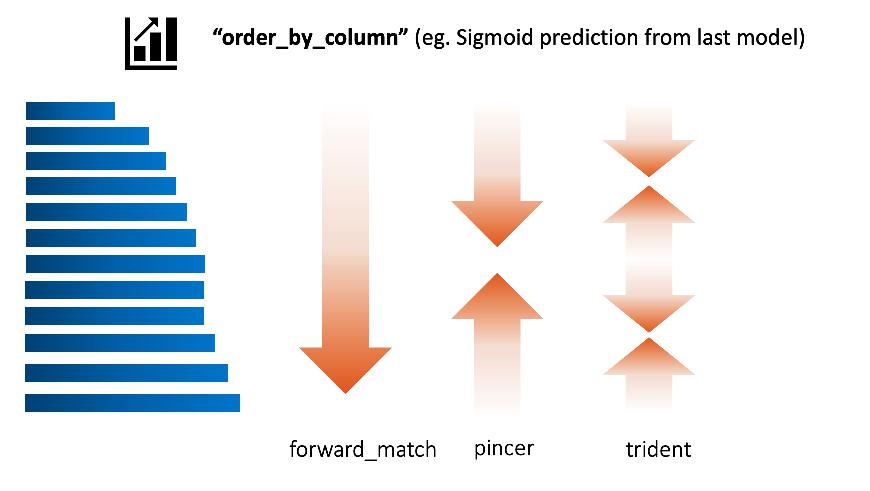 + +Assume the order_by_column is set to the prediction of last batch of deep learning model: +- trident means the taggers tag the most confident positive, most confident negative, most unsure ones first. + +#### Load History +If your service stopped, you can recover the progress from cache. + +Previous cache will be at ```$HOME/.cache/langhuan/{task_name}``` + +You can change the save_frequency to suit your task, default is 42 entries. + +```python +app = NERTask.from_df( + df, text_col="description", + options=["institution", "company", "name"], + save_frequency=128, + load_history=True, + task_name="task_NER_210123_110327" + ) +``` + +#### Admin Control +> This application assumes internal use within organization, hence the mininum security. If you set admin_control, all the admin related page will require ```adminkey```, the key will appear in the console prompt + +```python +app = NERTask.from_df( + df, text_col="description", + options=["institution", "company", "name"], + admin_control=True, + ) +``` + +#### From downloaded data => pytorch dataset +> For downloaded NER data tags, you can create a dataloader with the json file automatically: +* [pytorch + huggingface tokenizer](https://raynardj.github.io/langhuan/docs/loader) +* tensorflow + huggingface tokenizer, development pending + +#### Gunicorn support +This is a **light weight** solution. When move things to gunicorn, multithreads is acceptable, but multiworkers will cause chaos. + +```shell +gunicorn --workers=1 --threads=5 app:app +``` + +## Compatibility 💍 +Well, this library hasn't been tested vigorously against many browsers with many versions, so far +* compatible with chrome, firefox, safari if version not too old. + + + +%package -n python3-langhuan +Summary: Language Human Annotation +Provides: python-langhuan +BuildRequires: python3-devel +BuildRequires: python3-setuptools +BuildRequires: python3-pip +%description -n python3-langhuan +# LangHuAn +> **Lang**uage **Hu**man **An**notations, a frontend for tagging AI project labels, drived by pandas dataframe data. + +> From Chinese word **琅嬛[langhuan]** (Legendary realm where god curates books) + +Here's a [5 minutes youtube video](https://www.youtube.com/watch?v=Nwh6roiX_9I) explaining how langhuan works + +[](https://www.youtube.com/watch?v=Nwh6roiX_9I) + +## Installation +```shell +pip install langhuan +``` + +## Minimun configuration walk through +> langhuan start a flask application from **pandas dataframe** 🐼 ! + +### Simplest configuration for **NER** task 🚀 + +```python +from langhuan import NERTask + +app = NERTask.from_df( + df, text_col="description", + options=["institution", "company", "name"]) +app.run("0.0.0.0", port=5000) +``` + +### Simplest configuration for **Classify** task 🚀 +```python +from langhuan import ClassifyTask + +app = ClassifyTask.from_df( + df, text_col="comment", + options=["positive", "negative", "unbiased", "not sure"]) +app.run("0.0.0.0", port=5000) +``` + + +## Frontend +> You can visit following pages for this app. + +### Tagging +```http://[ip]:[port]/``` is for our hard working taggers to visit. + +### Admin +```http://[ip]:[port]/admin``` is a page where you can 👮🏽♂️: +* See the progress of each user. +* Force save the progress, (or it will only save according to ```save_frequency```, default 42 entries) +* Download the tagged entries + +## Advanced settings +#### Validation +You can set minimun verification number: ```cross_verify_num```, aka, how each entry will be validated, default is 1 + +If you set ```cross_verify_num``` to 2, and you have 5 taggers, each entry will be seen by 2 taggers + +```python +app = ClassifyTask.from_df( + df, text_col="comment", + options=["positive", "negative", "unbiased", "not sure"], + cross_verify_num=2,) +``` + +#### Preset the tagging +You can set a column in dataframe, eg. called ```guessed_tags```, to preset the tagging result. + +Each cell can contain the format of tagging result, eg. +```json +{"tags":[ + {"text": "Genomicare Bio Tech", "offset":32, "label":"company"}, + {"text": "East China University of Politic Science & Law", "offset":96, "label":"company"}, + ]} +``` + +Then you can run the app with preset tag column +```python +app = NERTask.from_df( + df, text_col="description", + options=["institution", "company", "name"], + preset_tag_col="guessed_tags") +app.run("0.0.0.0", port=5000) +``` + +#### Order strategy +The order of which text got tagged first is according to order_strategy. + +Default is set to ```"forward_match"```, you can try ```pincer``` or ```trident``` + + +Assume the order_by_column is set to the prediction of last batch of deep learning model: +- trident means the taggers tag the most confident positive, most confident negative, most unsure ones first. + +#### Load History +If your service stopped, you can recover the progress from cache. + +Previous cache will be at ```$HOME/.cache/langhuan/{task_name}``` + +You can change the save_frequency to suit your task, default is 42 entries. + +```python +app = NERTask.from_df( + df, text_col="description", + options=["institution", "company", "name"], + save_frequency=128, + load_history=True, + task_name="task_NER_210123_110327" + ) +``` + +#### Admin Control +> This application assumes internal use within organization, hence the mininum security. If you set admin_control, all the admin related page will require ```adminkey```, the key will appear in the console prompt + +```python +app = NERTask.from_df( + df, text_col="description", + options=["institution", "company", "name"], + admin_control=True, + ) +``` + +#### From downloaded data => pytorch dataset +> For downloaded NER data tags, you can create a dataloader with the json file automatically: +* [pytorch + huggingface tokenizer](https://raynardj.github.io/langhuan/docs/loader) +* tensorflow + huggingface tokenizer, development pending + +#### Gunicorn support +This is a **light weight** solution. When move things to gunicorn, multithreads is acceptable, but multiworkers will cause chaos. + +```shell +gunicorn --workers=1 --threads=5 app:app +``` + +## Compatibility 💍 +Well, this library hasn't been tested vigorously against many browsers with many versions, so far +* compatible with chrome, firefox, safari if version not too old. + + + +%package help +Summary: Development documents and examples for langhuan +Provides: python3-langhuan-doc +%description help +# LangHuAn +> **Lang**uage **Hu**man **An**notations, a frontend for tagging AI project labels, drived by pandas dataframe data. + +> From Chinese word **琅嬛[langhuan]** (Legendary realm where god curates books) + +Here's a [5 minutes youtube video](https://www.youtube.com/watch?v=Nwh6roiX_9I) explaining how langhuan works + +[](https://www.youtube.com/watch?v=Nwh6roiX_9I) + +## Installation +```shell +pip install langhuan +``` + +## Minimun configuration walk through +> langhuan start a flask application from **pandas dataframe** 🐼 ! + +### Simplest configuration for **NER** task 🚀 + +```python +from langhuan import NERTask + +app = NERTask.from_df( + df, text_col="description", + options=["institution", "company", "name"]) +app.run("0.0.0.0", port=5000) +``` + +### Simplest configuration for **Classify** task 🚀 +```python +from langhuan import ClassifyTask + +app = ClassifyTask.from_df( + df, text_col="comment", + options=["positive", "negative", "unbiased", "not sure"]) +app.run("0.0.0.0", port=5000) +``` + + +## Frontend +> You can visit following pages for this app. + +### Tagging +```http://[ip]:[port]/``` is for our hard working taggers to visit. + +### Admin +```http://[ip]:[port]/admin``` is a page where you can 👮🏽♂️: +* See the progress of each user. +* Force save the progress, (or it will only save according to ```save_frequency```, default 42 entries) +* Download the tagged entries + +## Advanced settings +#### Validation +You can set minimun verification number: ```cross_verify_num```, aka, how each entry will be validated, default is 1 + +If you set ```cross_verify_num``` to 2, and you have 5 taggers, each entry will be seen by 2 taggers + +```python +app = ClassifyTask.from_df( + df, text_col="comment", + options=["positive", "negative", "unbiased", "not sure"], + cross_verify_num=2,) +``` + +#### Preset the tagging +You can set a column in dataframe, eg. called ```guessed_tags```, to preset the tagging result. + +Each cell can contain the format of tagging result, eg. +```json +{"tags":[ + {"text": "Genomicare Bio Tech", "offset":32, "label":"company"}, + {"text": "East China University of Politic Science & Law", "offset":96, "label":"company"}, + ]} +``` + +Then you can run the app with preset tag column +```python +app = NERTask.from_df( + df, text_col="description", + options=["institution", "company", "name"], + preset_tag_col="guessed_tags") +app.run("0.0.0.0", port=5000) +``` + +#### Order strategy +The order of which text got tagged first is according to order_strategy. + +Default is set to ```"forward_match"```, you can try ```pincer``` or ```trident``` + + +Assume the order_by_column is set to the prediction of last batch of deep learning model: +- trident means the taggers tag the most confident positive, most confident negative, most unsure ones first. + +#### Load History +If your service stopped, you can recover the progress from cache. + +Previous cache will be at ```$HOME/.cache/langhuan/{task_name}``` + +You can change the save_frequency to suit your task, default is 42 entries. + +```python +app = NERTask.from_df( + df, text_col="description", + options=["institution", "company", "name"], + save_frequency=128, + load_history=True, + task_name="task_NER_210123_110327" + ) +``` + +#### Admin Control +> This application assumes internal use within organization, hence the mininum security. If you set admin_control, all the admin related page will require ```adminkey```, the key will appear in the console prompt + +```python +app = NERTask.from_df( + df, text_col="description", + options=["institution", "company", "name"], + admin_control=True, + ) +``` + +#### From downloaded data => pytorch dataset +> For downloaded NER data tags, you can create a dataloader with the json file automatically: +* [pytorch + huggingface tokenizer](https://raynardj.github.io/langhuan/docs/loader) +* tensorflow + huggingface tokenizer, development pending + +#### Gunicorn support +This is a **light weight** solution. When move things to gunicorn, multithreads is acceptable, but multiworkers will cause chaos. + +```shell +gunicorn --workers=1 --threads=5 app:app +``` + +## Compatibility 💍 +Well, this library hasn't been tested vigorously against many browsers with many versions, so far +* compatible with chrome, firefox, safari if version not too old. + + + +%prep +%autosetup -n langhuan-0.1.12 + +%build +%py3_build + +%install +%py3_install +install -d -m755 %{buildroot}/%{_pkgdocdir} +if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi +if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi +if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi +if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi +pushd %{buildroot} +if [ -d usr/lib ]; then + find usr/lib -type f -printf "\"/%h/%f\"\n" >> filelist.lst +fi +if [ -d usr/lib64 ]; then + find usr/lib64 -type f -printf "\"/%h/%f\"\n" >> filelist.lst +fi +if [ -d usr/bin ]; then + find usr/bin -type f -printf "\"/%h/%f\"\n" >> filelist.lst +fi +if [ -d usr/sbin ]; then + find usr/sbin -type f -printf "\"/%h/%f\"\n" >> filelist.lst +fi +touch doclist.lst +if [ -d usr/share/man ]; then + find usr/share/man -type f -printf "\"/%h/%f.gz\"\n" >> doclist.lst +fi +popd +mv %{buildroot}/filelist.lst . +mv %{buildroot}/doclist.lst . + +%files -n python3-langhuan -f filelist.lst +%dir %{python3_sitelib}/* + +%files help -f doclist.lst +%{_docdir}/* + +%changelog +* Tue Jun 20 2023 Python_Bot <Python_Bot@openeuler.org> - 0.1.12-1 +- Package Spec generated @@ -0,0 +1 @@ +8d71de3baa34fbd6c5351e9e65acc3e6 langhuan-0.1.12.tar.gz |