1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
|
%global _empty_manifest_terminate_build 0
Name: python-madgrad
Version: 1.3
Release: 1
Summary: A general purpose PyTorch Optimizer
License: MIT License
URL: https://github.com/facebookresearch/madgrad
Source0: https://mirrors.nju.edu.cn/pypi/web/packages/18/ea/95435c2c4d55f51375468dfd1721d88a73f93991b765c5a04366d36472f2/madgrad-1.3.tar.gz
BuildArch: noarch
%description
# MADGRAD Optimization Method
A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization
Documentation availiable at https://madgrad.readthedocs.io/en/latest/.
``` pip install madgrad ```
Try it out! A best-of-both-worlds optimizer with the generalization performance of SGD and at least as fast convergence as that of Adam, often faster. A drop-in torch.optim implementation `madgrad.MADGRAD` is provided, as well as a FairSeq wrapped instance. For FairSeq, just import madgrad anywhere in your project files and use the `--optimizer madgrad` command line option, together with `--weight-decay`, `--momentum`, and optionally `--madgrad_eps`.
The madgrad.py file containing the optimizer can be directly dropped into any PyTorch project if you don't want to install via pip. If you are using fairseq, you need the acompanying fairseq_madgrad.py file as well.
## Things to note:
- You may need to use a lower weight decay than you are accustomed to. Often 0.
- You should do a full learning rate sweep as the optimal learning rate will be different from SGD or Adam. Best LR values we found were 2.5e-4 for 152 layer PreActResNet on CIFAR10, 0.001 for ResNet-50 on ImageNet, 0.025 for IWSLT14 using `transformer_iwslt_de_en` and 0.005 for RoBERTa training on BookWiki using `BERT_BASE`. On NLP models gradient clipping also helped.
# Mirror MADGRAD
The mirror descent version of MADGRAD is also included as `madgrad.MirrorMADGRAD`. This version works extremely well, even better than MADGRAD, on large-scale transformer training. This version is recommended for any problem where the datasets are big enough that generalization gap is not an issue.
As the mirror descent version does not implicitly regularize, you can usually use weight
decay values that work well with other optimizers.
# Tech Report
[Adaptivity without Compromise: A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization](https://arxiv.org/abs/2101.11075)
We introduce MADGRAD, a novel optimization method in the family of AdaGrad adaptive gradient methods. MADGRAD shows excellent performance on deep learning optimization problems from multiple fields, including classification and image-to-image tasks in vision, and recurrent and bidirectionally-masked models in natural language processing. For each of these tasks, MADGRAD matches or outperforms both SGD and ADAM in test set performance, even on problems for which adaptive methods normally perform poorly.
```BibTeX
@misc{defazio2021adaptivity,
title={Adaptivity without Compromise: A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization},
author={Aaron Defazio and Samy Jelassi},
year={2021},
eprint={2101.11075},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
# Results

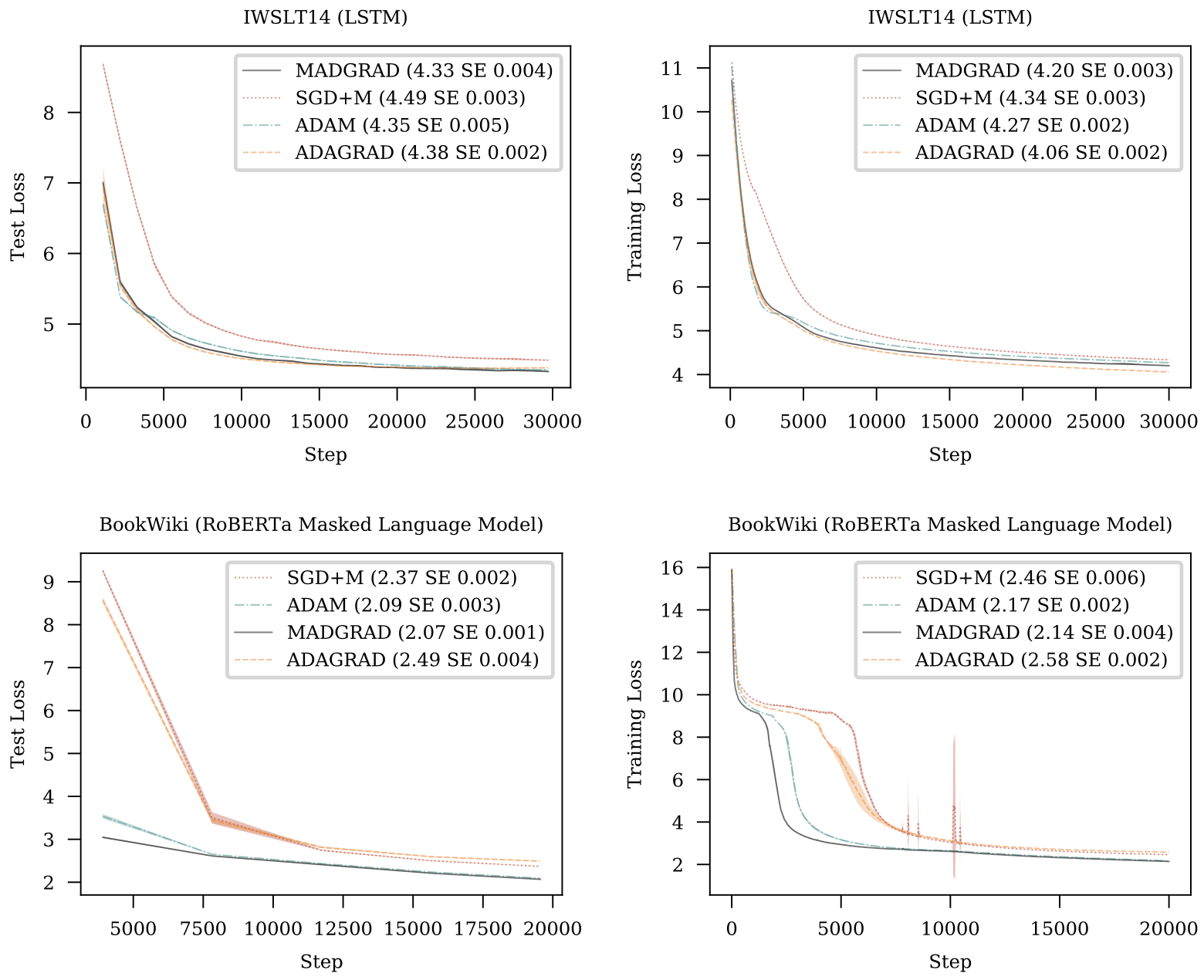
# License
MADGRAD is licensed under the [MIT License](LICENSE).
%package -n python3-madgrad
Summary: A general purpose PyTorch Optimizer
Provides: python-madgrad
BuildRequires: python3-devel
BuildRequires: python3-setuptools
BuildRequires: python3-pip
%description -n python3-madgrad
# MADGRAD Optimization Method
A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization
Documentation availiable at https://madgrad.readthedocs.io/en/latest/.
``` pip install madgrad ```
Try it out! A best-of-both-worlds optimizer with the generalization performance of SGD and at least as fast convergence as that of Adam, often faster. A drop-in torch.optim implementation `madgrad.MADGRAD` is provided, as well as a FairSeq wrapped instance. For FairSeq, just import madgrad anywhere in your project files and use the `--optimizer madgrad` command line option, together with `--weight-decay`, `--momentum`, and optionally `--madgrad_eps`.
The madgrad.py file containing the optimizer can be directly dropped into any PyTorch project if you don't want to install via pip. If you are using fairseq, you need the acompanying fairseq_madgrad.py file as well.
## Things to note:
- You may need to use a lower weight decay than you are accustomed to. Often 0.
- You should do a full learning rate sweep as the optimal learning rate will be different from SGD or Adam. Best LR values we found were 2.5e-4 for 152 layer PreActResNet on CIFAR10, 0.001 for ResNet-50 on ImageNet, 0.025 for IWSLT14 using `transformer_iwslt_de_en` and 0.005 for RoBERTa training on BookWiki using `BERT_BASE`. On NLP models gradient clipping also helped.
# Mirror MADGRAD
The mirror descent version of MADGRAD is also included as `madgrad.MirrorMADGRAD`. This version works extremely well, even better than MADGRAD, on large-scale transformer training. This version is recommended for any problem where the datasets are big enough that generalization gap is not an issue.
As the mirror descent version does not implicitly regularize, you can usually use weight
decay values that work well with other optimizers.
# Tech Report
[Adaptivity without Compromise: A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization](https://arxiv.org/abs/2101.11075)
We introduce MADGRAD, a novel optimization method in the family of AdaGrad adaptive gradient methods. MADGRAD shows excellent performance on deep learning optimization problems from multiple fields, including classification and image-to-image tasks in vision, and recurrent and bidirectionally-masked models in natural language processing. For each of these tasks, MADGRAD matches or outperforms both SGD and ADAM in test set performance, even on problems for which adaptive methods normally perform poorly.
```BibTeX
@misc{defazio2021adaptivity,
title={Adaptivity without Compromise: A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization},
author={Aaron Defazio and Samy Jelassi},
year={2021},
eprint={2101.11075},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
# Results


# License
MADGRAD is licensed under the [MIT License](LICENSE).
%package help
Summary: Development documents and examples for madgrad
Provides: python3-madgrad-doc
%description help
# MADGRAD Optimization Method
A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization
Documentation availiable at https://madgrad.readthedocs.io/en/latest/.
``` pip install madgrad ```
Try it out! A best-of-both-worlds optimizer with the generalization performance of SGD and at least as fast convergence as that of Adam, often faster. A drop-in torch.optim implementation `madgrad.MADGRAD` is provided, as well as a FairSeq wrapped instance. For FairSeq, just import madgrad anywhere in your project files and use the `--optimizer madgrad` command line option, together with `--weight-decay`, `--momentum`, and optionally `--madgrad_eps`.
The madgrad.py file containing the optimizer can be directly dropped into any PyTorch project if you don't want to install via pip. If you are using fairseq, you need the acompanying fairseq_madgrad.py file as well.
## Things to note:
- You may need to use a lower weight decay than you are accustomed to. Often 0.
- You should do a full learning rate sweep as the optimal learning rate will be different from SGD or Adam. Best LR values we found were 2.5e-4 for 152 layer PreActResNet on CIFAR10, 0.001 for ResNet-50 on ImageNet, 0.025 for IWSLT14 using `transformer_iwslt_de_en` and 0.005 for RoBERTa training on BookWiki using `BERT_BASE`. On NLP models gradient clipping also helped.
# Mirror MADGRAD
The mirror descent version of MADGRAD is also included as `madgrad.MirrorMADGRAD`. This version works extremely well, even better than MADGRAD, on large-scale transformer training. This version is recommended for any problem where the datasets are big enough that generalization gap is not an issue.
As the mirror descent version does not implicitly regularize, you can usually use weight
decay values that work well with other optimizers.
# Tech Report
[Adaptivity without Compromise: A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization](https://arxiv.org/abs/2101.11075)
We introduce MADGRAD, a novel optimization method in the family of AdaGrad adaptive gradient methods. MADGRAD shows excellent performance on deep learning optimization problems from multiple fields, including classification and image-to-image tasks in vision, and recurrent and bidirectionally-masked models in natural language processing. For each of these tasks, MADGRAD matches or outperforms both SGD and ADAM in test set performance, even on problems for which adaptive methods normally perform poorly.
```BibTeX
@misc{defazio2021adaptivity,
title={Adaptivity without Compromise: A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization},
author={Aaron Defazio and Samy Jelassi},
year={2021},
eprint={2101.11075},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
# Results


# License
MADGRAD is licensed under the [MIT License](LICENSE).
%prep
%autosetup -n madgrad-1.3
%build
%py3_build
%install
%py3_install
install -d -m755 %{buildroot}/%{_pkgdocdir}
if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi
if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi
if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi
if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi
pushd %{buildroot}
if [ -d usr/lib ]; then
find usr/lib -type f -printf "/%h/%f\n" >> filelist.lst
fi
if [ -d usr/lib64 ]; then
find usr/lib64 -type f -printf "/%h/%f\n" >> filelist.lst
fi
if [ -d usr/bin ]; then
find usr/bin -type f -printf "/%h/%f\n" >> filelist.lst
fi
if [ -d usr/sbin ]; then
find usr/sbin -type f -printf "/%h/%f\n" >> filelist.lst
fi
touch doclist.lst
if [ -d usr/share/man ]; then
find usr/share/man -type f -printf "/%h/%f.gz\n" >> doclist.lst
fi
popd
mv %{buildroot}/filelist.lst .
mv %{buildroot}/doclist.lst .
%files -n python3-madgrad -f filelist.lst
%dir %{python3_sitelib}/*
%files help -f doclist.lst
%{_docdir}/*
%changelog
* Fri May 05 2023 Python_Bot <Python_Bot@openeuler.org> - 1.3-1
- Package Spec generated
|
