
diff options
| author | CoprDistGit <infra@openeuler.org> | 2023-05-05 07:49:58 +0000 |
|---|---|---|
| committer | CoprDistGit <infra@openeuler.org> | 2023-05-05 07:49:58 +0000 |
| commit | 5dc8a42d1d672ea7f02ad6488815724b10fc1c77 (patch) | |
| tree | 113a7f5613f262f2833235303165962bc2054685 | |
| parent | f318233c0429a8539eaf0ff207ffc02720cd9e4b (diff) | |
automatic import of python-pdf2docxopeneuler20.03
| -rw-r--r-- | .gitignore | 1 | ||||
| -rw-r--r-- | python-pdf2docx.spec | 288 | ||||
| -rw-r--r-- | sources | 1 |
3 files changed, 290 insertions, 0 deletions
@@ -0,0 +1 @@ +/pdf2docx-0.5.6.tar.gz diff --git a/python-pdf2docx.spec b/python-pdf2docx.spec new file mode 100644 index 0000000..9f70f48 --- /dev/null +++ b/python-pdf2docx.spec @@ -0,0 +1,288 @@ +%global _empty_manifest_terminate_build 0 +Name: python-pdf2docx +Version: 0.5.6 +Release: 1 +Summary: Open source Python library converting pdf to docx. +License: GPL v3 +URL: https://github.com/dothinking/pdf2docx +Source0: https://mirrors.nju.edu.cn/pypi/web/packages/05/8f/e50f748e72b812b6ff1af534f2c618c79ad58f0e50d09369665be36086a7/pdf2docx-0.5.6.tar.gz +BuildArch: noarch + +Requires: python3-PyMuPDF +Requires: python3-docx +Requires: python3-fonttools +Requires: python3-numpy +Requires: python3-opencv-python +Requires: python3-fire + +%description +English | [中文](README_CN.md) + +# pdf2docx + + +[](https://codecov.io/gh/dothinking/pdf2docx) +[](https://pypi.python.org/pypi/pdf2docx/) + + + +- Extract data from PDF with `PyMuPDF`, e.g. text, images and drawings +- Parse layout with rule, e.g. sections, paragraphs, images and tables +- Generate docx with `python-docx` + +## Features + +- Parse and re-create page layout + - page margin + - section and column (1 or 2 columns only) + - page header and footer [TODO] + +- Parse and re-create paragraph + - OCR text [TODO] + - text in horizontal/vertical direction: from left to right, from bottom to top + - font style, e.g. font name, size, weight, italic and color + - text format, e.g. highlight, underline, strike-through + - list style [TODO] + - external hyper link + - paragraph horizontal alignment (left/right/center/justify) and vertical spacing + +- Parse and re-create image + - in-line image + - image in Gray/RGB/CMYK mode + - transparent image + - floating image, i.e. picture behind text + +- Parse and re-create table + - border style, e.g. width, color + - shading style, i.e. background color + - merged cells + - vertical direction cell + - table with partly hidden borders + - nested tables + +- Parsing pages with multi-processing + +*It can also be used as a tool to extract table contents since both table content and format/style is parsed.* + +## Limitations + +- Text-based PDF file +- Left to right language +- Normal reading direction, no word transformation / rotation +- Rule-based method can't 100% convert the PDF layout + + +## Documentation + +- [Installation](https://dothinking.github.io/pdf2docx/installation.html) +- [Quickstart](https://dothinking.github.io/pdf2docx/quickstart.html) + - [Convert PDF](https://dothinking.github.io/pdf2docx/quickstart.convert.html) + - [Extract table](https://dothinking.github.io/pdf2docx/quickstart.table.html) + - [Command Line Interface](https://dothinking.github.io/pdf2docx/quickstart.cli.html) + - [Graphic User Interface](https://dothinking.github.io/pdf2docx/quickstart.gui.html) +- [Technical Documentation (In Chinese)](https://dothinking.github.io/pdf2docx/techdoc.html) +- [API Documentation](https://dothinking.github.io/pdf2docx/modules.html) + +## Sample + +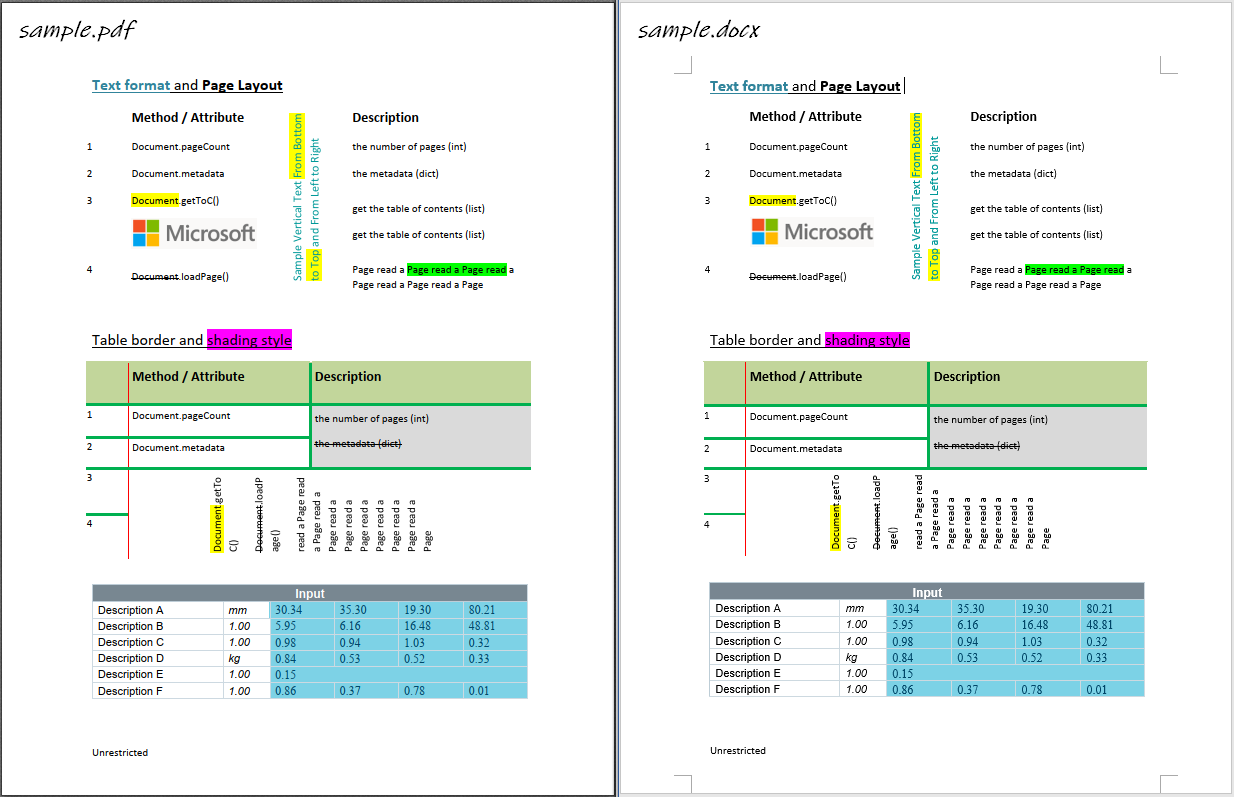 + + +%package -n python3-pdf2docx +Summary: Open source Python library converting pdf to docx. +Provides: python-pdf2docx +BuildRequires: python3-devel +BuildRequires: python3-setuptools +BuildRequires: python3-pip +%description -n python3-pdf2docx +English | [中文](README_CN.md) + +# pdf2docx + + +[](https://codecov.io/gh/dothinking/pdf2docx) +[](https://pypi.python.org/pypi/pdf2docx/) + + + +- Extract data from PDF with `PyMuPDF`, e.g. text, images and drawings +- Parse layout with rule, e.g. sections, paragraphs, images and tables +- Generate docx with `python-docx` + +## Features + +- Parse and re-create page layout + - page margin + - section and column (1 or 2 columns only) + - page header and footer [TODO] + +- Parse and re-create paragraph + - OCR text [TODO] + - text in horizontal/vertical direction: from left to right, from bottom to top + - font style, e.g. font name, size, weight, italic and color + - text format, e.g. highlight, underline, strike-through + - list style [TODO] + - external hyper link + - paragraph horizontal alignment (left/right/center/justify) and vertical spacing + +- Parse and re-create image + - in-line image + - image in Gray/RGB/CMYK mode + - transparent image + - floating image, i.e. picture behind text + +- Parse and re-create table + - border style, e.g. width, color + - shading style, i.e. background color + - merged cells + - vertical direction cell + - table with partly hidden borders + - nested tables + +- Parsing pages with multi-processing + +*It can also be used as a tool to extract table contents since both table content and format/style is parsed.* + +## Limitations + +- Text-based PDF file +- Left to right language +- Normal reading direction, no word transformation / rotation +- Rule-based method can't 100% convert the PDF layout + + +## Documentation + +- [Installation](https://dothinking.github.io/pdf2docx/installation.html) +- [Quickstart](https://dothinking.github.io/pdf2docx/quickstart.html) + - [Convert PDF](https://dothinking.github.io/pdf2docx/quickstart.convert.html) + - [Extract table](https://dothinking.github.io/pdf2docx/quickstart.table.html) + - [Command Line Interface](https://dothinking.github.io/pdf2docx/quickstart.cli.html) + - [Graphic User Interface](https://dothinking.github.io/pdf2docx/quickstart.gui.html) +- [Technical Documentation (In Chinese)](https://dothinking.github.io/pdf2docx/techdoc.html) +- [API Documentation](https://dothinking.github.io/pdf2docx/modules.html) + +## Sample + + + + +%package help +Summary: Development documents and examples for pdf2docx +Provides: python3-pdf2docx-doc +%description help +English | [中文](README_CN.md) + +# pdf2docx + + +[](https://codecov.io/gh/dothinking/pdf2docx) +[](https://pypi.python.org/pypi/pdf2docx/) + + + +- Extract data from PDF with `PyMuPDF`, e.g. text, images and drawings +- Parse layout with rule, e.g. sections, paragraphs, images and tables +- Generate docx with `python-docx` + +## Features + +- Parse and re-create page layout + - page margin + - section and column (1 or 2 columns only) + - page header and footer [TODO] + +- Parse and re-create paragraph + - OCR text [TODO] + - text in horizontal/vertical direction: from left to right, from bottom to top + - font style, e.g. font name, size, weight, italic and color + - text format, e.g. highlight, underline, strike-through + - list style [TODO] + - external hyper link + - paragraph horizontal alignment (left/right/center/justify) and vertical spacing + +- Parse and re-create image + - in-line image + - image in Gray/RGB/CMYK mode + - transparent image + - floating image, i.e. picture behind text + +- Parse and re-create table + - border style, e.g. width, color + - shading style, i.e. background color + - merged cells + - vertical direction cell + - table with partly hidden borders + - nested tables + +- Parsing pages with multi-processing + +*It can also be used as a tool to extract table contents since both table content and format/style is parsed.* + +## Limitations + +- Text-based PDF file +- Left to right language +- Normal reading direction, no word transformation / rotation +- Rule-based method can't 100% convert the PDF layout + + +## Documentation + +- [Installation](https://dothinking.github.io/pdf2docx/installation.html) +- [Quickstart](https://dothinking.github.io/pdf2docx/quickstart.html) + - [Convert PDF](https://dothinking.github.io/pdf2docx/quickstart.convert.html) + - [Extract table](https://dothinking.github.io/pdf2docx/quickstart.table.html) + - [Command Line Interface](https://dothinking.github.io/pdf2docx/quickstart.cli.html) + - [Graphic User Interface](https://dothinking.github.io/pdf2docx/quickstart.gui.html) +- [Technical Documentation (In Chinese)](https://dothinking.github.io/pdf2docx/techdoc.html) +- [API Documentation](https://dothinking.github.io/pdf2docx/modules.html) + +## Sample + + + + +%prep +%autosetup -n pdf2docx-0.5.6 + +%build +%py3_build + +%install +%py3_install +install -d -m755 %{buildroot}/%{_pkgdocdir} +if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi +if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi +if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi +if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi +pushd %{buildroot} +if [ -d usr/lib ]; then + find usr/lib -type f -printf "/%h/%f\n" >> filelist.lst +fi +if [ -d usr/lib64 ]; then + find usr/lib64 -type f -printf "/%h/%f\n" >> filelist.lst +fi +if [ -d usr/bin ]; then + find usr/bin -type f -printf "/%h/%f\n" >> filelist.lst +fi +if [ -d usr/sbin ]; then + find usr/sbin -type f -printf "/%h/%f\n" >> filelist.lst +fi +touch doclist.lst +if [ -d usr/share/man ]; then + find usr/share/man -type f -printf "/%h/%f.gz\n" >> doclist.lst +fi +popd +mv %{buildroot}/filelist.lst . +mv %{buildroot}/doclist.lst . + +%files -n python3-pdf2docx -f filelist.lst +%dir %{python3_sitelib}/* + +%files help -f doclist.lst +%{_docdir}/* + +%changelog +* Fri May 05 2023 Python_Bot <Python_Bot@openeuler.org> - 0.5.6-1 +- Package Spec generated @@ -0,0 +1 @@ +04e43f5cfa75449293a17902f3db9c16 pdf2docx-0.5.6.tar.gz |