1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
|
%global _empty_manifest_terminate_build 0
Name: python-pdf2docx
Version: 0.5.6
Release: 1
Summary: Open source Python library converting pdf to docx.
License: GPL v3
URL: https://github.com/dothinking/pdf2docx
Source0: https://mirrors.nju.edu.cn/pypi/web/packages/05/8f/e50f748e72b812b6ff1af534f2c618c79ad58f0e50d09369665be36086a7/pdf2docx-0.5.6.tar.gz
BuildArch: noarch
Requires: python3-PyMuPDF
Requires: python3-docx
Requires: python3-fonttools
Requires: python3-numpy
Requires: python3-opencv-python
Requires: python3-fire
%description
English | [中文](README_CN.md)
# pdf2docx

[](https://codecov.io/gh/dothinking/pdf2docx)
[](https://pypi.python.org/pypi/pdf2docx/)


- Extract data from PDF with `PyMuPDF`, e.g. text, images and drawings
- Parse layout with rule, e.g. sections, paragraphs, images and tables
- Generate docx with `python-docx`
## Features
- Parse and re-create page layout
- page margin
- section and column (1 or 2 columns only)
- page header and footer [TODO]
- Parse and re-create paragraph
- OCR text [TODO]
- text in horizontal/vertical direction: from left to right, from bottom to top
- font style, e.g. font name, size, weight, italic and color
- text format, e.g. highlight, underline, strike-through
- list style [TODO]
- external hyper link
- paragraph horizontal alignment (left/right/center/justify) and vertical spacing
- Parse and re-create image
- in-line image
- image in Gray/RGB/CMYK mode
- transparent image
- floating image, i.e. picture behind text
- Parse and re-create table
- border style, e.g. width, color
- shading style, i.e. background color
- merged cells
- vertical direction cell
- table with partly hidden borders
- nested tables
- Parsing pages with multi-processing
*It can also be used as a tool to extract table contents since both table content and format/style is parsed.*
## Limitations
- Text-based PDF file
- Left to right language
- Normal reading direction, no word transformation / rotation
- Rule-based method can't 100% convert the PDF layout
## Documentation
- [Installation](https://dothinking.github.io/pdf2docx/installation.html)
- [Quickstart](https://dothinking.github.io/pdf2docx/quickstart.html)
- [Convert PDF](https://dothinking.github.io/pdf2docx/quickstart.convert.html)
- [Extract table](https://dothinking.github.io/pdf2docx/quickstart.table.html)
- [Command Line Interface](https://dothinking.github.io/pdf2docx/quickstart.cli.html)
- [Graphic User Interface](https://dothinking.github.io/pdf2docx/quickstart.gui.html)
- [Technical Documentation (In Chinese)](https://dothinking.github.io/pdf2docx/techdoc.html)
- [API Documentation](https://dothinking.github.io/pdf2docx/modules.html)
## Sample
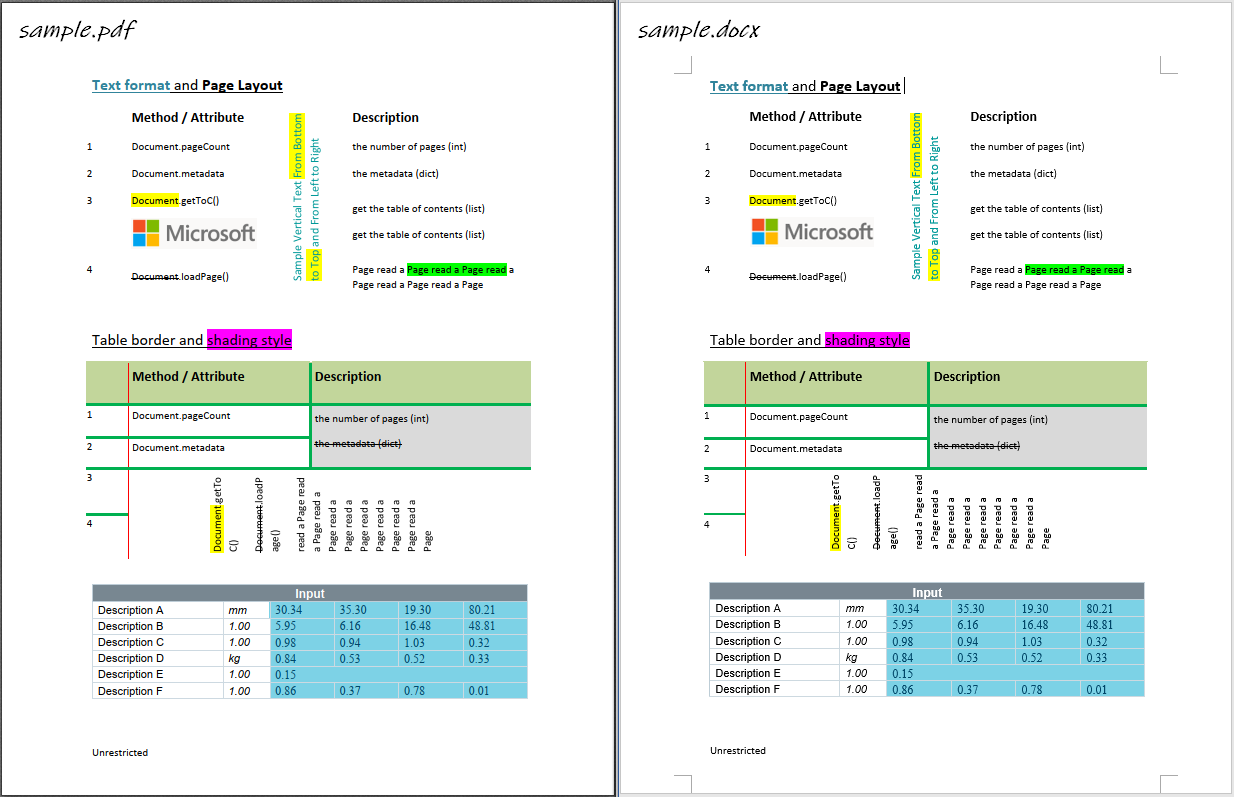
%package -n python3-pdf2docx
Summary: Open source Python library converting pdf to docx.
Provides: python-pdf2docx
BuildRequires: python3-devel
BuildRequires: python3-setuptools
BuildRequires: python3-pip
%description -n python3-pdf2docx
English | [中文](README_CN.md)
# pdf2docx

[](https://codecov.io/gh/dothinking/pdf2docx)
[](https://pypi.python.org/pypi/pdf2docx/)


- Extract data from PDF with `PyMuPDF`, e.g. text, images and drawings
- Parse layout with rule, e.g. sections, paragraphs, images and tables
- Generate docx with `python-docx`
## Features
- Parse and re-create page layout
- page margin
- section and column (1 or 2 columns only)
- page header and footer [TODO]
- Parse and re-create paragraph
- OCR text [TODO]
- text in horizontal/vertical direction: from left to right, from bottom to top
- font style, e.g. font name, size, weight, italic and color
- text format, e.g. highlight, underline, strike-through
- list style [TODO]
- external hyper link
- paragraph horizontal alignment (left/right/center/justify) and vertical spacing
- Parse and re-create image
- in-line image
- image in Gray/RGB/CMYK mode
- transparent image
- floating image, i.e. picture behind text
- Parse and re-create table
- border style, e.g. width, color
- shading style, i.e. background color
- merged cells
- vertical direction cell
- table with partly hidden borders
- nested tables
- Parsing pages with multi-processing
*It can also be used as a tool to extract table contents since both table content and format/style is parsed.*
## Limitations
- Text-based PDF file
- Left to right language
- Normal reading direction, no word transformation / rotation
- Rule-based method can't 100% convert the PDF layout
## Documentation
- [Installation](https://dothinking.github.io/pdf2docx/installation.html)
- [Quickstart](https://dothinking.github.io/pdf2docx/quickstart.html)
- [Convert PDF](https://dothinking.github.io/pdf2docx/quickstart.convert.html)
- [Extract table](https://dothinking.github.io/pdf2docx/quickstart.table.html)
- [Command Line Interface](https://dothinking.github.io/pdf2docx/quickstart.cli.html)
- [Graphic User Interface](https://dothinking.github.io/pdf2docx/quickstart.gui.html)
- [Technical Documentation (In Chinese)](https://dothinking.github.io/pdf2docx/techdoc.html)
- [API Documentation](https://dothinking.github.io/pdf2docx/modules.html)
## Sample

%package help
Summary: Development documents and examples for pdf2docx
Provides: python3-pdf2docx-doc
%description help
English | [中文](README_CN.md)
# pdf2docx

[](https://codecov.io/gh/dothinking/pdf2docx)
[](https://pypi.python.org/pypi/pdf2docx/)


- Extract data from PDF with `PyMuPDF`, e.g. text, images and drawings
- Parse layout with rule, e.g. sections, paragraphs, images and tables
- Generate docx with `python-docx`
## Features
- Parse and re-create page layout
- page margin
- section and column (1 or 2 columns only)
- page header and footer [TODO]
- Parse and re-create paragraph
- OCR text [TODO]
- text in horizontal/vertical direction: from left to right, from bottom to top
- font style, e.g. font name, size, weight, italic and color
- text format, e.g. highlight, underline, strike-through
- list style [TODO]
- external hyper link
- paragraph horizontal alignment (left/right/center/justify) and vertical spacing
- Parse and re-create image
- in-line image
- image in Gray/RGB/CMYK mode
- transparent image
- floating image, i.e. picture behind text
- Parse and re-create table
- border style, e.g. width, color
- shading style, i.e. background color
- merged cells
- vertical direction cell
- table with partly hidden borders
- nested tables
- Parsing pages with multi-processing
*It can also be used as a tool to extract table contents since both table content and format/style is parsed.*
## Limitations
- Text-based PDF file
- Left to right language
- Normal reading direction, no word transformation / rotation
- Rule-based method can't 100% convert the PDF layout
## Documentation
- [Installation](https://dothinking.github.io/pdf2docx/installation.html)
- [Quickstart](https://dothinking.github.io/pdf2docx/quickstart.html)
- [Convert PDF](https://dothinking.github.io/pdf2docx/quickstart.convert.html)
- [Extract table](https://dothinking.github.io/pdf2docx/quickstart.table.html)
- [Command Line Interface](https://dothinking.github.io/pdf2docx/quickstart.cli.html)
- [Graphic User Interface](https://dothinking.github.io/pdf2docx/quickstart.gui.html)
- [Technical Documentation (In Chinese)](https://dothinking.github.io/pdf2docx/techdoc.html)
- [API Documentation](https://dothinking.github.io/pdf2docx/modules.html)
## Sample

%prep
%autosetup -n pdf2docx-0.5.6
%build
%py3_build
%install
%py3_install
install -d -m755 %{buildroot}/%{_pkgdocdir}
if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi
if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi
if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi
if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi
pushd %{buildroot}
if [ -d usr/lib ]; then
find usr/lib -type f -printf "/%h/%f\n" >> filelist.lst
fi
if [ -d usr/lib64 ]; then
find usr/lib64 -type f -printf "/%h/%f\n" >> filelist.lst
fi
if [ -d usr/bin ]; then
find usr/bin -type f -printf "/%h/%f\n" >> filelist.lst
fi
if [ -d usr/sbin ]; then
find usr/sbin -type f -printf "/%h/%f\n" >> filelist.lst
fi
touch doclist.lst
if [ -d usr/share/man ]; then
find usr/share/man -type f -printf "/%h/%f.gz\n" >> doclist.lst
fi
popd
mv %{buildroot}/filelist.lst .
mv %{buildroot}/doclist.lst .
%files -n python3-pdf2docx -f filelist.lst
%dir %{python3_sitelib}/*
%files help -f doclist.lst
%{_docdir}/*
%changelog
* Fri May 05 2023 Python_Bot <Python_Bot@openeuler.org> - 0.5.6-1
- Package Spec generated
|
