1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
|
%global _empty_manifest_terminate_build 0
Name: python-timetomodel
Version: 0.7.3
Release: 1
Summary: Sane handling of time series data for forecast modelling - with production usage in mind.
License: MIT License
URL: https://github.com/seitabv/timetomodel
Source0: https://mirrors.aliyun.com/pypi/web/packages/9e/51/948aa9b4e8498924181eb3d17533eff0b43483d46ca9201b6c96d24b410c/timetomodel-0.7.3.tar.gz
BuildArch: noarch
Requires: python3-SQLAlchemy
Requires: python3-matplotlib
Requires: python3-numpy
Requires: python3-pandas
Requires: python3-dateutil
Requires: python3-pytz
Requires: python3-scikit-learn
Requires: python3-scipy
Requires: python3-statsmodels
%description
# timetomodel
Time series forecasting is a modern data science & engineering challenge.
We noticed that these two worlds, data science and engineering of time series forecasting, are not very compatible.
Often, work from the data scientist has to be re-implemented by engineers to be used in production.
`timetomodel` was created to change that. It describes the data treatment of a model, and also automates common data treatment tasks like building data for training and testing.
As a *data scientist*, experiment with a model in your notebook.
Load data from static files (e.g. CSV) and try out lags, regressors and so on.
Compare plots and mean square errors of the models you developed.
As an *engineer*, take over the model description and use it in your production code.
Often, this would entail not much more than changing the data source (e.g from CSV to a column in the database).
`timetomodel` is supposed to wrap around any fit/predict type model, e.g. from statsmodels or scikit-learn (some work needed here to ensure support).
## Features
Here are some features for both data scientists and engineers to enjoy:
* Describe how to load data for outcome and regressor variables. Load from Pandas objects, CSV files, Pandas pickles or databases via SQLAlchemy.
* Create train & test data, including lags.
* Timezone awareness support.
* Custom data transformations, after loading (e.g. to remove duplicate) or only for forecasting (e.g. to apply a BoxCox transformation).
* Evaluate a model by RMSE, and plot the cumulative error.
* Support for creating rolling forecasts.
## Installation
``pip install timetomodel``
## Example
Here is an example where we describe a solar time series problem, and use ``statsmodels.OLS``, a linear regression model, to forecast one hour ahead:
import pandas as pd
import pytz
from datetime import datetime, timedelta
from statsmodels.api import OLS
from timetomodel import speccing, ModelState, create_fitted_model, evaluate_models
from timetomodel.transforming import BoxCoxTransformation
from timetomodel.forecasting import make_rolling_forecasts
data_start = datetime(2015, 3, 1, tzinfo=pytz.utc)
data_end = datetime(2015, 10, 31, tzinfo=pytz.utc)
#### Solar model - 1h ahead ####
# spec outcome variable
solar_outcome_var_spec = speccing.CSVFileSeriesSpecs(
file_path="data.csv",
time_column="datetime",
value_column="solar_power",
name="solar power",
feature_transformation=BoxCoxTransformation(lambda2=0.1)
)
# spec regressor variable
regressor_spec_1h = speccing.CSVFileSeriesSpecs(
file_path="data.csv",
time_column="datetime",
value_column="irradiation_forecast1h",
name="irradiation forecast",
feature_transformation=BoxCoxTransformation(lambda2=0.1)
)
# spec whole model treatment
solar_model1h_specs = speccing.ModelSpecs(
outcome_var=solar_outcome_var_spec,
model=OLS,
frequency=timedelta(minutes=15),
horizon=timedelta(hours=1),
lags=[lag * 96 for lag in range(1, 8)], # 7 days (data has daily seasonality)
regressors=[regressor_spec_1h],
start_of_training=data_start + timedelta(days=30),
end_of_testing=data_end,
ratio_training_testing_data=2/3,
remodel_frequency=timedelta(days=14) # re-train model every two weeks
)
solar_model1h = create_fitted_model(solar_model1h_specs, "Linear Regression Solar Horizon 1h")
# solar_model_1h is now an OLS model object which can be pickled and re-used.
# With the solar_model1h_specs in hand, your production code could always re-train a new one,
# if the model has become outdated.
# For data scientists: evaluate model
evaluate_models(m1=ModelState(solar_model1h, solar_model1h_specs))
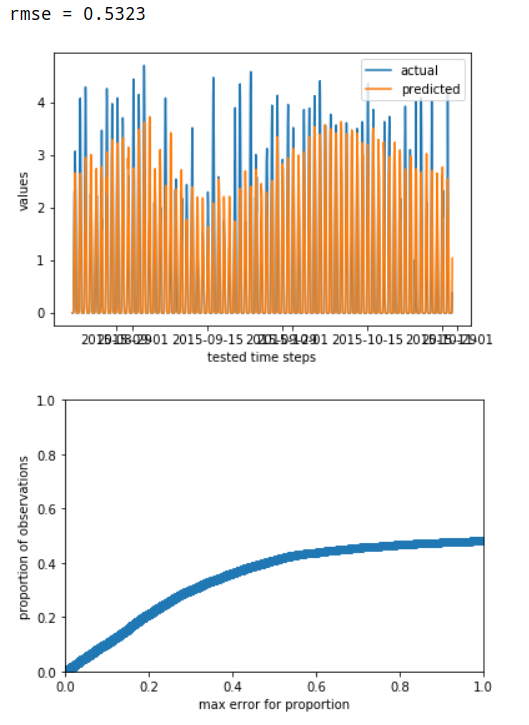
# For engineers a): Change data sources to use database (hinted)
solar_model1h_specs.outcome_var = speccing.DBSeriesSpecs(query=...)
solar_model1h_specs.regressors[0] = speccing.DBSeriesSpecs(query=...)
# For engineers b): Use model to make forecasts for an hour
forecasts, model_state = make_rolling_forecasts(
start=datetime(2015, 11, 1, tzinfo=pytz.utc),
end=datetime(2015, 11, 1, 1, tzinfo=pytz.utc),
model_specs=solar_model1h_specs
)
# model_state might have re-trained a new model automatically, by honoring the remodel_frequency
%package -n python3-timetomodel
Summary: Sane handling of time series data for forecast modelling - with production usage in mind.
Provides: python-timetomodel
BuildRequires: python3-devel
BuildRequires: python3-setuptools
BuildRequires: python3-pip
%description -n python3-timetomodel
# timetomodel
Time series forecasting is a modern data science & engineering challenge.
We noticed that these two worlds, data science and engineering of time series forecasting, are not very compatible.
Often, work from the data scientist has to be re-implemented by engineers to be used in production.
`timetomodel` was created to change that. It describes the data treatment of a model, and also automates common data treatment tasks like building data for training and testing.
As a *data scientist*, experiment with a model in your notebook.
Load data from static files (e.g. CSV) and try out lags, regressors and so on.
Compare plots and mean square errors of the models you developed.
As an *engineer*, take over the model description and use it in your production code.
Often, this would entail not much more than changing the data source (e.g from CSV to a column in the database).
`timetomodel` is supposed to wrap around any fit/predict type model, e.g. from statsmodels or scikit-learn (some work needed here to ensure support).
## Features
Here are some features for both data scientists and engineers to enjoy:
* Describe how to load data for outcome and regressor variables. Load from Pandas objects, CSV files, Pandas pickles or databases via SQLAlchemy.
* Create train & test data, including lags.
* Timezone awareness support.
* Custom data transformations, after loading (e.g. to remove duplicate) or only for forecasting (e.g. to apply a BoxCox transformation).
* Evaluate a model by RMSE, and plot the cumulative error.
* Support for creating rolling forecasts.
## Installation
``pip install timetomodel``
## Example
Here is an example where we describe a solar time series problem, and use ``statsmodels.OLS``, a linear regression model, to forecast one hour ahead:
import pandas as pd
import pytz
from datetime import datetime, timedelta
from statsmodels.api import OLS
from timetomodel import speccing, ModelState, create_fitted_model, evaluate_models
from timetomodel.transforming import BoxCoxTransformation
from timetomodel.forecasting import make_rolling_forecasts
data_start = datetime(2015, 3, 1, tzinfo=pytz.utc)
data_end = datetime(2015, 10, 31, tzinfo=pytz.utc)
#### Solar model - 1h ahead ####
# spec outcome variable
solar_outcome_var_spec = speccing.CSVFileSeriesSpecs(
file_path="data.csv",
time_column="datetime",
value_column="solar_power",
name="solar power",
feature_transformation=BoxCoxTransformation(lambda2=0.1)
)
# spec regressor variable
regressor_spec_1h = speccing.CSVFileSeriesSpecs(
file_path="data.csv",
time_column="datetime",
value_column="irradiation_forecast1h",
name="irradiation forecast",
feature_transformation=BoxCoxTransformation(lambda2=0.1)
)
# spec whole model treatment
solar_model1h_specs = speccing.ModelSpecs(
outcome_var=solar_outcome_var_spec,
model=OLS,
frequency=timedelta(minutes=15),
horizon=timedelta(hours=1),
lags=[lag * 96 for lag in range(1, 8)], # 7 days (data has daily seasonality)
regressors=[regressor_spec_1h],
start_of_training=data_start + timedelta(days=30),
end_of_testing=data_end,
ratio_training_testing_data=2/3,
remodel_frequency=timedelta(days=14) # re-train model every two weeks
)
solar_model1h = create_fitted_model(solar_model1h_specs, "Linear Regression Solar Horizon 1h")
# solar_model_1h is now an OLS model object which can be pickled and re-used.
# With the solar_model1h_specs in hand, your production code could always re-train a new one,
# if the model has become outdated.
# For data scientists: evaluate model
evaluate_models(m1=ModelState(solar_model1h, solar_model1h_specs))

# For engineers a): Change data sources to use database (hinted)
solar_model1h_specs.outcome_var = speccing.DBSeriesSpecs(query=...)
solar_model1h_specs.regressors[0] = speccing.DBSeriesSpecs(query=...)
# For engineers b): Use model to make forecasts for an hour
forecasts, model_state = make_rolling_forecasts(
start=datetime(2015, 11, 1, tzinfo=pytz.utc),
end=datetime(2015, 11, 1, 1, tzinfo=pytz.utc),
model_specs=solar_model1h_specs
)
# model_state might have re-trained a new model automatically, by honoring the remodel_frequency
%package help
Summary: Development documents and examples for timetomodel
Provides: python3-timetomodel-doc
%description help
# timetomodel
Time series forecasting is a modern data science & engineering challenge.
We noticed that these two worlds, data science and engineering of time series forecasting, are not very compatible.
Often, work from the data scientist has to be re-implemented by engineers to be used in production.
`timetomodel` was created to change that. It describes the data treatment of a model, and also automates common data treatment tasks like building data for training and testing.
As a *data scientist*, experiment with a model in your notebook.
Load data from static files (e.g. CSV) and try out lags, regressors and so on.
Compare plots and mean square errors of the models you developed.
As an *engineer*, take over the model description and use it in your production code.
Often, this would entail not much more than changing the data source (e.g from CSV to a column in the database).
`timetomodel` is supposed to wrap around any fit/predict type model, e.g. from statsmodels or scikit-learn (some work needed here to ensure support).
## Features
Here are some features for both data scientists and engineers to enjoy:
* Describe how to load data for outcome and regressor variables. Load from Pandas objects, CSV files, Pandas pickles or databases via SQLAlchemy.
* Create train & test data, including lags.
* Timezone awareness support.
* Custom data transformations, after loading (e.g. to remove duplicate) or only for forecasting (e.g. to apply a BoxCox transformation).
* Evaluate a model by RMSE, and plot the cumulative error.
* Support for creating rolling forecasts.
## Installation
``pip install timetomodel``
## Example
Here is an example where we describe a solar time series problem, and use ``statsmodels.OLS``, a linear regression model, to forecast one hour ahead:
import pandas as pd
import pytz
from datetime import datetime, timedelta
from statsmodels.api import OLS
from timetomodel import speccing, ModelState, create_fitted_model, evaluate_models
from timetomodel.transforming import BoxCoxTransformation
from timetomodel.forecasting import make_rolling_forecasts
data_start = datetime(2015, 3, 1, tzinfo=pytz.utc)
data_end = datetime(2015, 10, 31, tzinfo=pytz.utc)
#### Solar model - 1h ahead ####
# spec outcome variable
solar_outcome_var_spec = speccing.CSVFileSeriesSpecs(
file_path="data.csv",
time_column="datetime",
value_column="solar_power",
name="solar power",
feature_transformation=BoxCoxTransformation(lambda2=0.1)
)
# spec regressor variable
regressor_spec_1h = speccing.CSVFileSeriesSpecs(
file_path="data.csv",
time_column="datetime",
value_column="irradiation_forecast1h",
name="irradiation forecast",
feature_transformation=BoxCoxTransformation(lambda2=0.1)
)
# spec whole model treatment
solar_model1h_specs = speccing.ModelSpecs(
outcome_var=solar_outcome_var_spec,
model=OLS,
frequency=timedelta(minutes=15),
horizon=timedelta(hours=1),
lags=[lag * 96 for lag in range(1, 8)], # 7 days (data has daily seasonality)
regressors=[regressor_spec_1h],
start_of_training=data_start + timedelta(days=30),
end_of_testing=data_end,
ratio_training_testing_data=2/3,
remodel_frequency=timedelta(days=14) # re-train model every two weeks
)
solar_model1h = create_fitted_model(solar_model1h_specs, "Linear Regression Solar Horizon 1h")
# solar_model_1h is now an OLS model object which can be pickled and re-used.
# With the solar_model1h_specs in hand, your production code could always re-train a new one,
# if the model has become outdated.
# For data scientists: evaluate model
evaluate_models(m1=ModelState(solar_model1h, solar_model1h_specs))

# For engineers a): Change data sources to use database (hinted)
solar_model1h_specs.outcome_var = speccing.DBSeriesSpecs(query=...)
solar_model1h_specs.regressors[0] = speccing.DBSeriesSpecs(query=...)
# For engineers b): Use model to make forecasts for an hour
forecasts, model_state = make_rolling_forecasts(
start=datetime(2015, 11, 1, tzinfo=pytz.utc),
end=datetime(2015, 11, 1, 1, tzinfo=pytz.utc),
model_specs=solar_model1h_specs
)
# model_state might have re-trained a new model automatically, by honoring the remodel_frequency
%prep
%autosetup -n timetomodel-0.7.3
%build
%py3_build
%install
%py3_install
install -d -m755 %{buildroot}/%{_pkgdocdir}
if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi
if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi
if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi
if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi
pushd %{buildroot}
if [ -d usr/lib ]; then
find usr/lib -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
if [ -d usr/lib64 ]; then
find usr/lib64 -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
if [ -d usr/bin ]; then
find usr/bin -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
if [ -d usr/sbin ]; then
find usr/sbin -type f -printf "\"/%h/%f\"\n" >> filelist.lst
fi
touch doclist.lst
if [ -d usr/share/man ]; then
find usr/share/man -type f -printf "\"/%h/%f.gz\"\n" >> doclist.lst
fi
popd
mv %{buildroot}/filelist.lst .
mv %{buildroot}/doclist.lst .
%files -n python3-timetomodel -f filelist.lst
%dir %{python3_sitelib}/*
%files help -f doclist.lst
%{_docdir}/*
%changelog
* Tue Jun 20 2023 Python_Bot <Python_Bot@openeuler.org> - 0.7.3-1
- Package Spec generated
|
