1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
|
%global _empty_manifest_terminate_build 0
Name: python-vaex
Version: 4.16.0
Release: 1
Summary: Out-of-Core DataFrames to visualize and explore big tabular datasets
License: MIT
URL: https://www.github.com/vaexio/vaex
Source0: https://mirrors.nju.edu.cn/pypi/web/packages/62/fd/061dcce6ee7211f32b28aa6b49f8a19ece9619535b43ee3171b25c001711/vaex-4.16.0.tar.gz
BuildArch: noarch
Requires: python3-vaex-core
Requires: python3-vaex-astro
Requires: python3-vaex-hdf5
Requires: python3-vaex-viz
Requires: python3-vaex-server
Requires: python3-vaex-jupyter
Requires: python3-vaex-ml
%description
[](https://docs.vaex.io)
[](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ)
# What is Vaex?
Vaex is a high performance Python library for lazy **Out-of-Core DataFrames**
(similar to Pandas), to visualize and explore big tabular datasets. It
calculates *statistics* such as mean, sum, count, standard deviation etc, on an
*N-dimensional grid* for more than **a billion** (`10^9`) samples/rows **per
second**. Visualization is done using **histograms**, **density plots** and **3d
volume rendering**, allowing interactive exploration of big data. Vaex uses
memory mapping, zero memory copy policy and lazy computations for best
performance (no memory wasted).
# Installing
With pip:
```
$ pip install vaex
```
Or conda:
```
$ conda install -c conda-forge vaex
```
[For more details, see the documentation](https://docs.vaex.io/en/latest/installing.html)
# Key features
## Instant opening of Huge data files (memory mapping)
[HDF5](https://en.wikipedia.org/wiki/Hierarchical_Data_Format) and [Apache Arrow](https://arrow.apache.org/) supported.

[Read the documentation on how to efficiently convert your data](https://docs.vaex.io/en/latest/example_io.html) from CSV files, Pandas DataFrames, or other sources.
Lazy streaming from S3 supported in combination with memory mapping.

## Expression system
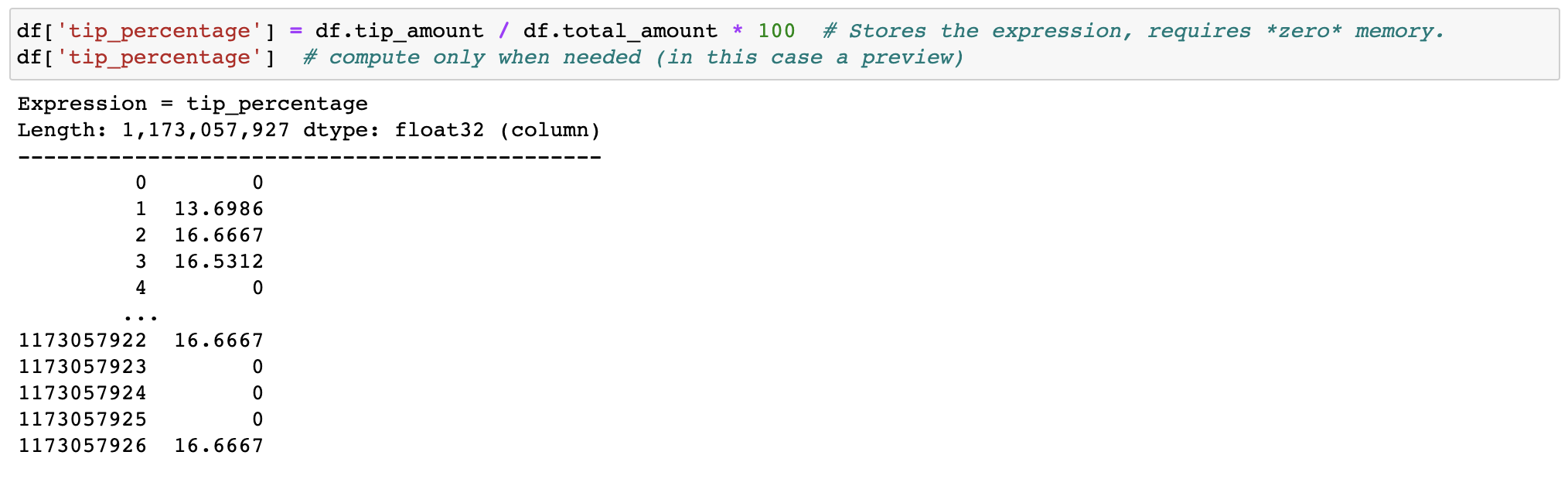
Don't waste memory or time with feature engineering, we (lazily) transform your data when needed.
## Out-of-core DataFrame
Filtering and evaluating expressions will not waste memory by making copies; the data is kept untouched on disk, and will be streamed only when needed. Delay the time before you need a cluster.

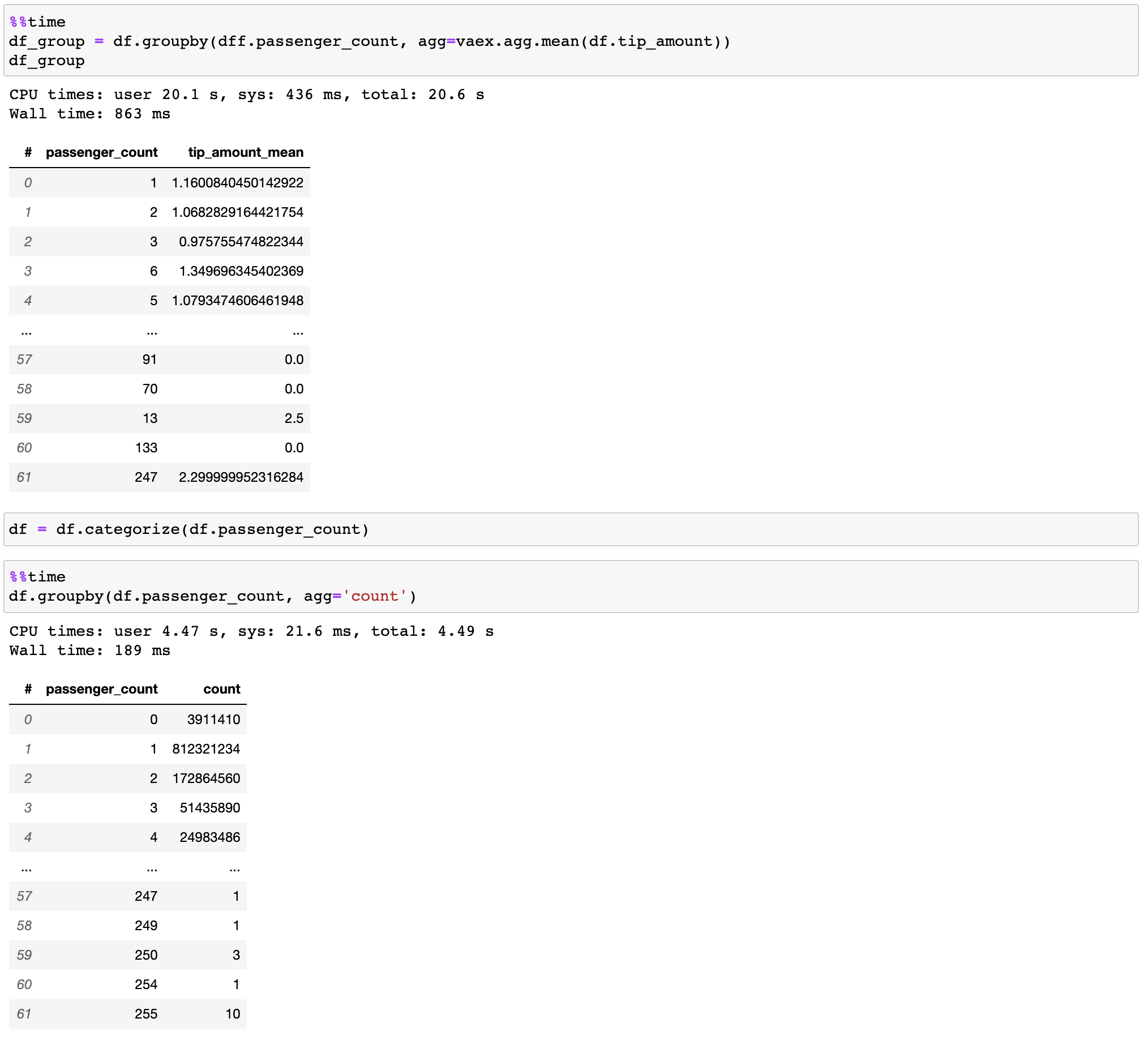
## Fast groupby / aggregations
Vaex implements parallelized, highly performant `groupby` operations, especially when using categories (>1 billion/second).
## Fast and efficient join
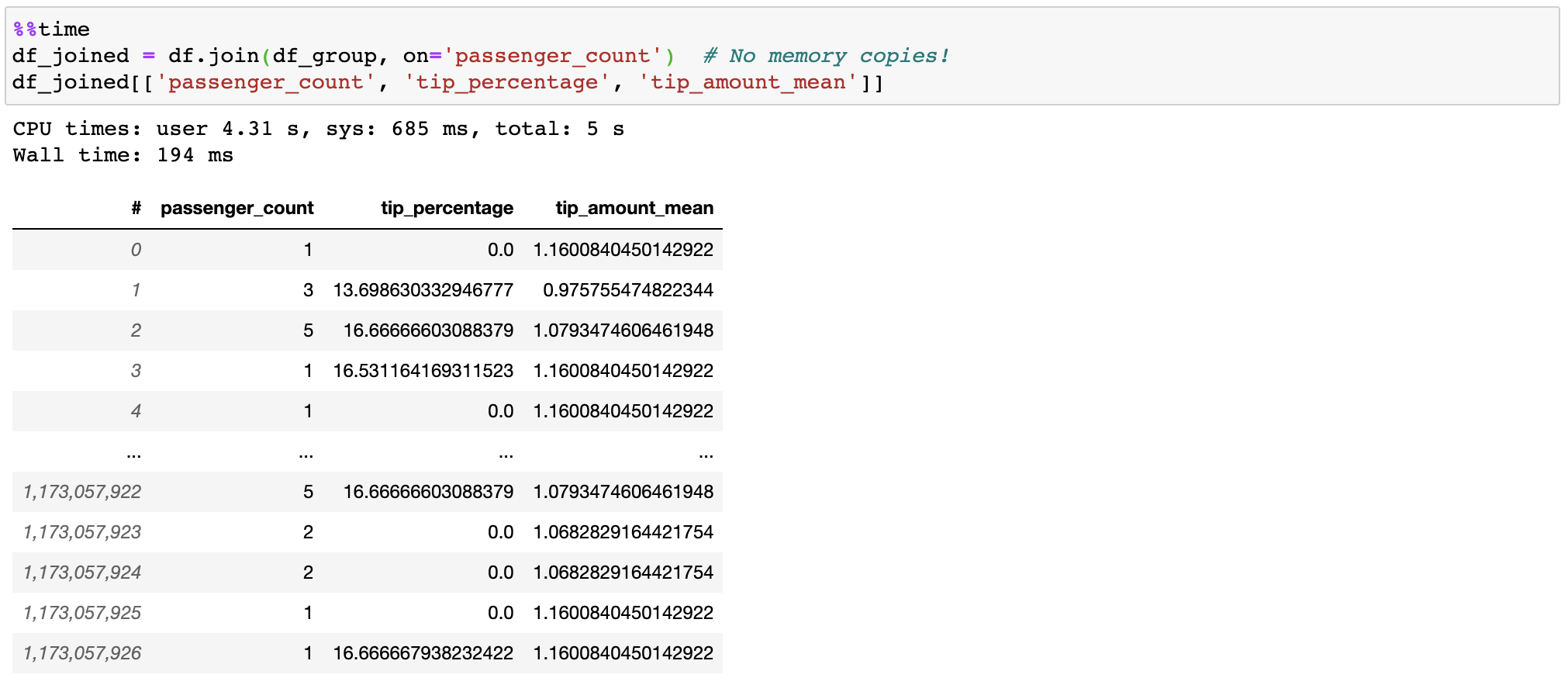
Vaex doesn't copy/materialize the 'right' table when joining, saving gigabytes of memory. With subsecond joining on a billion rows, it's pretty fast!
## More features
* Remote DataFrames (documentation coming soon)
* Integration into [Jupyter and Voila for interactive notebooks and dashboards](https://vaex.readthedocs.io/en/latest/tutorial_jupyter.html)
* [Machine Learning without (explicit) pipelines](https://vaex.readthedocs.io/en/latest/tutorial_ml.html)
## Contributing
See [contributing](CONTRIBUTING.md) page.
## Slack
Join the discussion in our [Slack](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ) channel!
# Learn more about Vaex
* Articles
* [Beyond Pandas: Spark, Dask, Vaex and other big data technologies battling head to head](https://towardsdatascience.com/beyond-pandas-spark-dask-vaex-and-other-big-data-technologies-battling-head-to-head-a453a1f8cc13) (includes benchmarks)
* [7 reasons why I love Vaex for data science](https://towardsdatascience.com/7-reasons-why-i-love-vaex-for-data-science-99008bc8044b) (tips and trics)
* [ML impossible: Train 1 billion samples in 5 minutes on your laptop using Vaex and Scikit-Learn](https://towardsdatascience.com/ml-impossible-train-a-1-billion-sample-model-in-20-minutes-with-vaex-and-scikit-learn-on-your-9e2968e6f385)
* [How to analyse 100 GB of data on your laptop with Python](https://towardsdatascience.com/how-to-analyse-100s-of-gbs-of-data-on-your-laptop-with-python-f83363dda94)
* [Flying high with Vaex: analysis of over 30 years of flight data in Python](https://towardsdatascience.com/https-medium-com-jovan-veljanoski-flying-high-with-vaex-analysis-of-over-30-years-of-flight-data-in-python-b224825a6d56)
* [Vaex: A DataFrame with super strings - Speed up your text processing up to a 1000x
](https://towardsdatascience.com/vaex-a-dataframe-with-super-strings-789b92e8d861)
* [Vaex: Out of Core Dataframes for Python and Fast Visualization - 1 billion row datasets on your laptop](https://towardsdatascience.com/vaex-out-of-core-dataframes-for-python-and-fast-visualization-12c102db044a)
* [Follow our tutorials](https://docs.vaex.io/en/latest/tutorials.html)
* Watch our more recent talks:
* [PyData London 2019](https://www.youtube.com/watch?v=2Tt0i823-ec)
* [SciPy 2019](https://www.youtube.com/watch?v=ELtjRdPT8is)
* Contact us for data science solutions, training, or enterprise support at https://vaex.io/
%package -n python3-vaex
Summary: Out-of-Core DataFrames to visualize and explore big tabular datasets
Provides: python-vaex
BuildRequires: python3-devel
BuildRequires: python3-setuptools
BuildRequires: python3-pip
%description -n python3-vaex
[](https://docs.vaex.io)
[](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ)
# What is Vaex?
Vaex is a high performance Python library for lazy **Out-of-Core DataFrames**
(similar to Pandas), to visualize and explore big tabular datasets. It
calculates *statistics* such as mean, sum, count, standard deviation etc, on an
*N-dimensional grid* for more than **a billion** (`10^9`) samples/rows **per
second**. Visualization is done using **histograms**, **density plots** and **3d
volume rendering**, allowing interactive exploration of big data. Vaex uses
memory mapping, zero memory copy policy and lazy computations for best
performance (no memory wasted).
# Installing
With pip:
```
$ pip install vaex
```
Or conda:
```
$ conda install -c conda-forge vaex
```
[For more details, see the documentation](https://docs.vaex.io/en/latest/installing.html)
# Key features
## Instant opening of Huge data files (memory mapping)
[HDF5](https://en.wikipedia.org/wiki/Hierarchical_Data_Format) and [Apache Arrow](https://arrow.apache.org/) supported.


[Read the documentation on how to efficiently convert your data](https://docs.vaex.io/en/latest/example_io.html) from CSV files, Pandas DataFrames, or other sources.
Lazy streaming from S3 supported in combination with memory mapping.

## Expression system
Don't waste memory or time with feature engineering, we (lazily) transform your data when needed.

## Out-of-core DataFrame
Filtering and evaluating expressions will not waste memory by making copies; the data is kept untouched on disk, and will be streamed only when needed. Delay the time before you need a cluster.

## Fast groupby / aggregations
Vaex implements parallelized, highly performant `groupby` operations, especially when using categories (>1 billion/second).

## Fast and efficient join
Vaex doesn't copy/materialize the 'right' table when joining, saving gigabytes of memory. With subsecond joining on a billion rows, it's pretty fast!

## More features
* Remote DataFrames (documentation coming soon)
* Integration into [Jupyter and Voila for interactive notebooks and dashboards](https://vaex.readthedocs.io/en/latest/tutorial_jupyter.html)
* [Machine Learning without (explicit) pipelines](https://vaex.readthedocs.io/en/latest/tutorial_ml.html)
## Contributing
See [contributing](CONTRIBUTING.md) page.
## Slack
Join the discussion in our [Slack](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ) channel!
# Learn more about Vaex
* Articles
* [Beyond Pandas: Spark, Dask, Vaex and other big data technologies battling head to head](https://towardsdatascience.com/beyond-pandas-spark-dask-vaex-and-other-big-data-technologies-battling-head-to-head-a453a1f8cc13) (includes benchmarks)
* [7 reasons why I love Vaex for data science](https://towardsdatascience.com/7-reasons-why-i-love-vaex-for-data-science-99008bc8044b) (tips and trics)
* [ML impossible: Train 1 billion samples in 5 minutes on your laptop using Vaex and Scikit-Learn](https://towardsdatascience.com/ml-impossible-train-a-1-billion-sample-model-in-20-minutes-with-vaex-and-scikit-learn-on-your-9e2968e6f385)
* [How to analyse 100 GB of data on your laptop with Python](https://towardsdatascience.com/how-to-analyse-100s-of-gbs-of-data-on-your-laptop-with-python-f83363dda94)
* [Flying high with Vaex: analysis of over 30 years of flight data in Python](https://towardsdatascience.com/https-medium-com-jovan-veljanoski-flying-high-with-vaex-analysis-of-over-30-years-of-flight-data-in-python-b224825a6d56)
* [Vaex: A DataFrame with super strings - Speed up your text processing up to a 1000x
](https://towardsdatascience.com/vaex-a-dataframe-with-super-strings-789b92e8d861)
* [Vaex: Out of Core Dataframes for Python and Fast Visualization - 1 billion row datasets on your laptop](https://towardsdatascience.com/vaex-out-of-core-dataframes-for-python-and-fast-visualization-12c102db044a)
* [Follow our tutorials](https://docs.vaex.io/en/latest/tutorials.html)
* Watch our more recent talks:
* [PyData London 2019](https://www.youtube.com/watch?v=2Tt0i823-ec)
* [SciPy 2019](https://www.youtube.com/watch?v=ELtjRdPT8is)
* Contact us for data science solutions, training, or enterprise support at https://vaex.io/
%package help
Summary: Development documents and examples for vaex
Provides: python3-vaex-doc
%description help
[](https://docs.vaex.io)
[](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ)
# What is Vaex?
Vaex is a high performance Python library for lazy **Out-of-Core DataFrames**
(similar to Pandas), to visualize and explore big tabular datasets. It
calculates *statistics* such as mean, sum, count, standard deviation etc, on an
*N-dimensional grid* for more than **a billion** (`10^9`) samples/rows **per
second**. Visualization is done using **histograms**, **density plots** and **3d
volume rendering**, allowing interactive exploration of big data. Vaex uses
memory mapping, zero memory copy policy and lazy computations for best
performance (no memory wasted).
# Installing
With pip:
```
$ pip install vaex
```
Or conda:
```
$ conda install -c conda-forge vaex
```
[For more details, see the documentation](https://docs.vaex.io/en/latest/installing.html)
# Key features
## Instant opening of Huge data files (memory mapping)
[HDF5](https://en.wikipedia.org/wiki/Hierarchical_Data_Format) and [Apache Arrow](https://arrow.apache.org/) supported.


[Read the documentation on how to efficiently convert your data](https://docs.vaex.io/en/latest/example_io.html) from CSV files, Pandas DataFrames, or other sources.
Lazy streaming from S3 supported in combination with memory mapping.

## Expression system
Don't waste memory or time with feature engineering, we (lazily) transform your data when needed.

## Out-of-core DataFrame
Filtering and evaluating expressions will not waste memory by making copies; the data is kept untouched on disk, and will be streamed only when needed. Delay the time before you need a cluster.

## Fast groupby / aggregations
Vaex implements parallelized, highly performant `groupby` operations, especially when using categories (>1 billion/second).

## Fast and efficient join
Vaex doesn't copy/materialize the 'right' table when joining, saving gigabytes of memory. With subsecond joining on a billion rows, it's pretty fast!

## More features
* Remote DataFrames (documentation coming soon)
* Integration into [Jupyter and Voila for interactive notebooks and dashboards](https://vaex.readthedocs.io/en/latest/tutorial_jupyter.html)
* [Machine Learning without (explicit) pipelines](https://vaex.readthedocs.io/en/latest/tutorial_ml.html)
## Contributing
See [contributing](CONTRIBUTING.md) page.
## Slack
Join the discussion in our [Slack](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ) channel!
# Learn more about Vaex
* Articles
* [Beyond Pandas: Spark, Dask, Vaex and other big data technologies battling head to head](https://towardsdatascience.com/beyond-pandas-spark-dask-vaex-and-other-big-data-technologies-battling-head-to-head-a453a1f8cc13) (includes benchmarks)
* [7 reasons why I love Vaex for data science](https://towardsdatascience.com/7-reasons-why-i-love-vaex-for-data-science-99008bc8044b) (tips and trics)
* [ML impossible: Train 1 billion samples in 5 minutes on your laptop using Vaex and Scikit-Learn](https://towardsdatascience.com/ml-impossible-train-a-1-billion-sample-model-in-20-minutes-with-vaex-and-scikit-learn-on-your-9e2968e6f385)
* [How to analyse 100 GB of data on your laptop with Python](https://towardsdatascience.com/how-to-analyse-100s-of-gbs-of-data-on-your-laptop-with-python-f83363dda94)
* [Flying high with Vaex: analysis of over 30 years of flight data in Python](https://towardsdatascience.com/https-medium-com-jovan-veljanoski-flying-high-with-vaex-analysis-of-over-30-years-of-flight-data-in-python-b224825a6d56)
* [Vaex: A DataFrame with super strings - Speed up your text processing up to a 1000x
](https://towardsdatascience.com/vaex-a-dataframe-with-super-strings-789b92e8d861)
* [Vaex: Out of Core Dataframes for Python and Fast Visualization - 1 billion row datasets on your laptop](https://towardsdatascience.com/vaex-out-of-core-dataframes-for-python-and-fast-visualization-12c102db044a)
* [Follow our tutorials](https://docs.vaex.io/en/latest/tutorials.html)
* Watch our more recent talks:
* [PyData London 2019](https://www.youtube.com/watch?v=2Tt0i823-ec)
* [SciPy 2019](https://www.youtube.com/watch?v=ELtjRdPT8is)
* Contact us for data science solutions, training, or enterprise support at https://vaex.io/
%prep
%autosetup -n vaex-4.16.0
%build
%py3_build
%install
%py3_install
install -d -m755 %{buildroot}/%{_pkgdocdir}
if [ -d doc ]; then cp -arf doc %{buildroot}/%{_pkgdocdir}; fi
if [ -d docs ]; then cp -arf docs %{buildroot}/%{_pkgdocdir}; fi
if [ -d example ]; then cp -arf example %{buildroot}/%{_pkgdocdir}; fi
if [ -d examples ]; then cp -arf examples %{buildroot}/%{_pkgdocdir}; fi
pushd %{buildroot}
if [ -d usr/lib ]; then
find usr/lib -type f -printf "/%h/%f\n" >> filelist.lst
fi
if [ -d usr/lib64 ]; then
find usr/lib64 -type f -printf "/%h/%f\n" >> filelist.lst
fi
if [ -d usr/bin ]; then
find usr/bin -type f -printf "/%h/%f\n" >> filelist.lst
fi
if [ -d usr/sbin ]; then
find usr/sbin -type f -printf "/%h/%f\n" >> filelist.lst
fi
touch doclist.lst
if [ -d usr/share/man ]; then
find usr/share/man -type f -printf "/%h/%f.gz\n" >> doclist.lst
fi
popd
mv %{buildroot}/filelist.lst .
mv %{buildroot}/doclist.lst .
%files -n python3-vaex -f filelist.lst
%dir %{python3_sitelib}/*
%files help -f doclist.lst
%{_docdir}/*
%changelog
* Sun Apr 23 2023 Python_Bot <Python_Bot@openeuler.org> - 4.16.0-1
- Package Spec generated
|
